



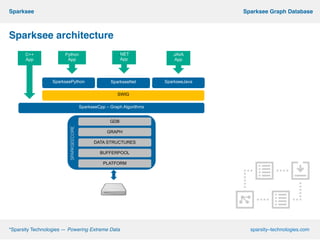
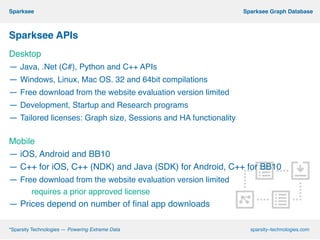
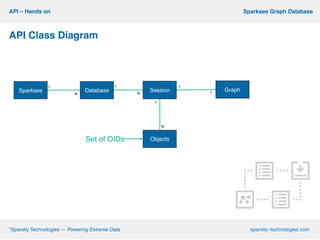

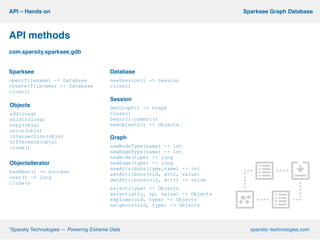
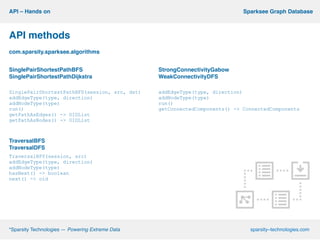

This document describes Sparksee, a graph database created by Sparsity Technologies. Sparksee is designed for large, labeled graphs and uses vertical partitioning and bitmaps to store graph data compactly. It provides high performance for queries and analytics on social networks and bibliographic databases. The document outlines Sparksee's architecture, capabilities including efficiency, capacity, and scalability. It also describes the desktop and mobile APIs available for accessing Sparksee and provides examples of common API methods.














































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)








