Downloaded 12 times












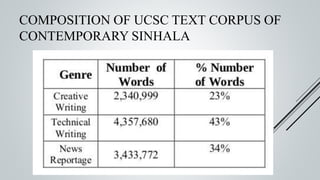




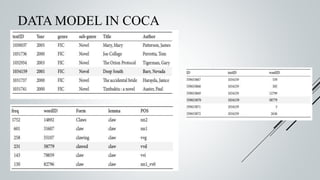




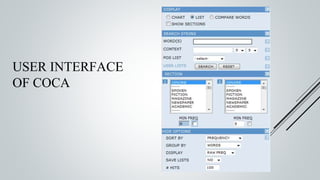
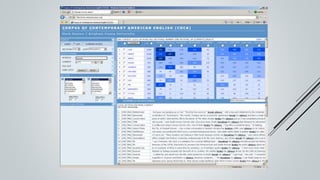
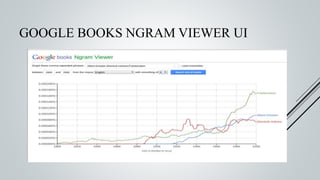





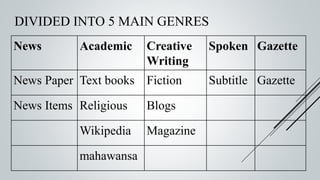




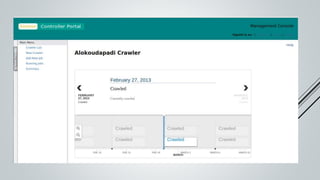



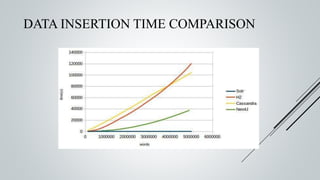
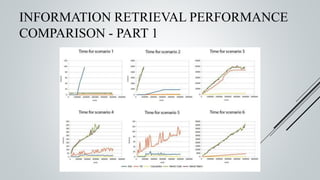
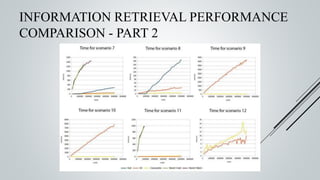


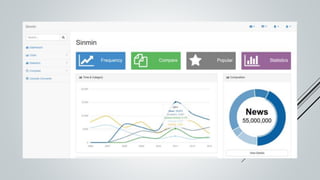
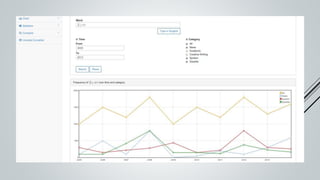






This document provides an overview of the Sinmin corpus project for the Sinhala language. Sinmin aims to be a continuously updating, dynamic corpus that covers both structured and unstructured Sinhala language data. It discusses corpus linguistics and existing Sinhala corpora. The project has identified Sinhala data sources, built crawlers to extract data, and evaluated different database systems for data storage. A user interface and API have been designed. Future work includes completing crawlers, loading data into Cassandra, and connecting the frontend. The goal is to build a large, freely available corpus to support NLP research and applications for Sinhala.































































































