Downloaded 31 times





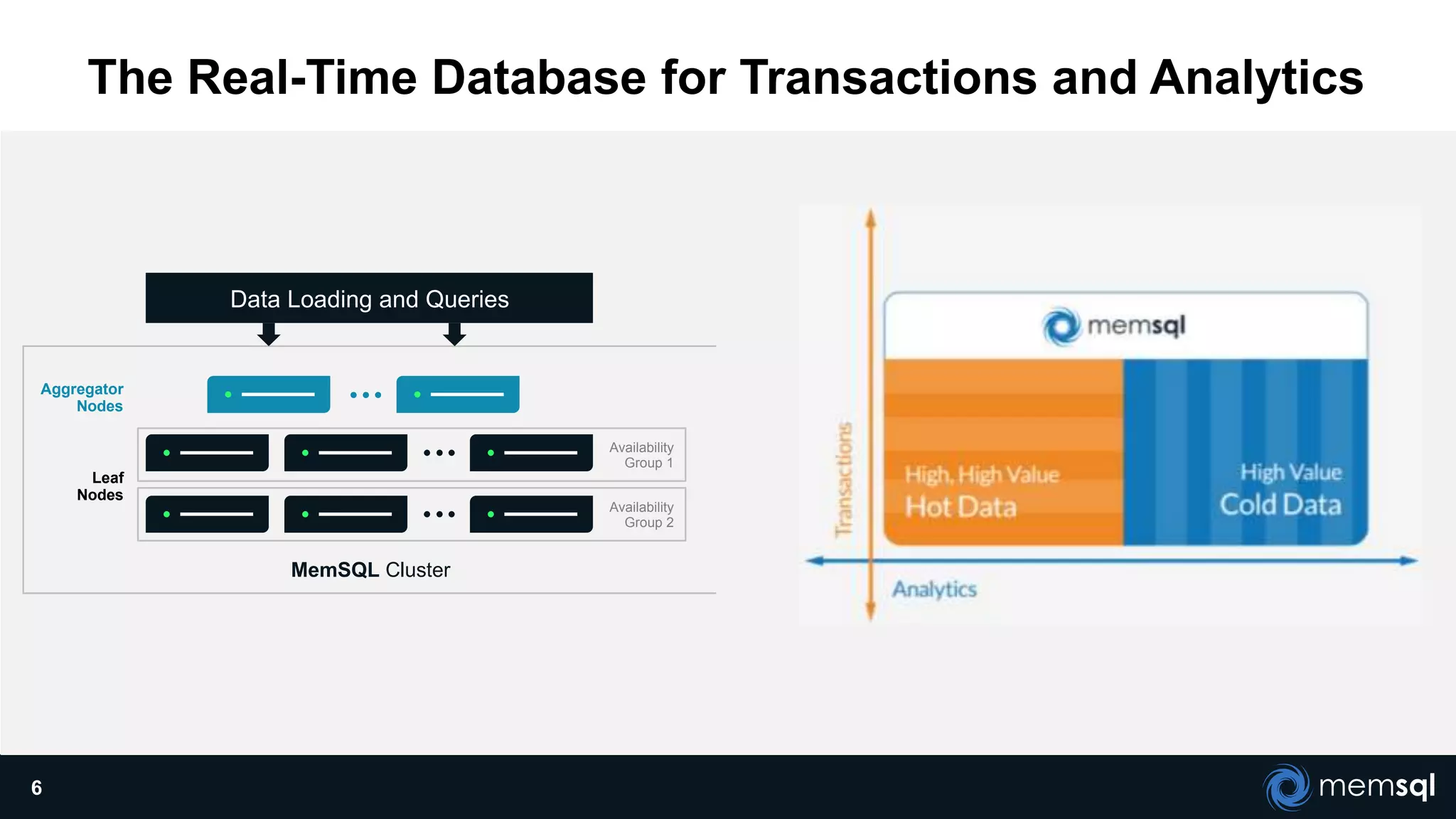





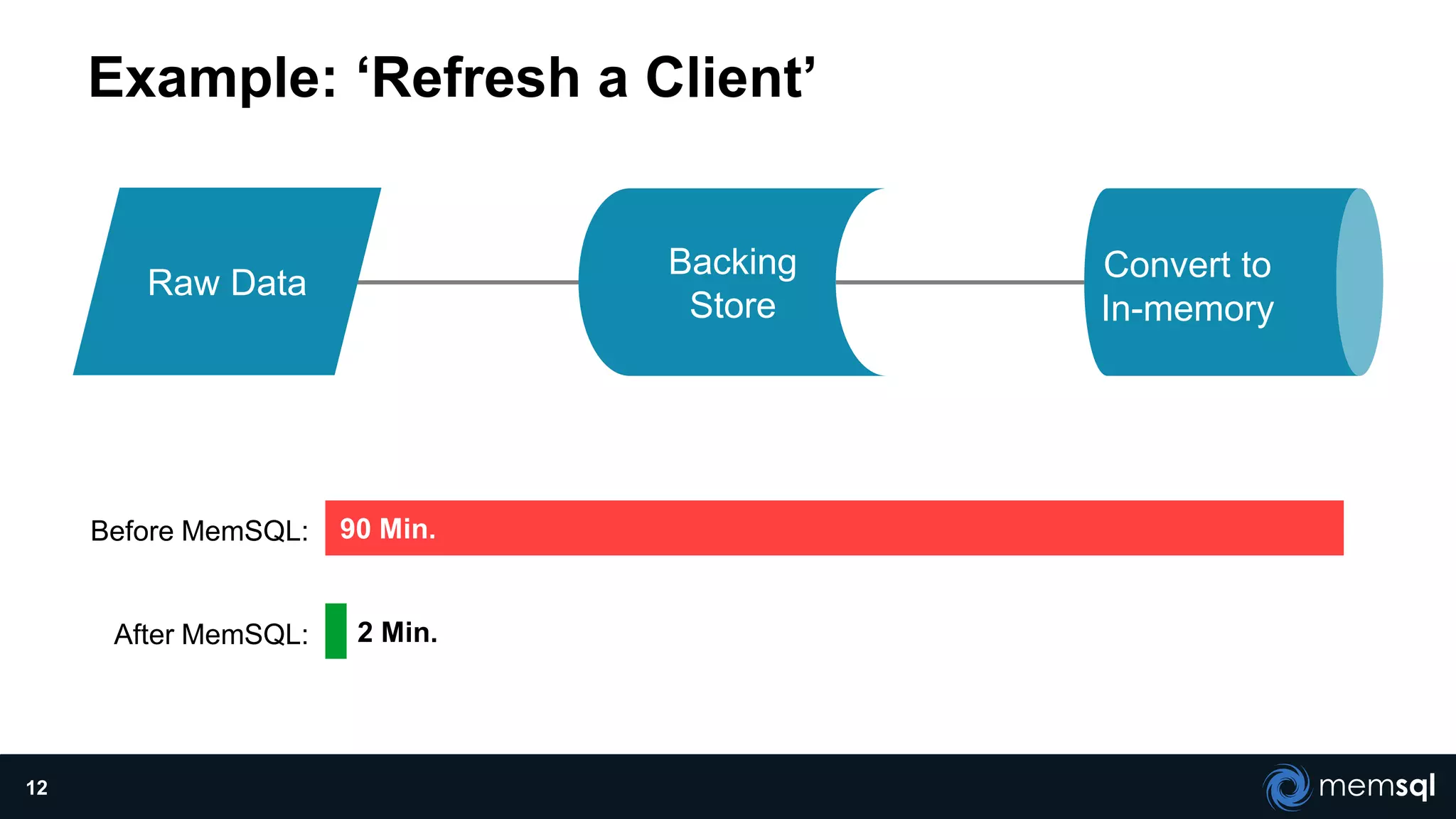



