Download to read offline






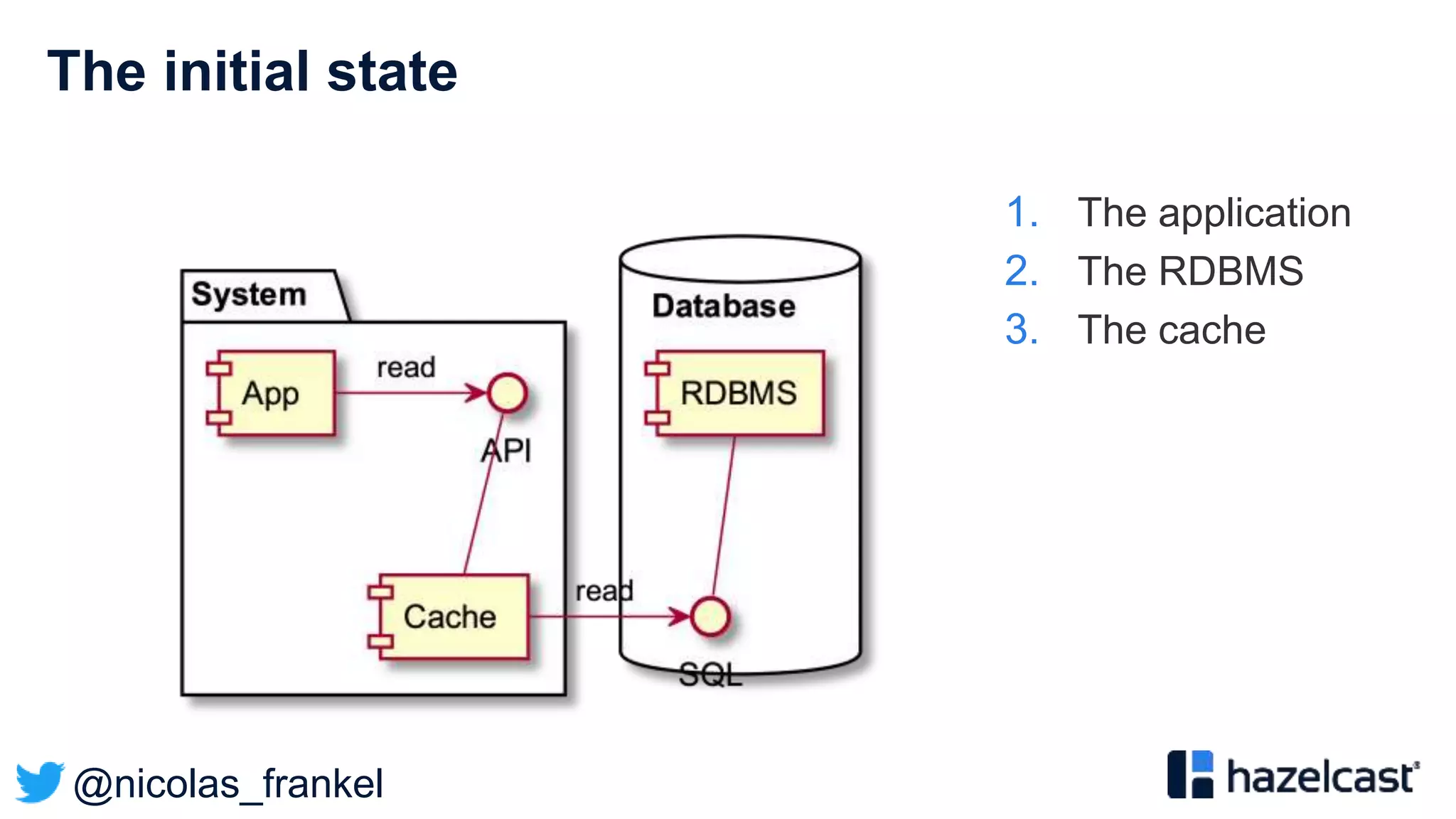
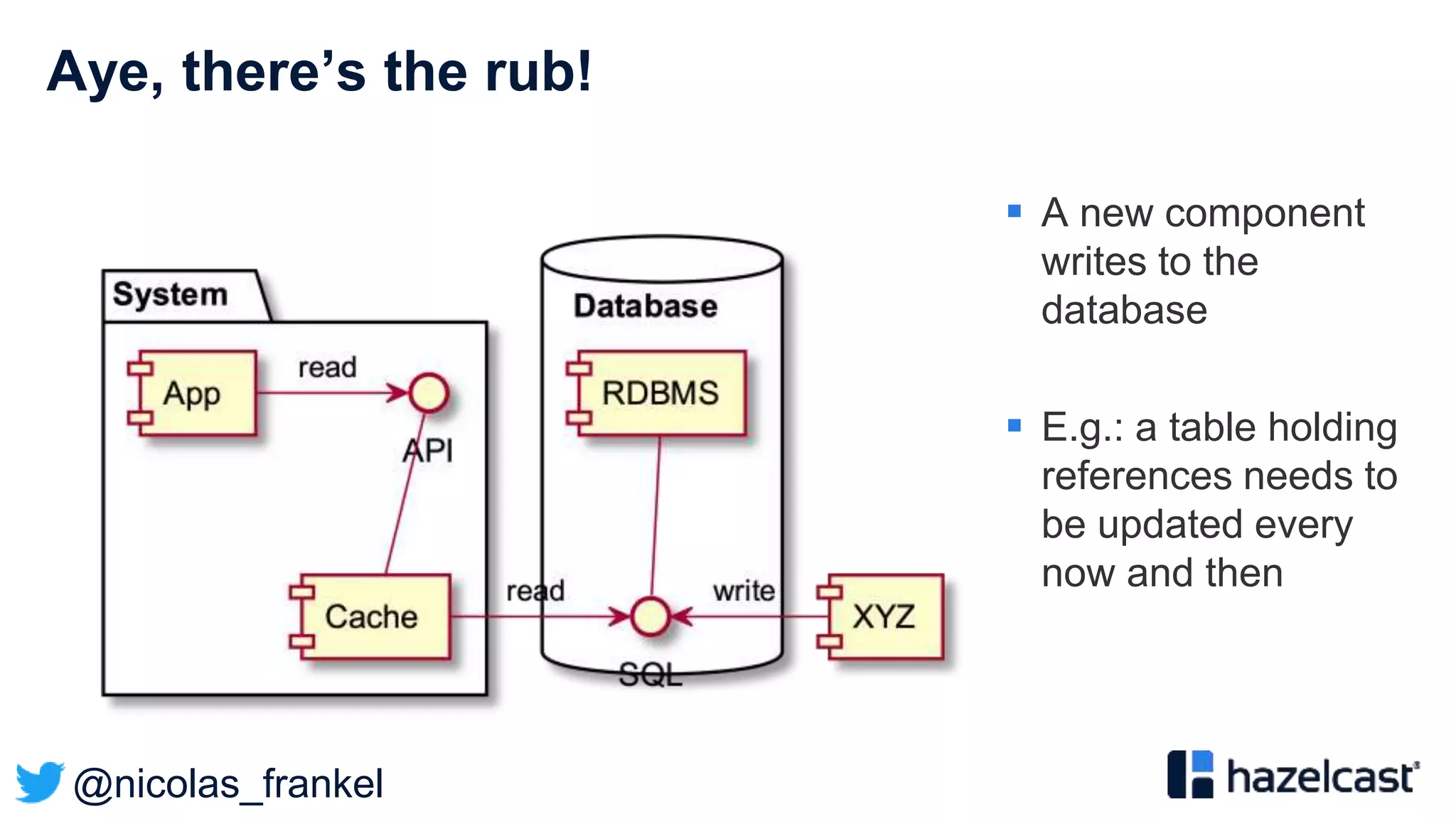












