Download as PDF, PPTX




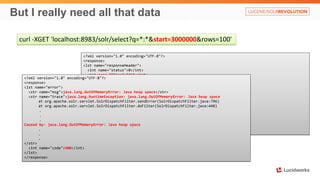
![And faulty indexing
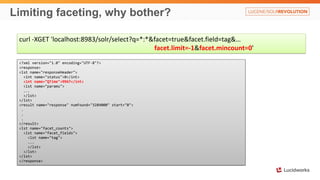
<?xml version="1.0" encoding="UTF-8"?>
<response>
<lst name="responseHeader">
<int name="status">400</int>
<int name="QTime">0</int>
</lst>
<lst name="error">
<str name="msg">missing content stream</str>
<int name="code">400</int>
</lst>
</response>
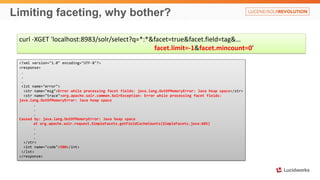
109173 [qtp1223685984-20] ERROR org.apache.solr.core.SolrCore ľ org.apache.solr.common.SolrException: missing content stream
at org.apache.solr.handler.ContentStreamHandlerBase.handleRequestBody(ContentStreamHandlerBase.java:69)
at org.apache.solr.handler.RequestHandlerBase.handleRequest(RequestHandlerBase.java:135)
at org.apache.solr.core.SolrCore.execute(SolrCore.java:1967)
at org.apache.solr.servlet.SolrDispatchFilter.execute(SolrDispatchFilter.java:777)
at org.apache.solr.servlet.SolrDispatchFilter.doFilter(SolrDispatchFilter.java:418)
at org.apache.solr.servlet.SolrDispatchFilter.doFilter(SolrDispatchFilter.java:207)
at org.eclipse.jetty.servlet.ServletHandler$CachedChain.doFilter(ServletHandler.java:1419)
at org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:455)
at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:137)
at org.eclipse.jetty.security.SecurityHandler.handle(SecurityHandler.java:557)
at org.eclipse.jetty.server.session.SessionHandler.doHandle(SessionHandler.java:231)
at org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1075)
at org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:384)
at org.eclipse.jetty.server.session.SessionHandler.doScope(SessionHandler.java:193)
at org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1009)
at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:135)
at org.eclipse.jetty.server.handler.ContextHandlerCollection.handle(ContextHandlerCollection.java:255)
at org.eclipse.jetty.server.handler.HandlerCollection.handle(HandlerCollection.java:154)
at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:116)
at org.eclipse.jetty.server.Server.handle(Server.java:368)
at org.eclipse.jetty.server.AbstractHttpConnection.handleRequest(AbstractHttpConnection.java:489)
at org.eclipse.jetty.server.BlockingHttpConnection.handleRequest(BlockingHttpConnection.java:53)
at org.eclipse.jetty.server.AbstractHttpConnection.headerComplete(AbstractHttpConnection.java:942)
at org.eclipse.jetty.server.AbstractHttpConnection$RequestHandler.headerComplete(AbstractHttpConnection.java:1004)
at org.eclipse.jetty.http.HttpParser.parseNext(HttpParser.java:647)
at org.eclipse.jetty.http.HttpParser.parseAvailable(HttpParser.java:235)
at org.eclipse.jetty.server.BlockingHttpConnection.handle(BlockingHttpConnection.java:72)
at org.eclipse.jetty.server.bio.SocketConnector$ConnectorEndPoint.run(SocketConnector.java:264)
at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:608)
at org.eclipse.jetty.util.thread.QueuedThreadPool$3.run(QueuedThreadPool.java:543)
at java.lang.Thread.run(Unknown Source)](https://image.slidesharecdn.com/solranti-patterns-141114203052-conversion-gate02/85/Solr-Anti-patterns-8-320.jpg)
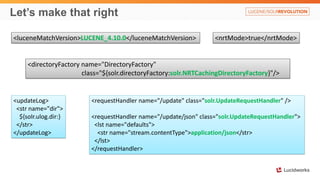
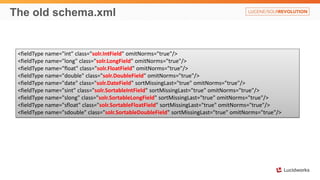
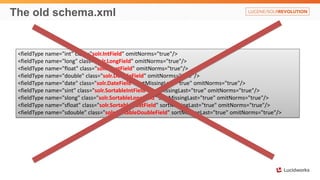