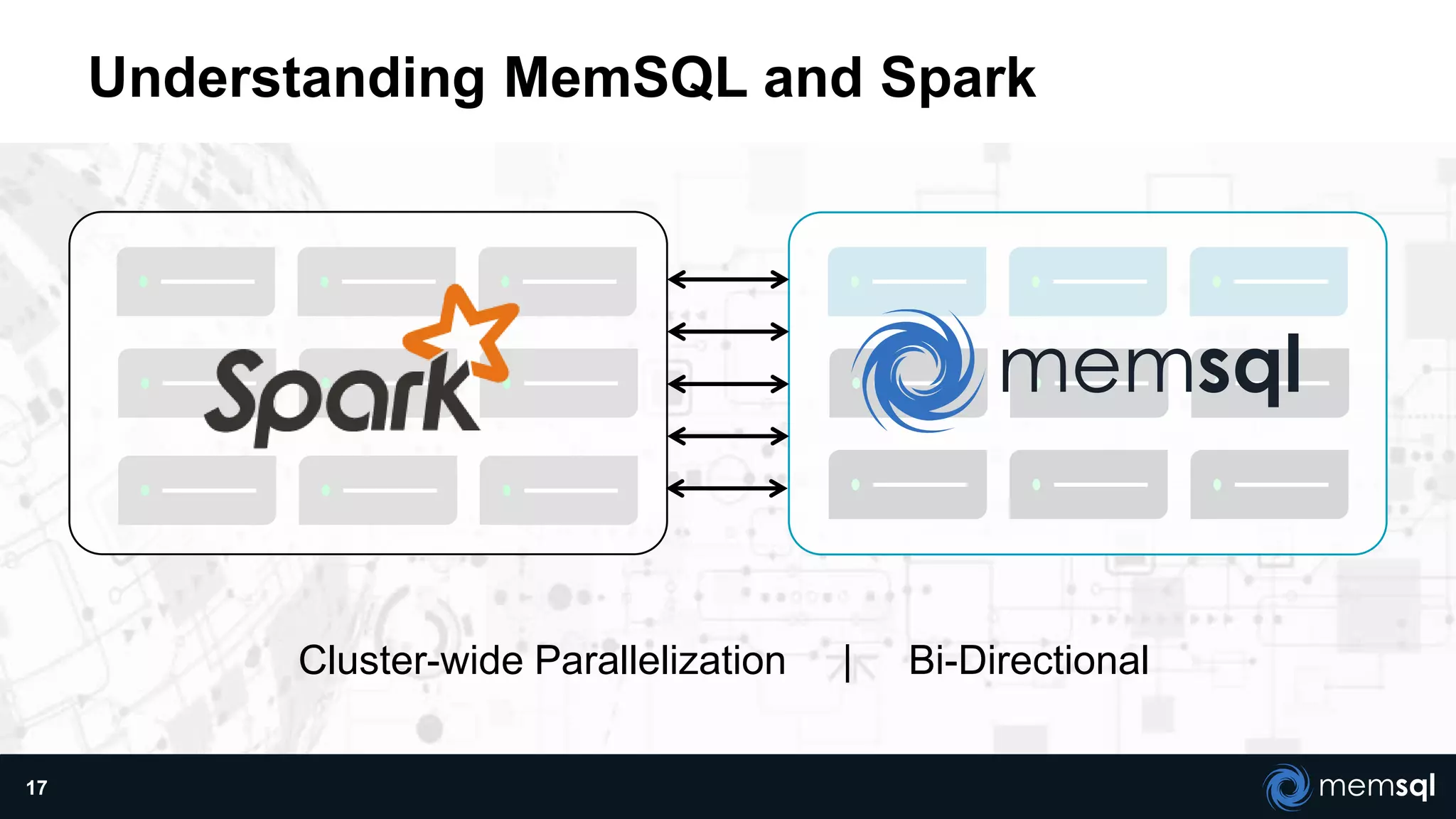



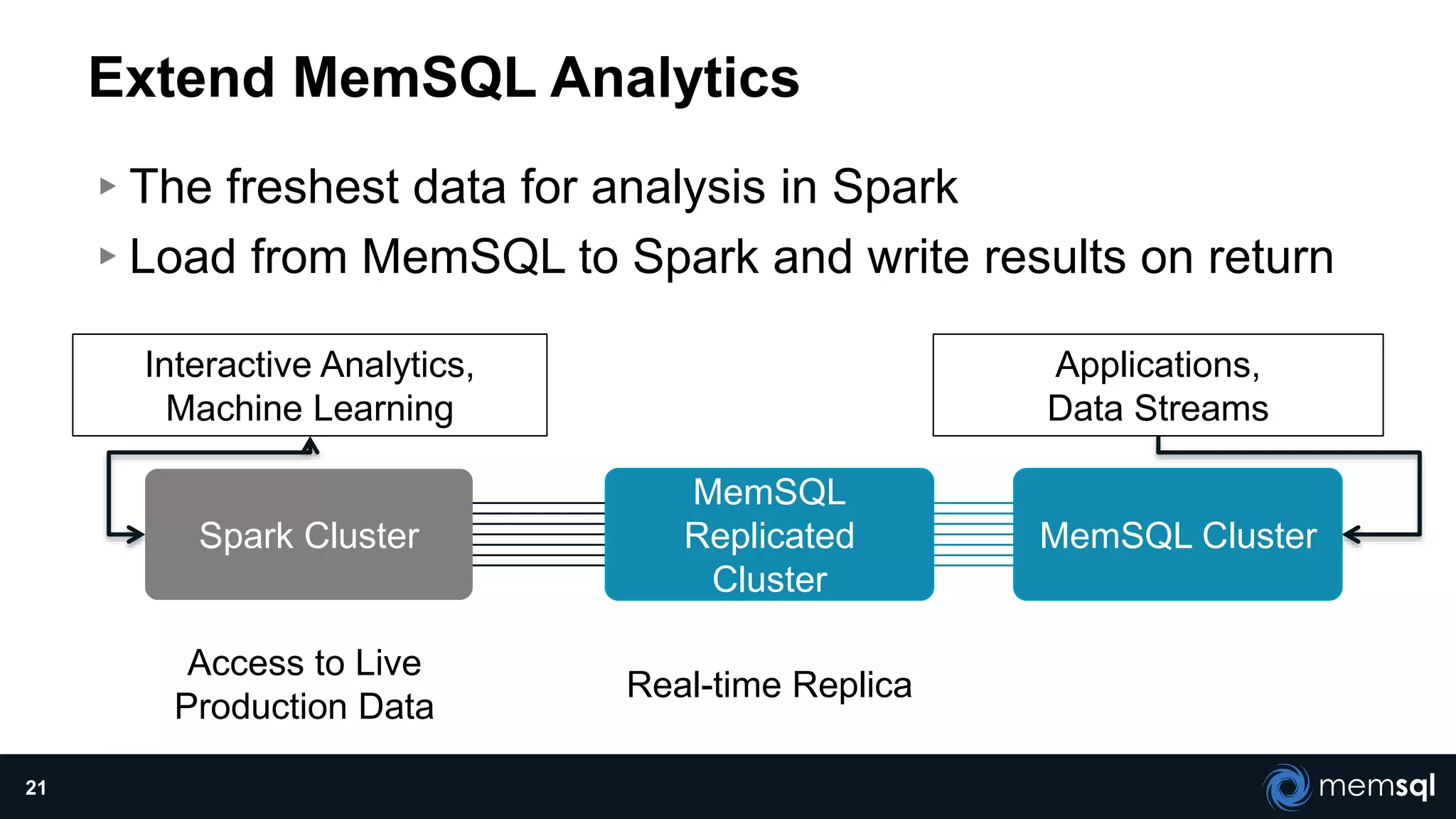


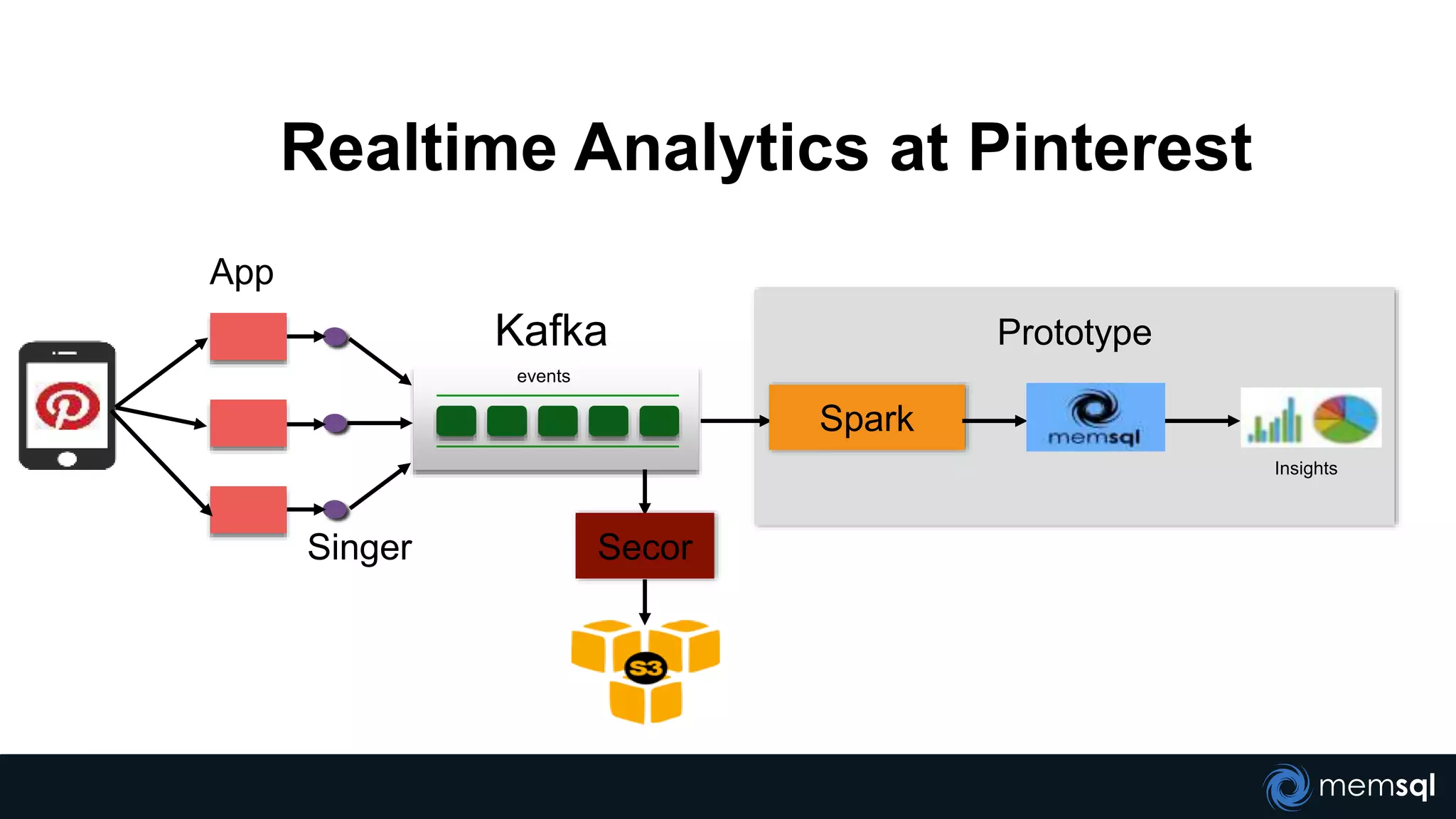

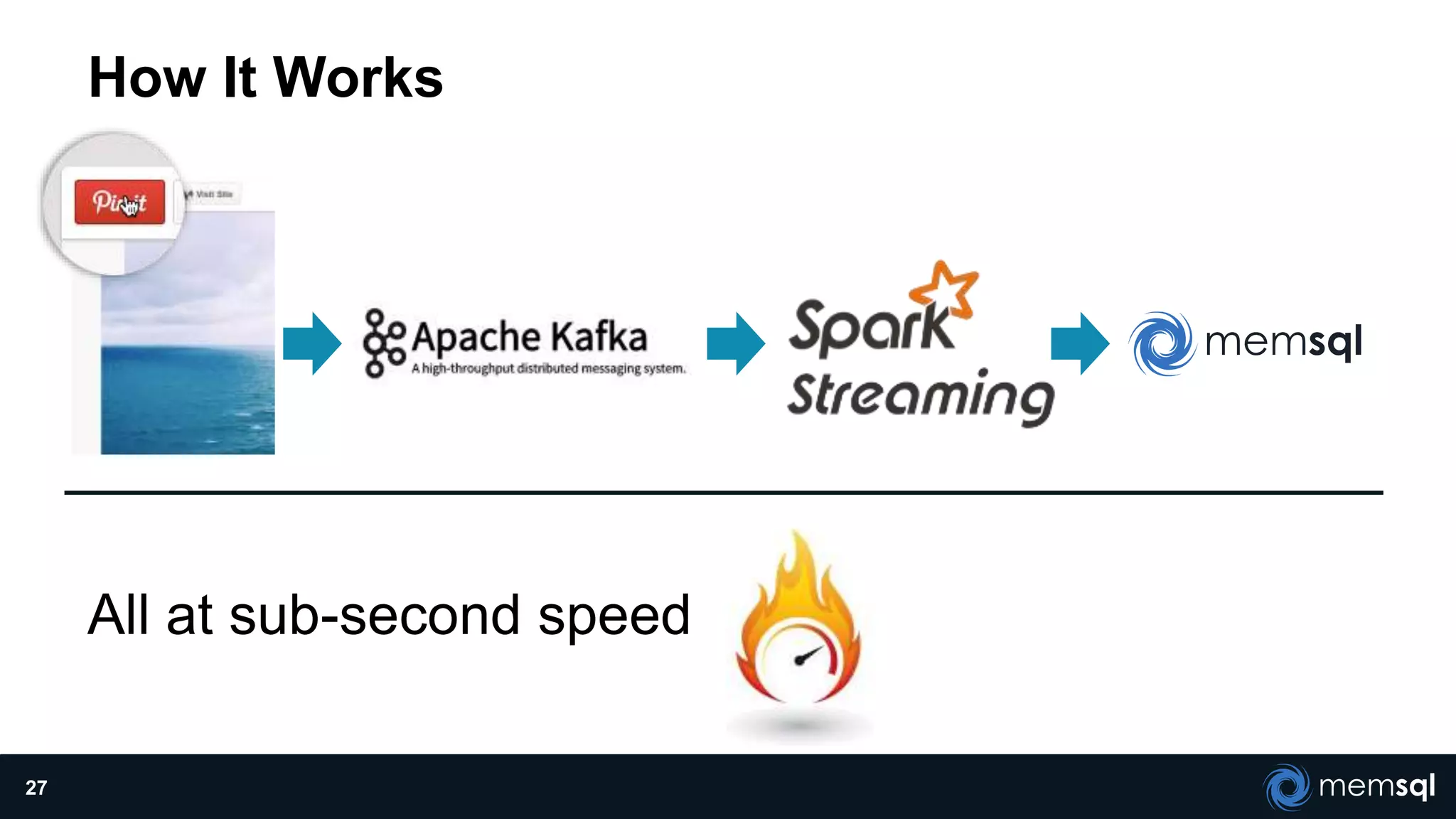
