Downloaded 25 times



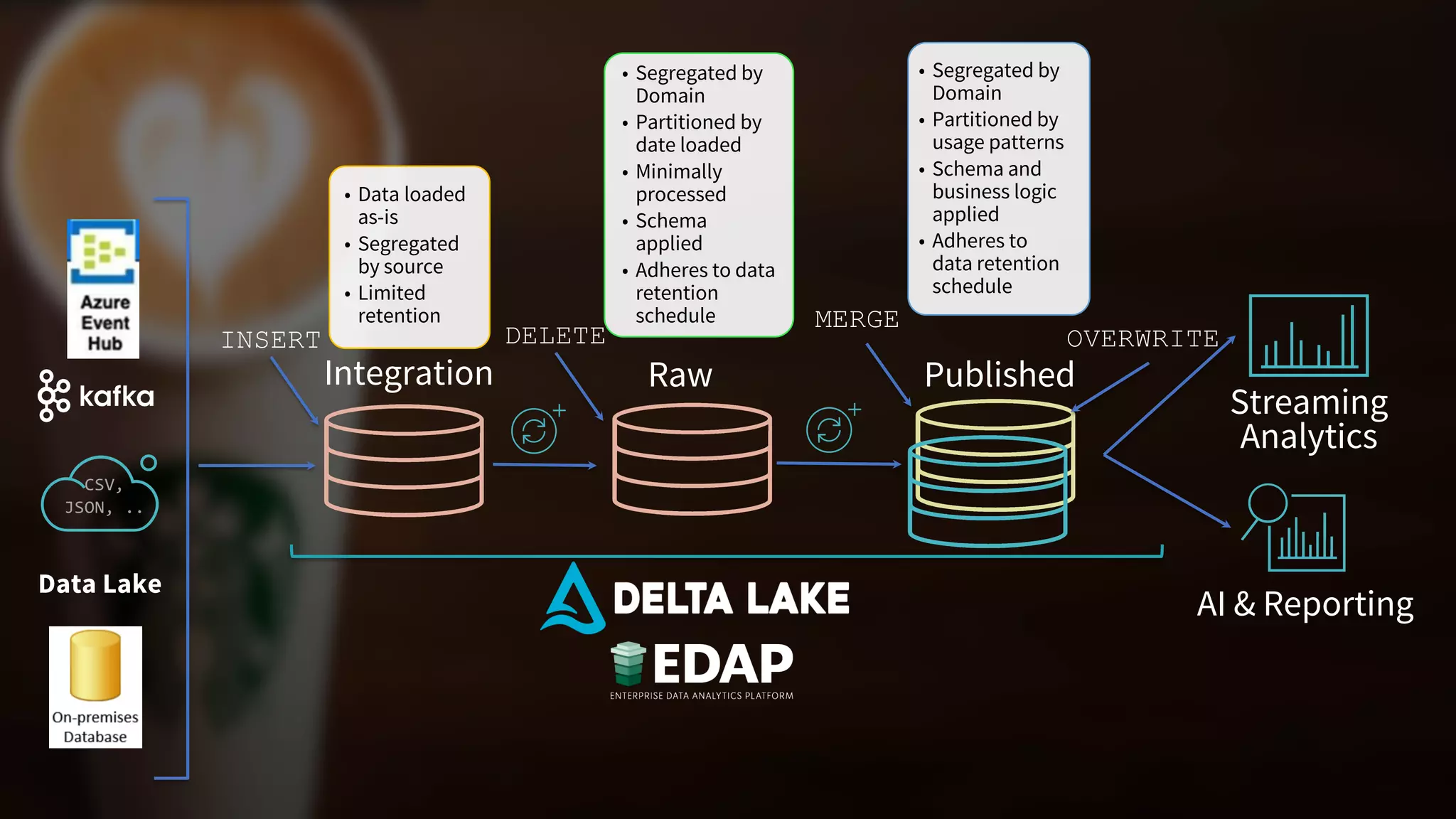







The document outlines Starbucks' operationalization of big data pipelines using an enterprise data analytics platform that includes Azure Databricks and Delta Lake, managing over 4 petabytes of data across 1000+ pipelines. It details the structure and processing of data for various domains, highlighting features like high parallelism for ingestion, delta optimization for query performance, and support for both batch and streaming data. Additionally, it emphasizes consumer accessibility and collaboration in data usage, aiming for data democratization and enhanced reporting and AI/ML capabilities.























































