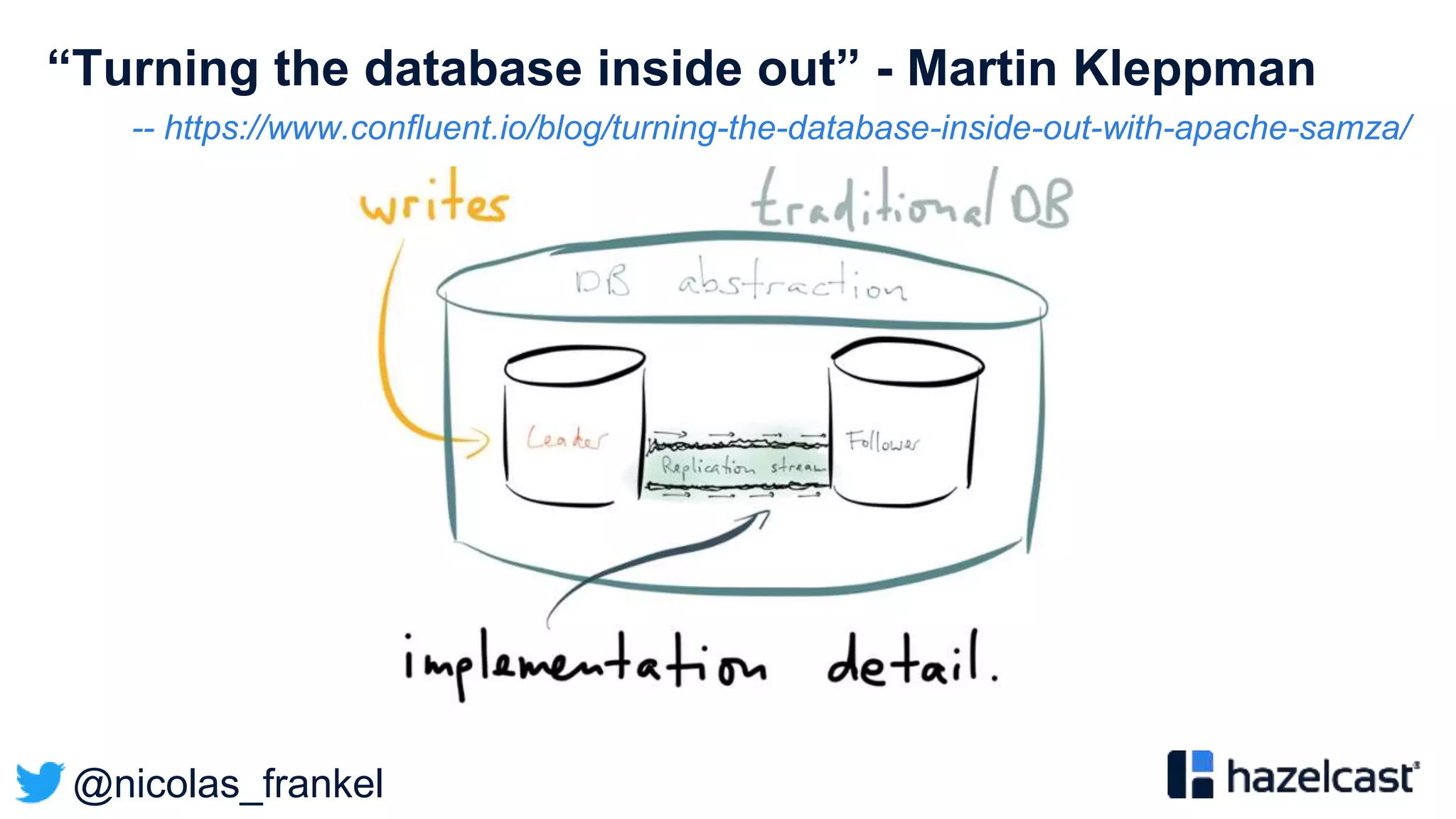







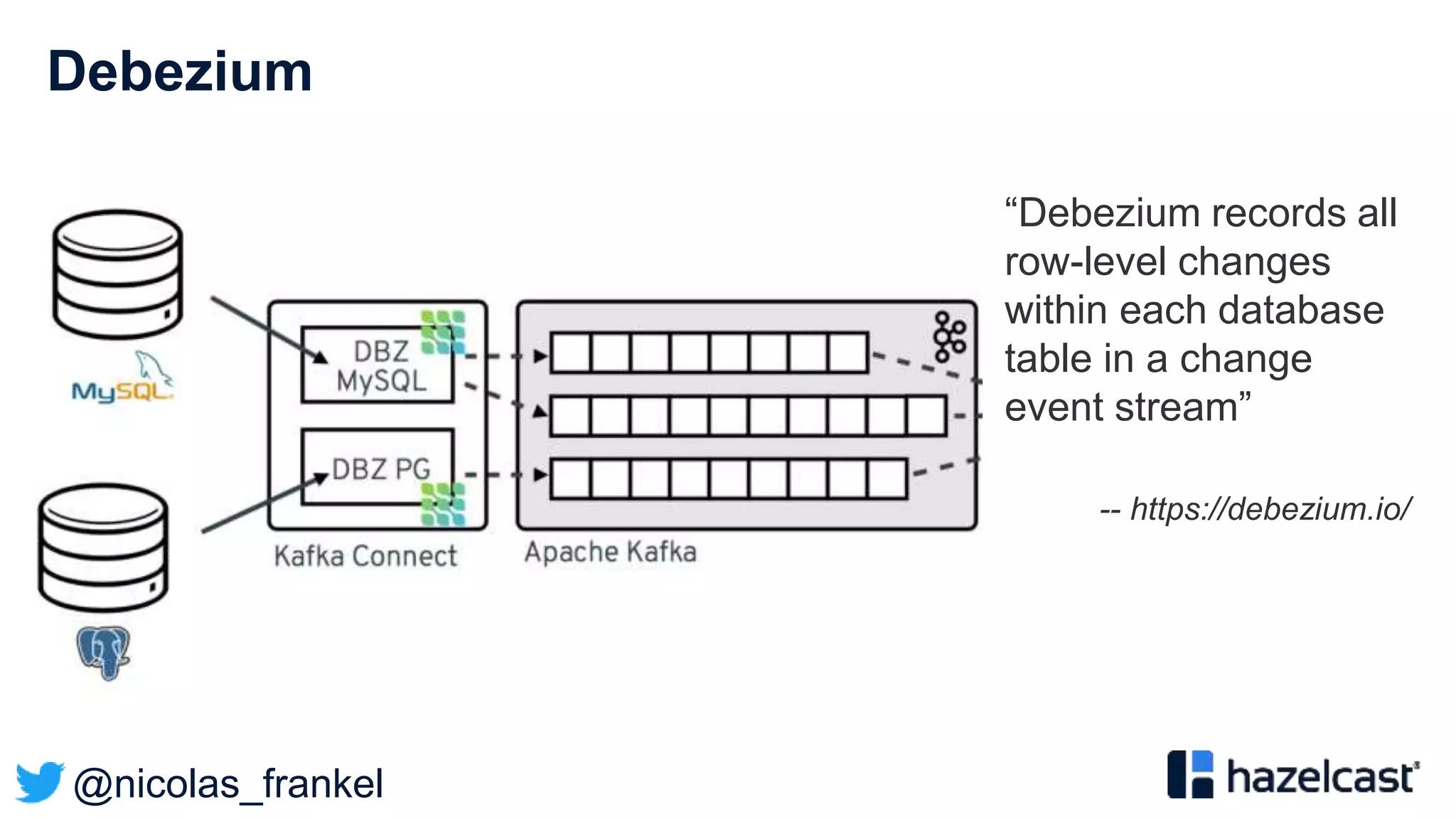