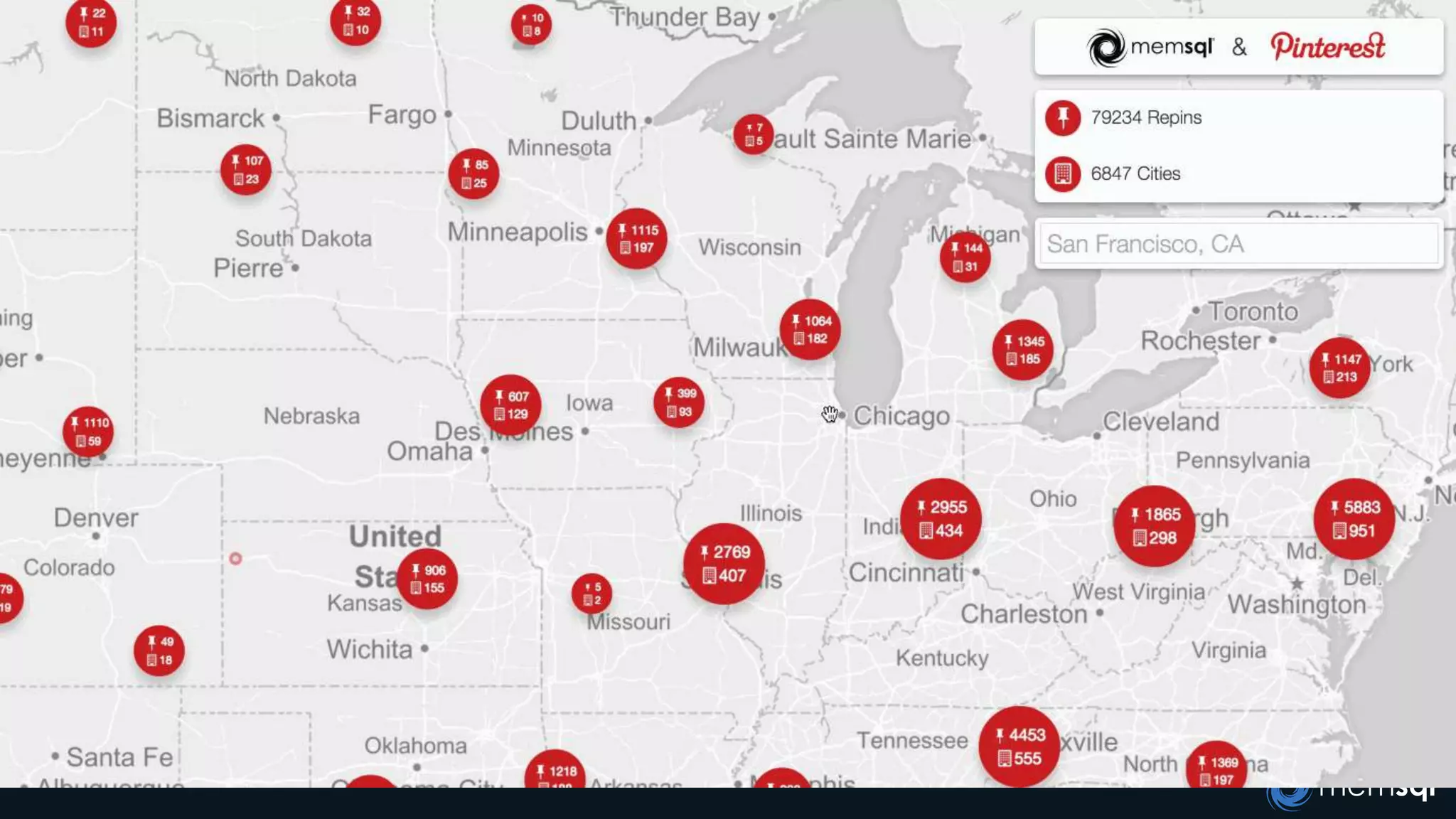

The document discusses a presentation about MemSQL, a real-time database aimed at improving transaction and analytical processes, featuring a case study from Novus, highlighting the benefits of using MemSQL to reduce data loading times. It also covers recent developments in Apache Spark and its integration with MemSQL for enhanced data processing capabilities, particularly for real-time analytics. The document concludes with a demonstration from Pinterest, showcasing the efficiency of Spark in managing high traffic event data.























































































