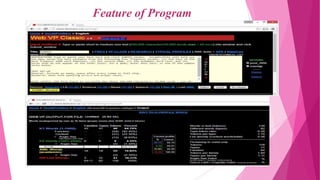
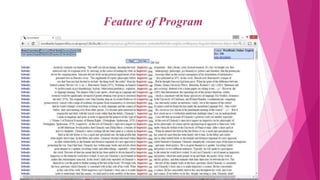
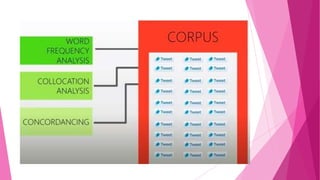
This document discusses corpus linguistics and quantitative research design. It defines a corpus as a large collection of texts used for linguistic analysis. Corpus linguistics allows researchers to empirically test hypotheses about language patterns and features based on large amounts of real-world data. Quantitative analysis of corpus data shows how frequently certain words, constructions, and patterns are used. Specialized corpora can focus on particular text types, languages, or learner language. Various software tools are used to analyze corpora through frequency lists, keyword lists, collocation analysis, and other methods.























![Academic Word List (Coxhead, 2000)
Word selection
What a word is
Morphologically different words (e.g. –s and – ed)
word types
word families
“[a] word family was defined as a stem plus all closely related
affixed forms…” (Coxhead, 2000, p. 218)](https://image.slidesharecdn.com/corpusstudydesign-200722021757/85/Corpus-study-design-26-320.jpg)