빅데이터 분석
• R
–SAS, SPSS의 대안
– 오픈소스, 최신 기술 적용
• Hadoop
– 대용량 데이터를 위한 파일 시스템
– 분산 컴퓨팅 프레임워크
– (비교적) 검증된 기술
• R + Hadoop
– R의 분석 능력, Visualization 능력
– Hadoop의 대용량 데이터 처리 능력
6.
R + Hadoop= ?
• Iterative vs. batch processing
• In-memory vs. in parallel
7.
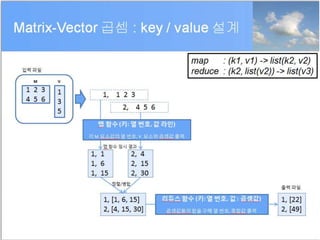
R + Hadoop=
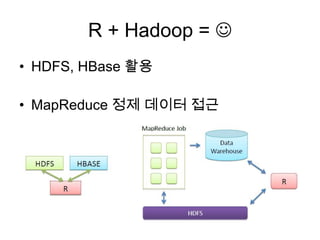
• HDFS, HBase 활용
• MapReduce 정제 데이터 접근
8.
R + Hadoop=
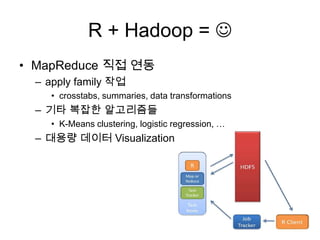
• MapReduce 직접 연동
– apply family 작업
• crosstabs, summaries, data transformations
– 기타 복잡한 알고리즘들
• K-Means clustering, logistic regression, …
– 대용량 데이터 Visualization
9.
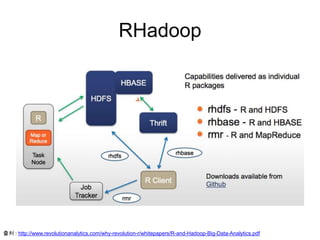
RHadoop
• Collection ofthree R packages that allow users
to manage and analyze data with Hadoop.
• RHadoop consists of the following packages:
– rmr - functions providing Hadoop MapReduce
functionality in R
– rhdfs - functions providing file management of the
HDFS from within R
– rhbase - functions providing database management
for the HBase distributed database from within R
RHadoop의 장점
• 기존의데이터 분석가도 Big Data 처리 가능
• 분석 결과 향상
– 간단한 모델 + 대용량 데이터
– 복잡한 모델 + 적은 데이터
• 벤더 종속성 탈피
12.
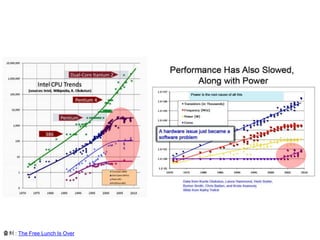
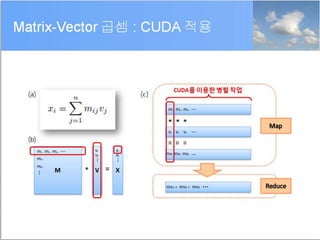
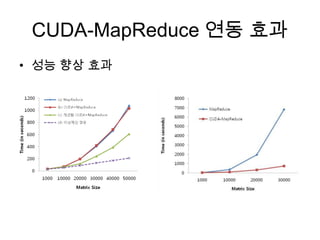
1.2 계산 집약적연산
• Data Intensive & Compute Intensive computation
• 대용량 데이터에 대해 계산 집약적 연산의 수행이 필요할 경우 Hadoop과
CUDA를 활용하여 빠르게 처리할 수 있다.
• Linear Algebra 연산 적용 시 문제점과 개선 방안
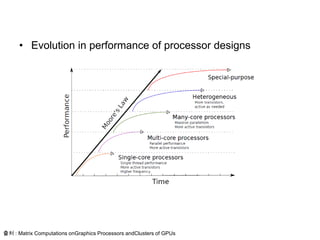
• Evolution inperformance of processor designs
출처 : Matrix Computations onGraphics Processors andClusters of GPUs
17.
