Download to read offline




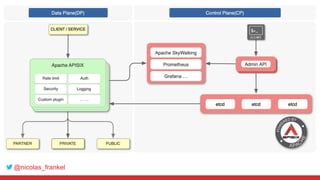







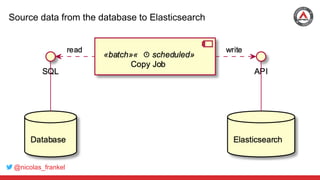
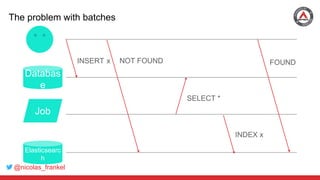












The document discusses the process of integrating search capabilities into legacy applications, highlighting crucial decision steps such as maintaining the SQL database, selecting a search engine, and choosing an appropriate architecture. It addresses common challenges like dual writes and batch processing, and introduces Change Data Capture (CDC) as a solution for tracking data changes effectively. Debezium is presented as a robust implementation for CDC that allows real-time data streaming instead of batch processing.






















































































