Downloaded 18 times







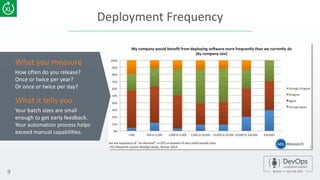


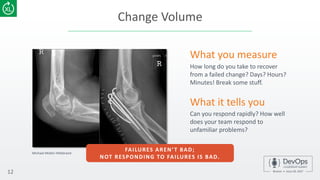

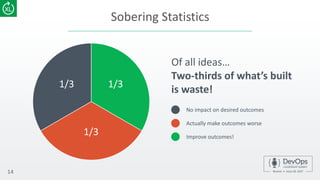







The document emphasizes the importance of metrics in improving DevOps practices, highlighting characteristics of effective metrics and their correlation to business performance. It introduces key metrics for a DevOps dashboard, such as deployment frequency, time to recovery, and success rates, to assess the efficiency of development and deployment processes. Additionally, it discusses the significance of measuring user adoption, happiness, and business impact to enhance software outcomes.






















































