CUDA
• Compute UnifiedDevice Architecture
– NVIDIA’s parallel computing architecture
– computing engine in Nvidia graphics processing units
(GPUs) that is accessible to software developers
through variants of industry standard programming
languages.
• GPU를 이용한 범용적인 프로그램을 개발할 수 있
도록 ‘프로그램 모델’, ‘프로그램 언어’, ‘컴파일러’,
‘라이브러리’, ‘디버거’, ‘프로파일러’를 제공하는 통
합 환경
출처 : http://en.wikipedia.org/wiki/CUDA
18.
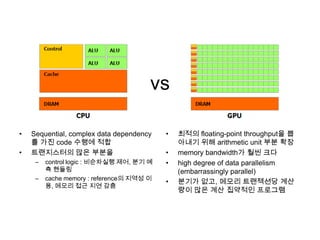
vs
• Sequential, complexdata dependency
를 가진 code 수행에 적합
• 트랜지스터의 많은 부분을
– control logic : 비순차실행 제어, 분기 예
측 핸들링
– cache memory : reference의 지역성 이
용, 메모리 접근 지연 감춤
• 최적의 floating-point throughput을 뽑
아내기 위해 arithmetic unit 부분 확장
• memory bandwidth가 훨씬 크다
• high degree of data parallelism
(embarrassingly parallel)
• 분기가 없고, 메모리 트랜젝션당 계산
량이 많은 계산 집약적인 프로그램
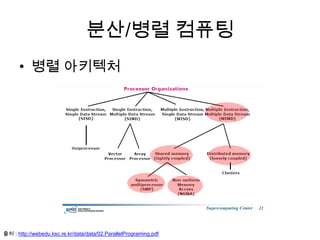
분산/병렬 컴퓨팅
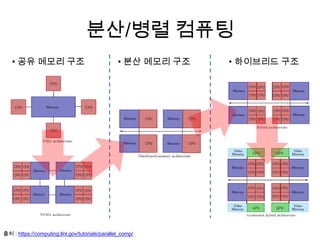
출처 :https://computing.llnl.gov/tutorials/parallel_comp/
• 공유 메모리 구조 • 분산 메모리 구조 • 하이브리드 구조
22.
병렬 프로그래밍 모델
•공유메모리 병렬 프로그래밍 모델
– 공유 메모리 아키텍처에 적합
– 다중 스레드 프로그램
– OpenMP, Pthreads
• 메시지 패싱 병렬 프로그래밍 모델
– 분산 메모리 아키텍처에 적합
– MPI, PVM
• 하이브리드 병렬 프로그래밍 모델
– 분산-공유 메모리 아키텍처
– OpenMP + MPI
23.
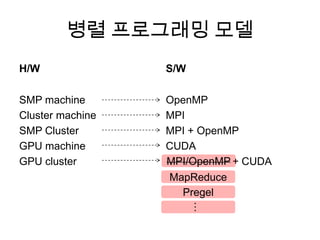
병렬 프로그래밍 모델
H/W
SMPmachine
Cluster machine
SMP Cluster
GPU machine
GPU cluster
S/W
OpenMP
MPI
MPI + OpenMP
CUDA
MPI/OpenMP + CUDAMPI/OpenMP
MapReduce
Pregel…
1.4 복잡한 분석로직 구현
• 대용량 데이터에서 가치 있는 정보를 얻기 위해 Hadoop을 이용하여 각종 기
계학습 알고리즘을 구현할 수 있다.
• Hadoop, Mahout을 이용하여 간단한 추천 시스템을 구현할 수 있다.
37.
분석 기반 기술
•데이터분석 : 축적된 대량의 데이터를 다양한 형태로 가공하여
업무에 숨어있는 과제와 문제점을 밝히고, 과제와 문제점의 요
인을 분석해서 대책을 세우고 개선하는 활동을 말한다.
• 데이터마이닝 : 데이터 마이닝은 데이터를 분석해서 패턴을 발
견하고 예측 모델을 만드는 자동화된 프로세스다. 수학, 통계,
기계학습 등 다양한 연구 영역에 기초를 두고 있다.