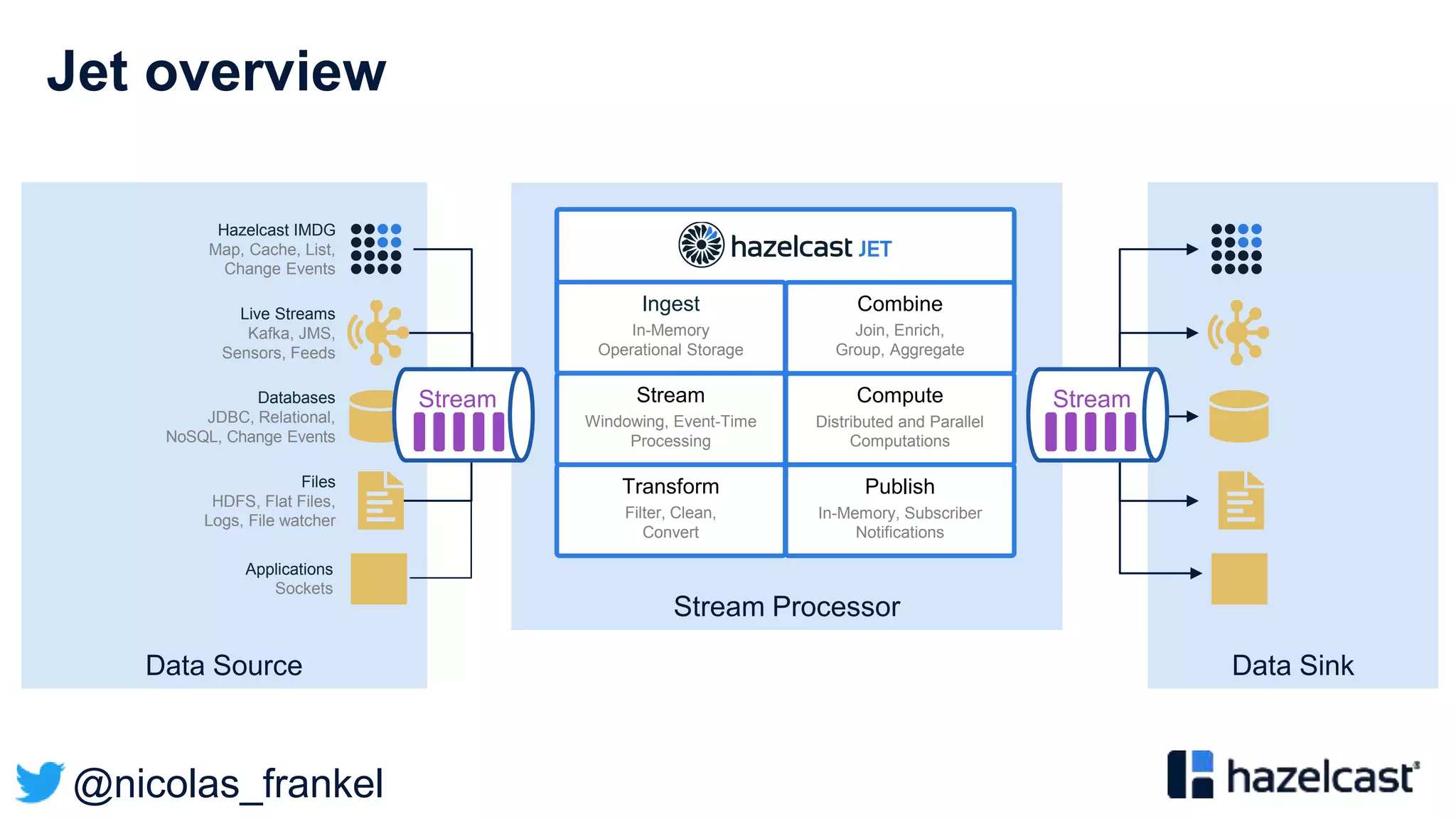
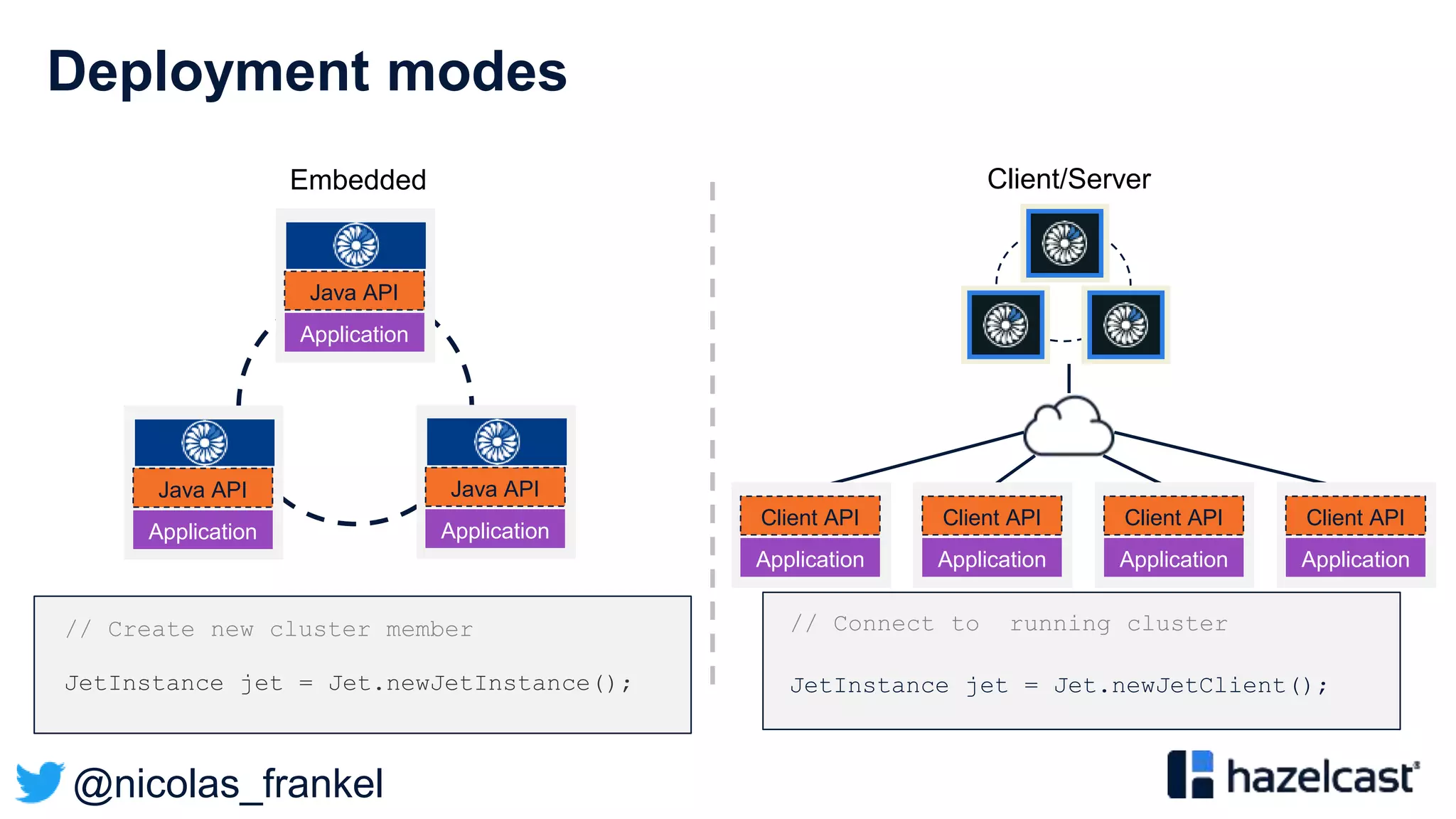
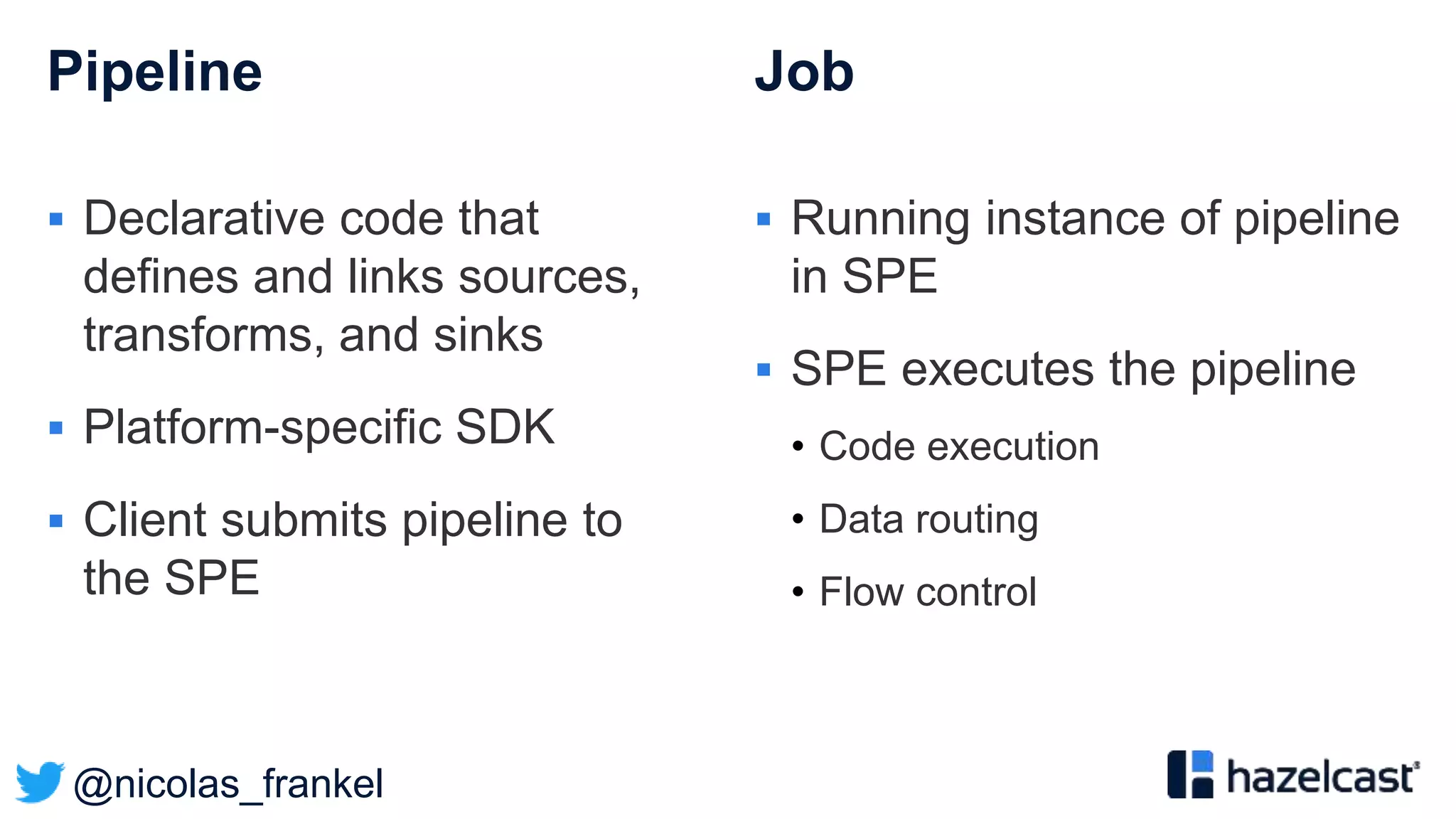





The document presents an overview of designing an evergreen cache using change-data-capture (CDC) with Hazelcast Jet and Debezium. It discusses the challenges of cache synchronization, alternatives, and the benefits of an event-driven approach. The session concludes with a recap of key points and suggests resources for further exploration.























































































