Download to read offline







































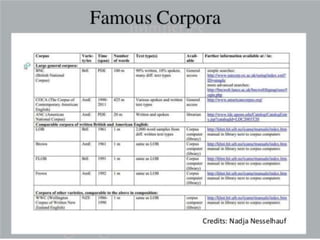






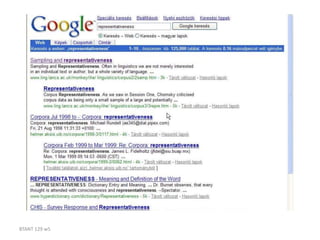
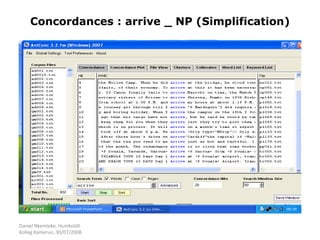























Corpus linguistics is the study of language based on large collections of real-world language samples stored in computer databases called corpora. Corpora allow for the reliable, accurate, and replicable analysis of language at a large scale and in ways not previously possible. A corpus is a collection of written or spoken language samples chosen to represent a variety of language. Corpus linguistics uses computer analysis of corpora to provide insights into language usage patterns based on frequency of phenomena in authentic texts. Key corpora include the British National Corpus and International Corpus of English.























































