• 기계학습 : 컴퓨터가 스스로 학습하게 하는 알고리즘에 관련된
인공지능의 한 영역. 주어진 데이터의 집합(트레이닝 데이터)
을 이용해서 데이터의 속성에 관한 정보를 추론하는 알고리즘
이다. 이 정보를 이용하여 미래에 발견될 다른 데이터(테스트
데이터)에 관한 예측이 가능
38.
용어 정리
• 데이터분석 : 이미 알려진 모델에 데이터가 적합한지를
다루는 개념
– 데이터의 조회, 요약, 경향 분석하는 작업
– 리포팅, OLAP 등
• 데이터 마이닝 : 데이터를 분석해서 이전에 알려지지 않은
패턴이나 모델을 발굴하는데 목적을 둠.
• 둘 다 비즈니스 인텔리전스의 분야다.
Clustering
• Cluster
– Object들의 집합
– 비슷한 object끼리 같은 cluster에 묶음
• Clustering Algorithm
– 개체 (object) 집합을 여러 개의 group 으로 묶는 알고
리즘
• Requirements for Clustering Task
a.개체를 벡터로 표현할 feature 를 정의
b.두 개체의 가까운 정도를 측정할 measure를 정의
c.클러스터링을 수행할 알고리즘을 정의
44.
Clustering
• Clustering
– Vectordistance는 최대한 가깝게
– Cluster distance는 최대한 멀게
Vector
Distance
(between vectors)
Distance
(between clusters)
Cluster
45.
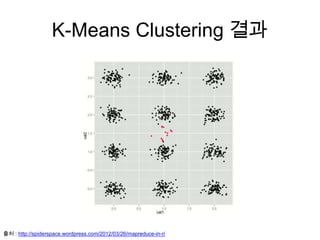
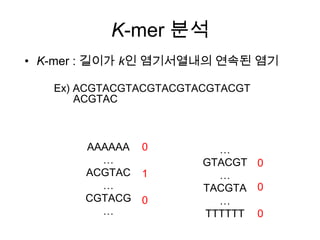
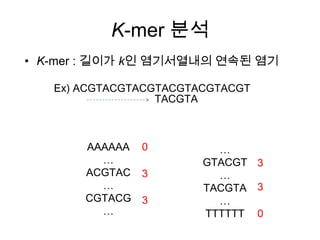
K-Means Clustering
• 주어진데이터를 k개의 클러스터로 묶는 알고리즘
• 각 클러스터와 거리 차이의 분산을 최소화 하는 방식으로 동작
• 즉, 주어진 데이터를 가장 거리가 가까운 것들끼리 k개의 클러스터로
군집하여 모든 데이터와 해당 클러스터의 centroid와의 거리합이 최
소가 되도록 반복연산
• 초기 seed는 랜덤하게 선택하여도 반복연산(iteration) 과정에서 어느
정도 적절한 중심값을 찾아가게 되지만 항상 옳지는 않으므로
canopy와 같은 rough한 알고리즘을 사용하거나 휴리스틱하게 초기
값을 선정함
• 클러스터 수 k와 수렴 임계값을 사용자가 결정해 주어야 하며 모든 데
이터는 단 하나의 클러스터에만 소속될 수 있음.
46.
K-Means Clustering
1) 모든D의 엘리먼트에 대해서 주어진 초기 seed 중 가
장 가까운 것을 찾고 추가
2) Seed C를 소속된 엘리먼트들의 평균으로 업데이트
3) C와 소속 엘리먼트들과의 거리의 합이 수렴임계값(th)
보다 작을 때까지 반복
given, dataSet D(1,2,...n) & seed C(1,2,...,k) & convergence delta th
Repeat
1)For each D, find nearest centroid in C and Add to C
2)Update C (calculate new centroids)
3)sum over all distance between D and corresponding C
Until sum < th
47.
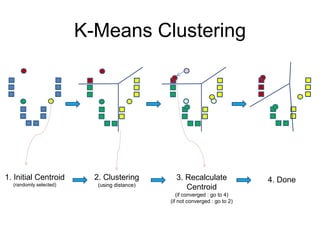
K-Means Clustering
1. InitialCentroid
(randomly selected)
2. Clustering
(using distance)
3. Recalculate
Centroid
(if converged : go to 4)
(if not converged : go to 2)
4. Done
48.
