第19回LuceneSolr勉強会で話をさせていただいた内容です
第19回LuceneSolr勉強会
https://solr.doorkeeper.jp/events/53600
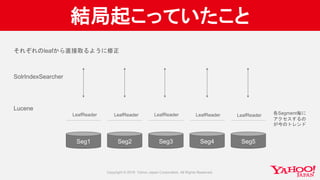
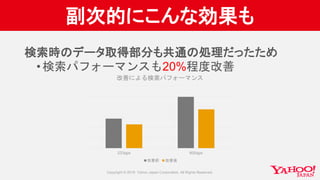
SOLR-9592でコミットした、AtomicUpdateの高速化の話についての、詳細を記載しております。
https://issues.apache.org/jira/browse/SOLR-9592
最後の、storedの用途が限定的という話は、別途Solr AdventCalenderで、詳しく書いていますので、そちらも参考にしてください。
[Solr Advent Calender 2016 14日目]
SolrでのdocValuesとstoredの使い分け
http://qiita.com/takaishi/items/6f08325c2eb3922bf166




![AtomicUpdate?
{"id":"mydoc",
"price":{"set":99},
"popularity":{"inc":20},
"categories":{"add":["toys","games"]},
"promo_ids":{"remove":"a123x"},
"tags":{"remove":["free_to_try","on_sale"]}
}
具体的な更新データは例えば以下のような形](https://image.slidesharecdn.com/19lucenesolr-161216030059/85/Solr-AtomicUpdate-50000-5-320.jpg)