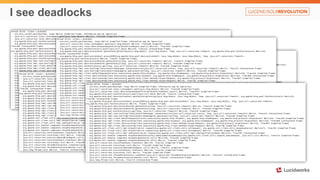
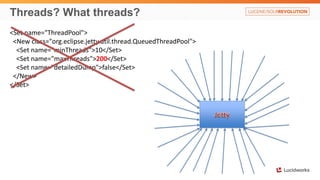
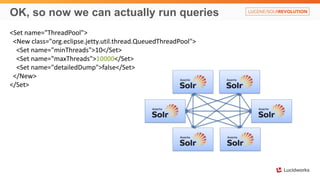


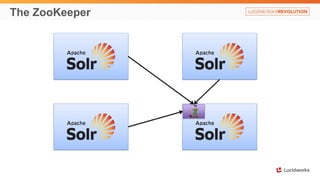

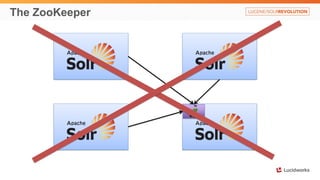

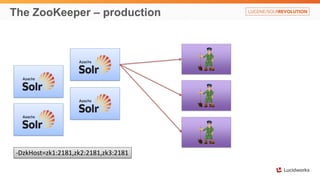
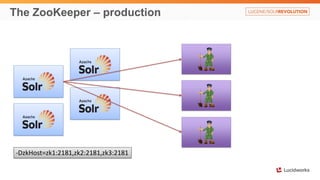
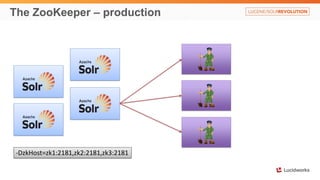
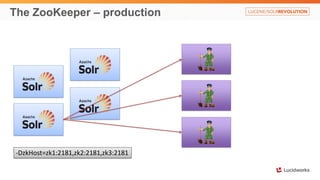

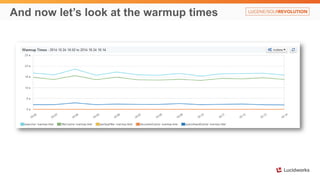
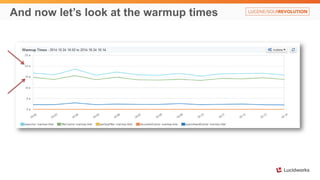

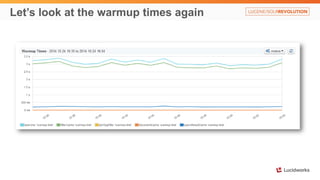
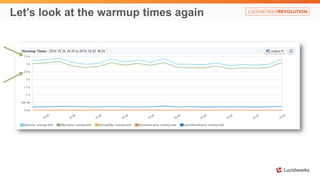
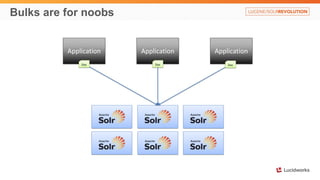
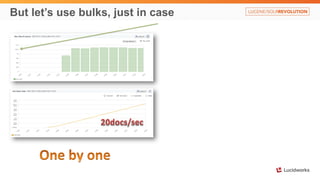
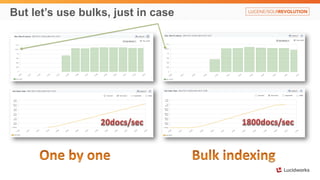
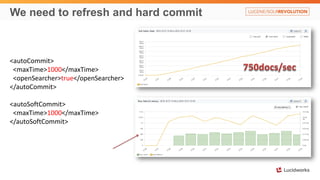
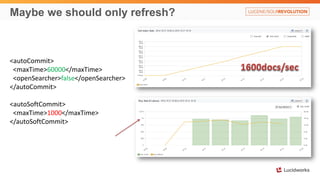
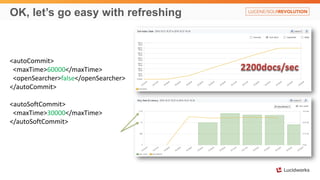
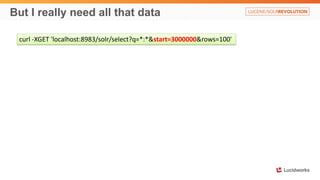
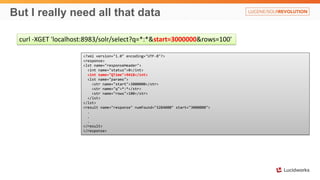
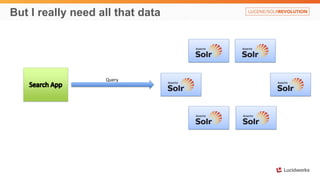
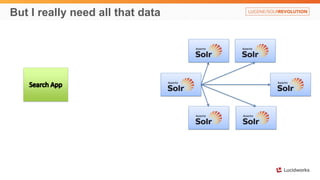
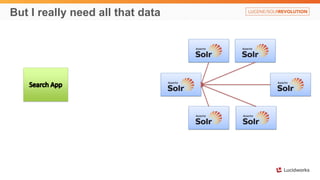