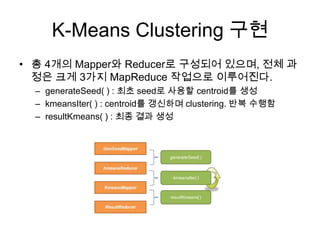
K-Means Clustering 구현
•총 4개의 Mapper와 Reducer로 구성되어 있으며, 전체 과
정은 크게 3가지 MapReduce 작업으로 이루어진다.
– generateSeed( ) : 최초 seed로 사용할 centroid를 생성
– kmeansIter( ) : centroid를 갱신하며 clustering. 반복 수행함
– resultKmeans( ) : 최종 결과 생성
Mahout
• Apache Mahoutis an Apache project to produce free
implementations of distributed or otherwise scalable
machine learning algorithms on the Hadoop platform.
- Wikipedia
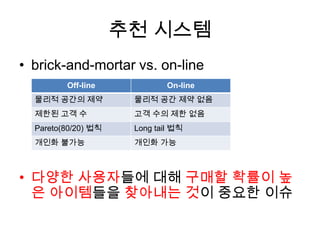
추천 시스템
• brick-and-mortarvs. on-line
• 다양한 사용자들에 대해 구매할 확률이 높
은 아이템들을 찾아내는 것이 중요한 이슈
Off-line On-line
물리적 공간의 제약 물리적 공간 제약 없음
제한된 고객 수 고객 수의 제한 없음
Pareto(80/20) 법칙 Long tail 법칙
개인화 불가능 개인화 가능
추천 시스템 분류
•Recommendation Systems
– 컨텐츠 기반(Content-based) system
– 협업 필터링(Collaborative filtering) system
• Memory-based
– User-based CF
– Item-based CF
• Model-based CF
• 일반적인 성능 및 결과 비교
Content-based < User-based CF <= Item-based CF < Model-based
61.
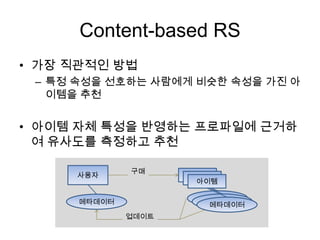
Content-based RS
• 가장직관적인 방법
– 특정 속성을 선호하는 사람에게 비슷한 속성을 가진 아
이템을 추천
• 아이템 자체 특성을 반영하는 프로파일에 근거하
여 유사도를 측정하고 추천
사용자 아이템아이템
메타데이터
아이템
메타데이터
구매
업데이트
62.
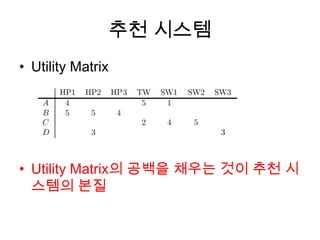
User Based CF
Concept
: 나와 비슷한 취향의 사람이 구매한 책 추천.
Flow
1) Data Model 생성
- User와 Item간의 Utility Matrix로 표현
2) User Similarity 계산
- User가 평가한 공통 Item을 기반으로 User간 유사도 계산
- Euclidean Distance, Jaccard Distance, Cosine Similarity 등
3) 선호도 예측 및 추천
- Query User 와 유사한 N-Neighbor 선택
- N-Neighbor와 Query User간의 유사도와 N-Neighbor가 선택한 Item
에 대한 선호도를 기반으로 Query User의 Item에 대한 선호도 예측
- 높은 점수를 받은 Item들을 Query User에게 추천
63.
