Download as PDF, PPTX













![Scheduler SPI (implemented by Framework)
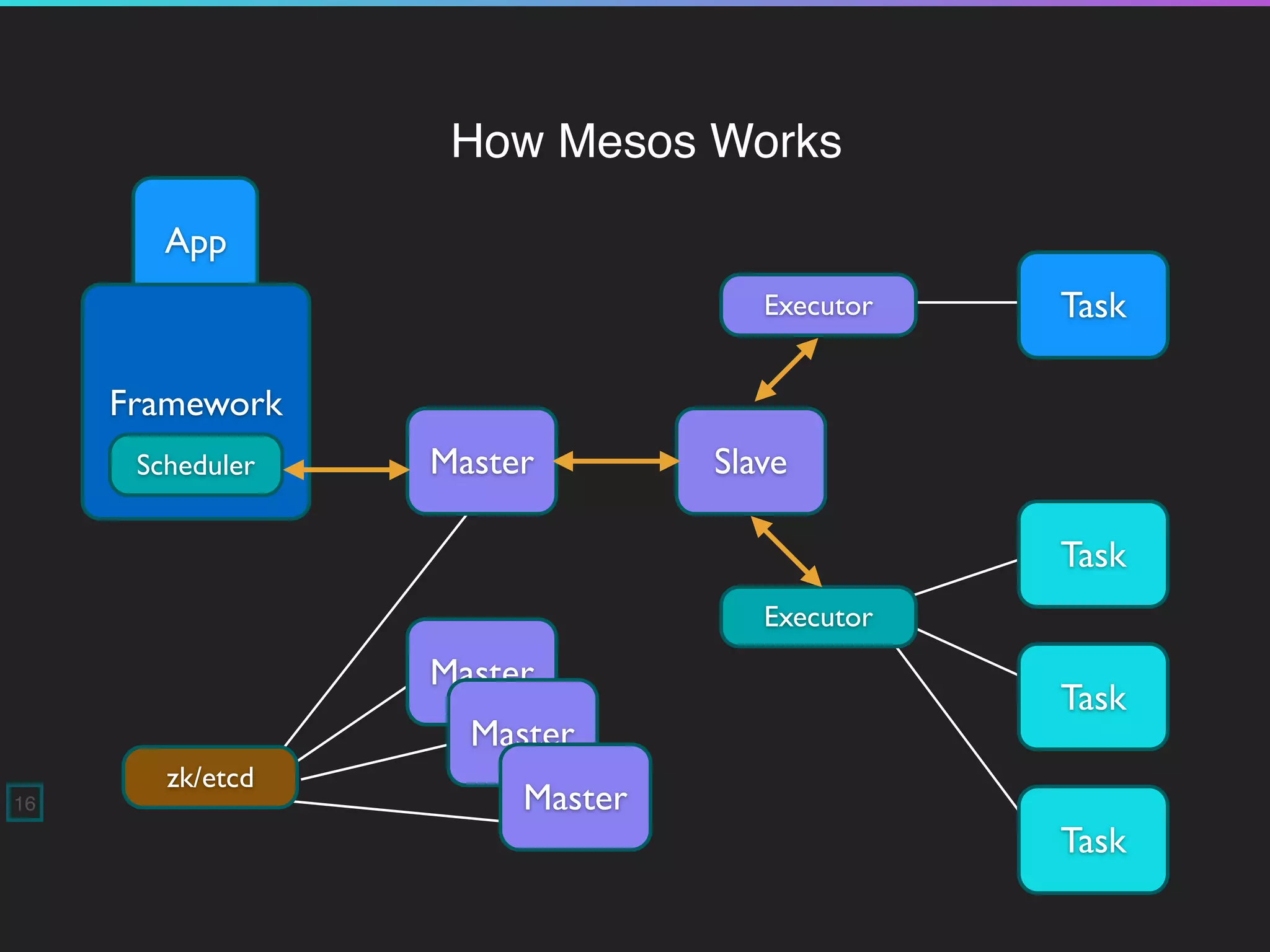
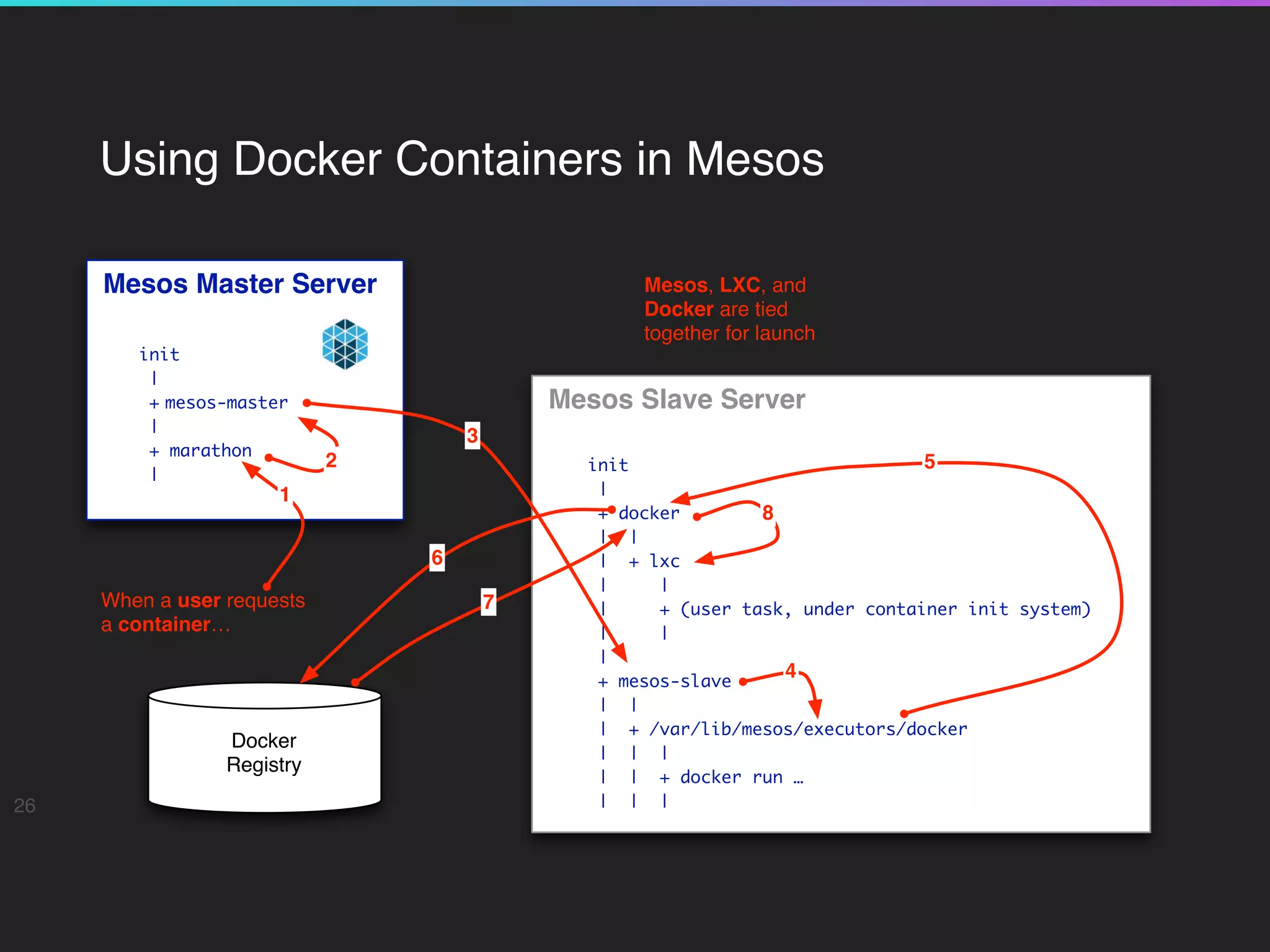
20
public interface Scheduler {
void registered(SchedulerDriver driver, FrameworkID frameworkId,
MasterInfo masterInfo);
void reregistered(SchedulerDriver driver, MasterInfo masterInfo);
void resourceOffers(SchedulerDriver driver, List<Offer> offers);
void offerRescinded(SchedulerDriver driver, OfferID offerId);
void statusUpdate(SchedulerDriver driver, TaskStatus status);
void frameworkMessage(SchedulerDriver driver, ExecutorID executorId,
SlaveID slaveId, byte[] data);
void disconnected(SchedulerDriver driver);
void slaveLost(SchedulerDriver driver, SlaveID slaveId);
void executorLost(SchedulerDriver driver, ExecutorID executorId,
SlaveID slaveId, int status);
void error(SchedulerDriver driver, String message);
}](https://image.slidesharecdn.com/berndmathiskewhythedatacenterneedsanoperatingsystems-150428034419-conversion-gate01/75/OSDC-2015-Bernd-Mathiske-Why-the-Datacenter-Needs-an-Operating-System-20-2048.jpg)









The presentation by Dr. Bernd Mathiske discusses the evolution of datacenter operations, emphasizing the need for a unified operating system to manage large-scale computing effectively. It highlights the transition from traditional server architectures to cloud-based services, focusing on technologies like Mesos and containerization for resource management and application deployment. Key features for efficiency include multi-tenancy, dynamic scheduling, and integrating frameworks for improved application and operational perspectives in a datacenter environment.















































