











![Copyright (c) 2014 Scale Unlimited.
What's the general approach?
We have web logs with IP addresses, time, path to page
157.55.33.39 - - [18/Mar/2014:00:01:00 -0500]
"GET /solutions/nosql HTTP/1.1"
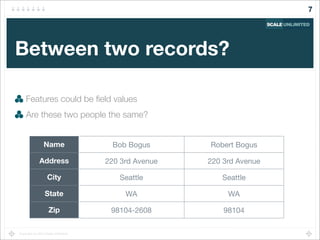
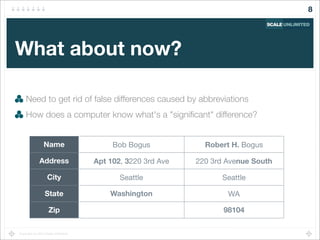
A browsing session is a series of requests from one IP address
With some maximum time gap between requests
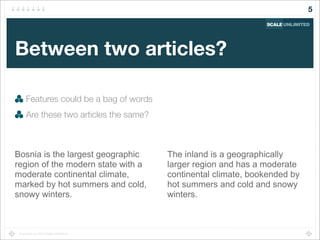
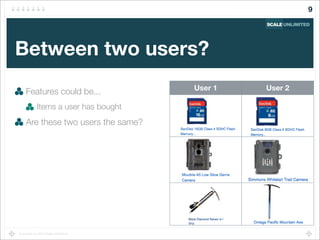
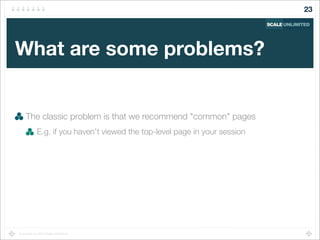
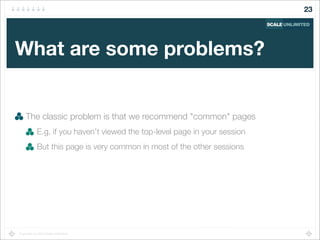
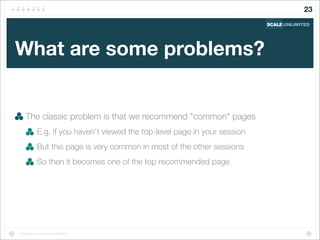
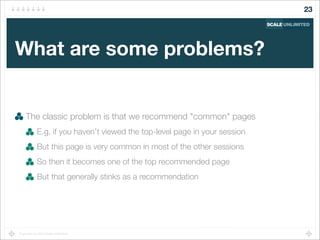
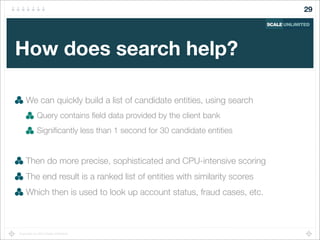
Find sessions "similar to" the current user's session
Recommend pages from these similar sessions
18](https://image.slidesharecdn.com/t-525pm-210c-krugler-140617165757-phpapp02/85/Similarity-at-Scale-18-320.jpg)







































The document discusses techniques for generating recommendations at scale using similarity algorithms. It begins by defining different types of similarity problems like clustering, deduplication, recommendations, and entity resolution. It then discusses what similarity means and how it is different from exact matching. Different algorithms for measuring similarity between objects are described, including Jaccard coefficient and cosine similarity. The challenges of scaling similarity calculations to large datasets are discussed. Recommendation algorithms like analyzing co-occurrence of items in user sessions are explained. The use of Lucene search and the Mahout RowSimilarityJob to calculate item-item similarity matrices for generating related item recommendations are also covered.



































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


