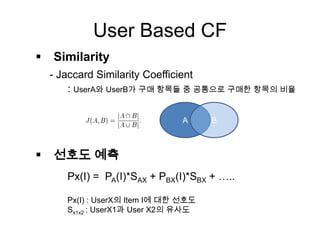
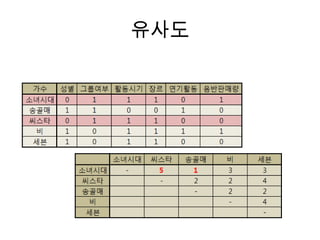
User Based CF
Similarity
- Jaccard Similarity Coefficient
: UserA와 UserB가 구매 항목들 중 공통으로 구매한 항목의 비율
선호도 예측
A B
Px(I) = PA(I)*SAX + PBX(I)*SBX + …..
Px(I) : UserX의 Item I에 대한 선호도
Sx1x2 : UserX1과 User X2의 유사도
1.5 도메인 특화기술 구현
• 대용량 CDR 데이터, SNS 사용자 데이터, e-mail 데이터 등을 이용하여 소셜
네트워크 분석을 수행할 수 있다.
• Bioinformatics 분야의 각종 알고리즘들이 대용량 데이터 처리를 위하여
Hadoop을 이용하고 있는 추세이다.
67.
CloudBurst
• CloudBurst :Highly Sensitive Short Read
Mapping with MapReduce
• New parallel read-mapping algorithm
optimized for mapping NGS data to the
human genome and other reference
genomes
• SNP discovery, genotyping, and personal
genomics
68.
CloudBurst
• It ismodeled after the short read mapping
program RMAP
• Reports either all alignments or the unambiguous
best alignment for each read with any number of
mismatches or differences
• This level of sensitivity could be prohibitively time
consuming, but CloudBurst uses the open-source
Hadoop implementation of MapReduce to
parallelize execution using multiple compute
nodes.
69.
CloudBurst
• Running time
–scales linearly with the number of reads mapped
– with near linear speedup as the number of
processors increases.
• CloudBurst reduces the running time from
hours to mere minutes for typical jobs
involving mapping of millions of short reads to
the human genome.
70.
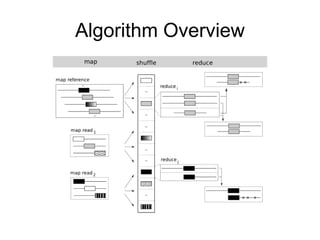
Algorithm Overview
• CloudBurstuses seed-and-extend algorithms to
map reads to a reference genome.
• Seed
– k differences : the alignment must have a region of
length s=r/k+1 called a seed that exactly matches the
reference.
• Extend
– CloudBurst attempts to extend the alignment into an
end-to-end alignment with at most k mismatches or
differences
71.
Algorithm Overview
• CloudBurstuses the Hadoop implementation of
MapReduce to catalog and extend the seeds
• Map phase emits
– all length-s k-mers from the reference sequences
– all non-overlapping length-s kmers from the reads
• Shuffle phase
– read and reference kmers are brought together
• Reduce phase
