Download to read offline








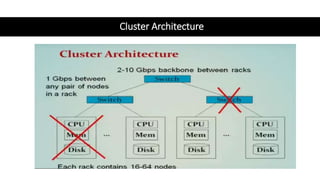

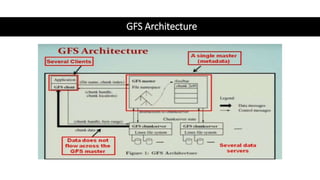


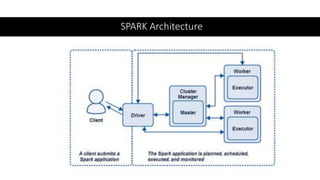





This document provides an overview of Spark architecture and its key concepts. It begins with discussing distributed systems challenges prior to Spark and how Google File System addressed these. It then explains Spark's architecture which includes a driver program that coordinates executors running on worker nodes to process RDDs represented as a DAG. The document also compares Spark concepts like RDDs and partitions to GFS concepts like files and chunks to highlight their similarities.






























































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)




