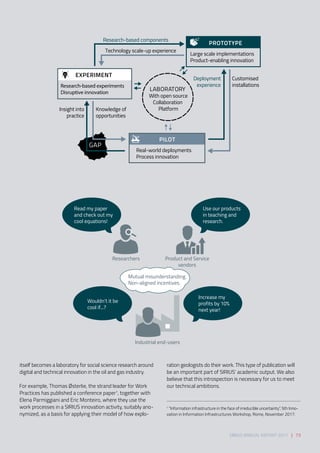
Download to read offline



























































































The Sirius annual report 2017 outlines the center's progress in developing collaborative doctoral projects and innovative solutions for data access issues in the oil and gas industry. It highlights the importance of bridging the gap between research and industry through interdisciplinary work and showcases various projects addressing operational challenges through digitalization. Sirius collaborates with multiple industry partners to advance technological innovations applicable not only in oil and gas but also in sectors such as healthcare and public administration.



































