– the seeds are extended into end-to-end alignments















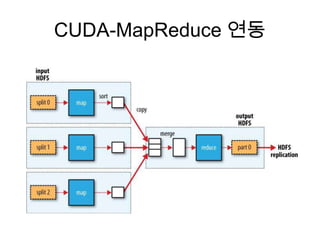
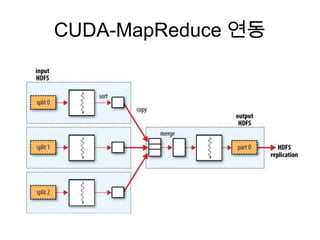
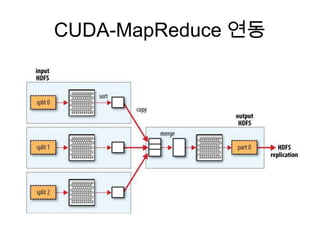









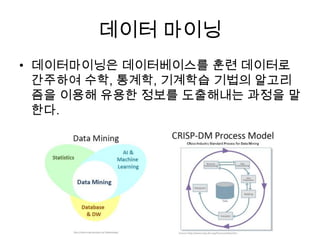

























![rhdfs (serialize)
# su - hadoop # RHadoop 패키지 테스트는 hadoop 계정으로
# export HADOOP_HOME=/home/hadoop/hadoop # 각자 환경에 맞게 수정
# export HADOOP_CONF=$HADOOP_HOME/conf
# export HADOOP_CMD=$HADOOP_HOME/bin/hadoop
# export HADOOP_STREAMING=$HADOOP_HOME/contrib/streaming/hadoop-streaming-<version>.jar
$ R
> library(rhdfs)
> hdfs.init()
Loading required package: rJava
HADOOP_HOME=/home/hadoop/hadoop
HADOOP_CONF=/home/hadoop/hadoop/conf
> model = lm(weight~height, women)
> model
> modelfilename <- "model_file"
> modelfile <- hdfs.file(modelfilename, "w")
> hdfs.write(model, modelfile)
[1] TRUE
> hdfs.close(modelfile)
[1] TRUE
> hdfs.ls('/user/hadoop')
permission owner group size modtime file
1 drwxr-xr-x hadoop supergroup 0 2012-06-04 15:53 /user/hadoop/input
2 -rw-r--r-- hadoop supergroup 3670 2012-06-04 18:36 /user/hadoop/model_file](https://image.slidesharecdn.com/5-mapreduce-130417213100-phpapp01/85/5-map-reduce-81-320.jpg)
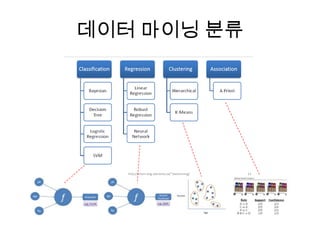
![rhdfs (deserialize)
$ R # hadoop 계정으로 R 실행
> library(rhdfs)
Loading required package: rJava
> modelfile = hdfs.file(modelfilename, "r")
> modelfile
DFS File: model_file [blocksize=67108864, replication=1, buffersize=5242880, mode='r']
> m <- hdfs.read(modelfile)
> model <- unserialize(m)
> model
> hdfs.close(modelfile)
[1] TRUE
> hdfs.delete('/user/hadoop/model_file')
Deleted hdfs://cudatest:9000/user/hadoop/model_file
[1] TRUE
> hdfs.ls('/user/hadoop')
permission owner group size modtime file
1 drwxr-xr-x hadoop supergroup 0 2012-06-04 15:53 /user/hadoop/input
>](https://image.slidesharecdn.com/5-mapreduce-130417213100-phpapp01/85/5-map-reduce-82-320.jpg)


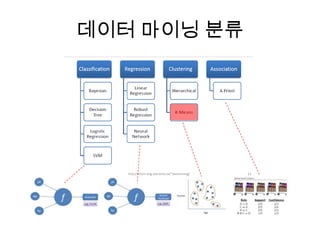
![rmr
> small.ints = to.dfs(1:10)
> out = mapreduce(input = small.ints, map = function(k,v) keyval(v, v^2))
Warning: $HADOOP_HOME is deprecated.
