Downloaded 34 times




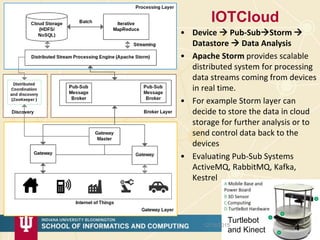
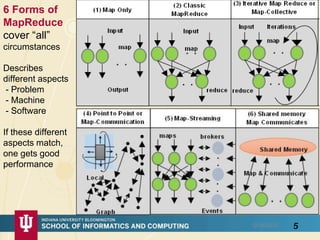
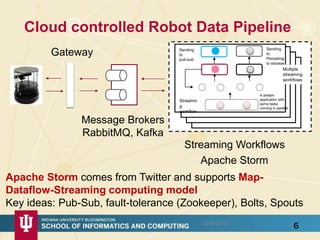
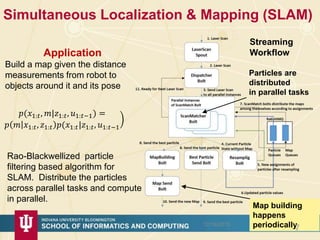
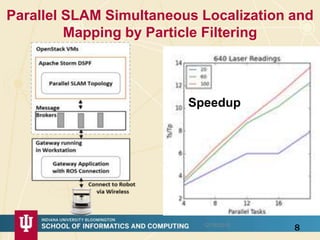
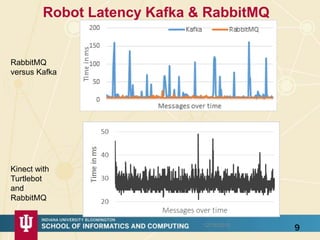
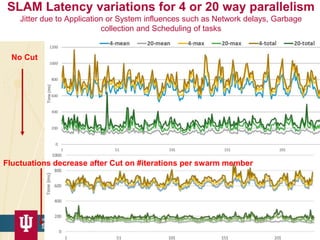
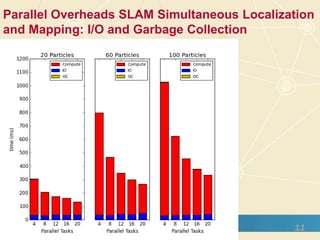




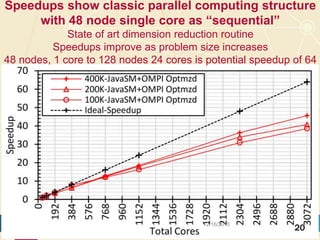
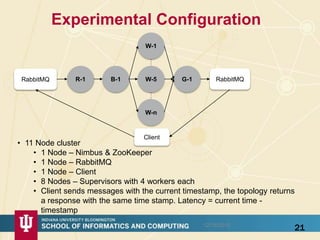
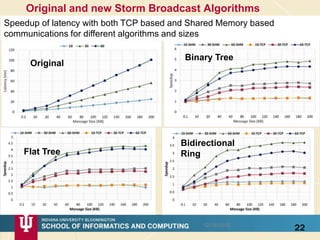




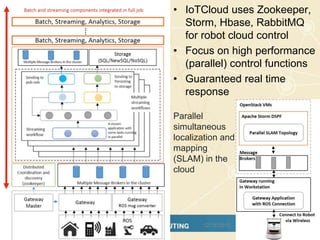
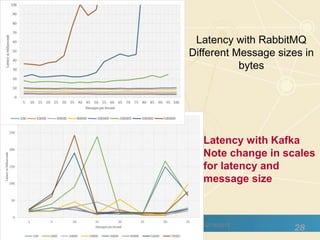
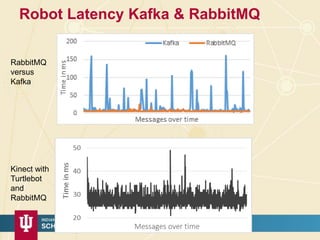
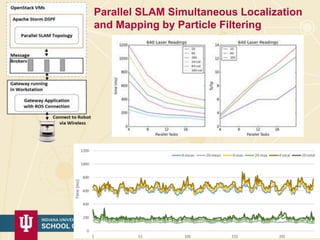

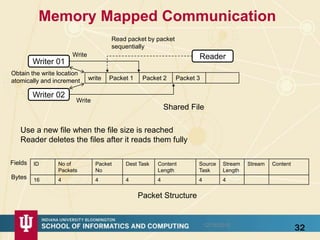
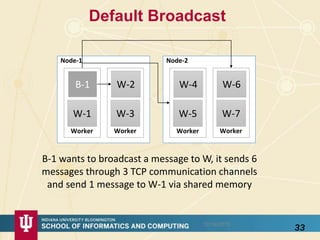
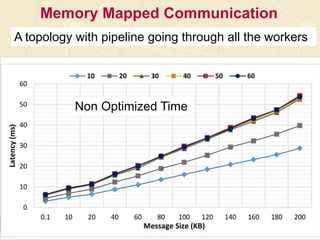

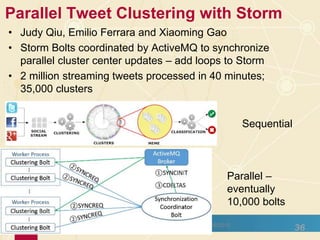
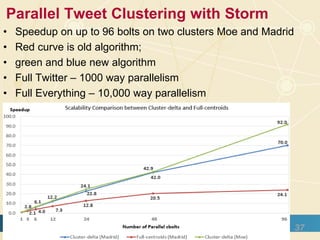
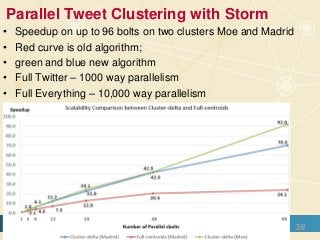

The document discusses high-performance processing of streaming data using Apache Storm as part of the HPC-ABDS framework, presented at the 22nd International Conference on High-Performance Computing. It outlines the integration of various technologies and tools for enhancing data processing in real-time applications, particularly in robotics and cloud environments. Key challenges and lessons learned in optimizing performance, fault tolerance, and communication efficiency within distributed systems are also addressed.






















































