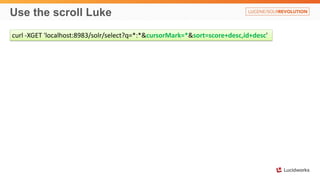
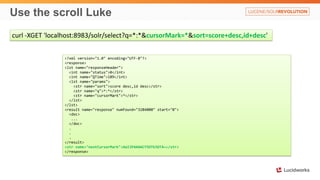
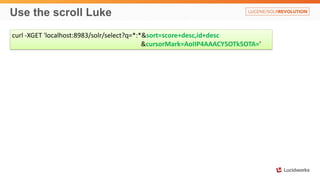
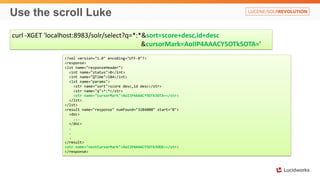

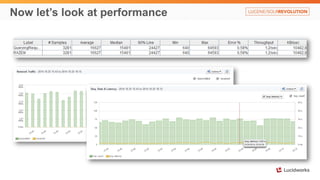
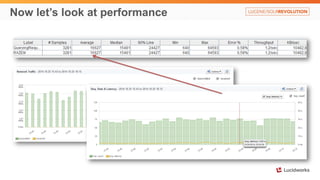
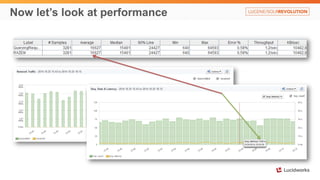
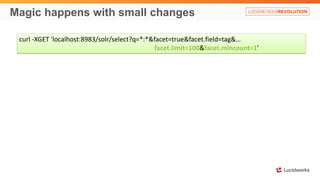

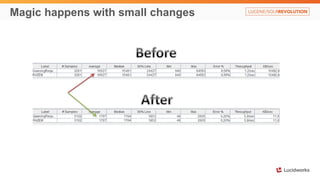
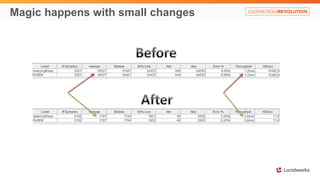
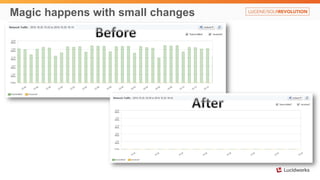
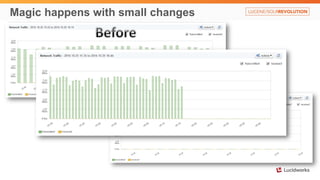
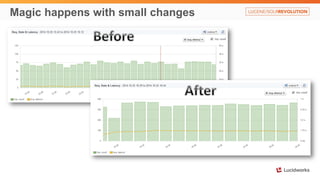
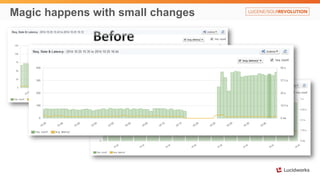
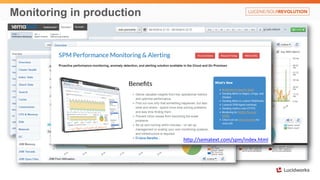


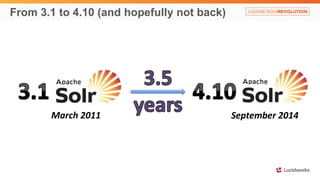
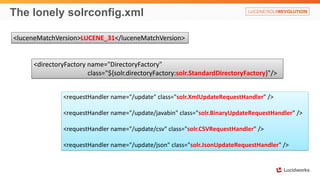
Solr anti-patterns discusses common issues when migrating from older Solr versions to newer ones, including improperly configured request handlers, indexing errors, and lack of configuration for threads and caching. The document provides recommendations for updating configurations to address these issues, such as using newer field types, configuring thread pools, and tuning cache sizes and refresh settings.






















































![How Big Brands are Taking Your Traffic in Alberta [Data Inside].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/howbigbrandsaretakingyourtrafficinalbertadatainside-260123180142-42d276f3-thumbnail.jpg?width=640&height=640&fit=bounds)