packageJobJar: [/tmp/RtmpKnwnj9/rhstr.map3fc53032703e, /tmp/RtmpKnwnj9/rmr-local-env,
/tmp/RtmpKnwnj9/rmr-global-env, /tmp/hadoop-root/hadoop-unjar3975456697311921286/] []
/tmp/streamjob3523992877229828328.jar tmpDir=null
12/06/01 22:54:15 INFO mapred.FileInputFormat: Total input paths to process : 1
12/06/01 22:54:16 INFO streaming.StreamJob: getLocalDirs(): [/tmp/hadoop-root/mapred/local]
12/06/01 22:54:16 INFO streaming.StreamJob: Running job: job_201206012240_0001
12/06/01 22:54:16 INFO streaming.StreamJob: To kill this job, run:
12/06/01 22:54:16 INFO streaming.StreamJob: /usr/local/hadoop/hadoop-1.0.2/libexec/../bin/hadoop job
-Dmapred.job.tracker=cudatest:9001 -kill job_201206012240_0001
12/06/01 22:54:16 INFO streaming.StreamJob: Tracking URL:
http://cudatest:50030/jobdetails.jsp?jobid=job_201206012240_0001
12/06/01 22:54:17 INFO streaming.StreamJob: map 0% reduce 0%
12/06/01 22:54:31 INFO streaming.StreamJob: map 100% reduce 0%
12/06/01 22:54:43 INFO streaming.StreamJob: map 100% reduce 100%
12/06/01 22:54:49 INFO streaming.StreamJob: Job complete: job_201206012240_0001
12/06/01 22:54:49 INFO streaming.StreamJob: Output: /tmp/RtmpKnwnj9/file3fc5272dca99
> result = from.dfs(out); result](https://image.slidesharecdn.com/5-mapreduce-130417213100-phpapp01/85/5-map-reduce-85-320.jpg)
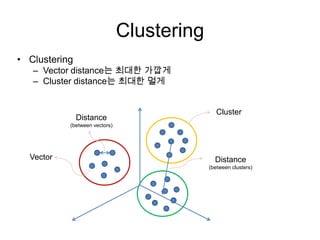
![Rhadoop 예제 (wordcount)
소스 코드
wordcount = function (input, output = NULL, pattern = " ") {
mapreduce(input = input ,
output = output,
input.format = "text",
map = function(k,v) {
lapply(
strsplit(
x = v,
split = pattern)[[1]],
function(w) keyval(w,1))},
reduce = function(k,vv) {
keyval(k, sum(unlist(vv)))}, combine = T)
}](https://image.slidesharecdn.com/5-mapreduce-130417213100-phpapp01/85/5-map-reduce-86-320.jpg)
![Rhadoop 예제 (wordcount)
> file = to.dfs("I saw a saw saw a saw in a saw.", format="text")
> out = wordcount(file)
packageJobJar: [/tmp/RtmpSJ73OT/rhstr.map1a0966bb8d5a,
/tmp/RtmpSJ73OT/rhstr.reduce1a09315feee9, /tmp/RtmpSJ73OT/rhstr.combine1a091a3a4826,
/tmp/RtmpSJ73OT/rmr-local-env, /tmp/RtmpSJ73OT/rmr-global-env, /tmp/hadoop-hadoop/hadoop-
unjar4399993970582808045/] [] /tmp/streamjob7923541988067611842.jar tmpDir=null
… 중략 …
12/06/04 18:16:48 INFO streaming.StreamJob: /usr/local/hadoop/hadoop-1.0.2/libexec/../bin/hadoop job
-Dmapred.job.tracker=cudatest:9001 -kill job_201206012240_0014
12/06/04 18:16:48 INFO streaming.StreamJob: Tracking URL:
http://cudatest:50030/jobdetails.jsp?jobid=job_201206012240_0014
12/06/04 18:16:49 INFO streaming.StreamJob: map 0% reduce 0%
12/06/04 18:17:02 INFO streaming.StreamJob: map 50% reduce 0%
12/06/04 18:17:05 INFO streaming.StreamJob: map 100% reduce 0%
12/06/04 18:17:11 INFO streaming.StreamJob: map 100% reduce 33%
12/06/04 18:17:17 INFO streaming.StreamJob: map 100% reduce 100%
12/06/04 18:17:23 INFO streaming.StreamJob: Job complete: job_201206012240_0014
12/06/04 18:17:23 INFO streaming.StreamJob: Output: /tmp/RtmpSJ73OT/file1a096787a771
> result = from.dfs(out); result
> # out = wordcount("/user/hadoop/input/README.txt")](https://image.slidesharecdn.com/5-mapreduce-130417213100-phpapp01/85/5-map-reduce-87-320.jpg)






































![[Ankus Open Source Conference 2013] Introduction to Ankus / data mining](https://cdn.slidesharecdn.com/ss_thumbnails/ankusv3-131117190154-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










![[2A7]Linkedin'sDataScienceWhyIsItScience](https://cdn.slidesharecdn.com/ss_thumbnails/2a7linkedinsdatasciencewhyisitscience-140930023218-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










