Recommended
PPTX
最先端NLP勉強会 Context Gates for Neural Machine Translation
PDF
第三回さくさくテキストマイニング勉強会 入門セッション
PDF
PPT
PPTX
PDF
[DL輪読会]Attention InterpretabilityAcross NLPTasks
PPTX
Nl220 Pitman-Yor Hidden Semi Markov Model
PPTX
PDF
PDF
PDF
トピックモデルの評価指標 Perplexity とは何なのか?
PDF
トピックモデルの評価指標 Coherence 研究まとめ #トピ本
PDF
PDF
トピックモデルによる統計的潜在意味解析読書会 3.7 評価方法 - 3.9 モデル選択 #トピ本
PDF
複数の客観的手法を用いたテキスト含意認識評価セットの構築
PPTX
[Paper Reading] The price of debasing automatic metrics in natural language e...
PDF
Python nlp handson_20220225_v5
PDF
PDF
Summary: A Sense-Based Translation Model for Statistical Machine Translation
PDF
Japan.r 2018 slide ota_20181201
PDF
Sigconf 2019 slide_ota_20191123
PDF
PDF
Building Evaluation Sets for Textual Entailment Recognition
PDF
役所からの公的文書に対する「やさしい日本語」への変換システムへの構築
PDF
【Schoo web campus】「相手に伝わる」文章を書く技術 2限目
PPTX
PDF
09 manual writing20130611sample
PDF
PPTX
Neural Architecture for Named Entity Recognition
PDF
Memory Networks (End-to-End Memory Networks の Chainer 実装)
More Related Content
PPTX
最先端NLP勉強会 Context Gates for Neural Machine Translation
PDF
第三回さくさくテキストマイニング勉強会 入門セッション
PDF
PPT
PPTX
PDF
[DL輪読会]Attention InterpretabilityAcross NLPTasks
PPTX
Nl220 Pitman-Yor Hidden Semi Markov Model
PPTX
What's hot
PDF
PDF
PDF
トピックモデルの評価指標 Perplexity とは何なのか?
PDF
トピックモデルの評価指標 Coherence 研究まとめ #トピ本
PDF
PDF
トピックモデルによる統計的潜在意味解析読書会 3.7 評価方法 - 3.9 モデル選択 #トピ本
PDF
複数の客観的手法を用いたテキスト含意認識評価セットの構築
PPTX
[Paper Reading] The price of debasing automatic metrics in natural language e...
PDF
Python nlp handson_20220225_v5
PDF
PDF
Summary: A Sense-Based Translation Model for Statistical Machine Translation
PDF
Japan.r 2018 slide ota_20181201
PDF
Sigconf 2019 slide_ota_20191123
PDF
PDF
Building Evaluation Sets for Textual Entailment Recognition
PDF
役所からの公的文書に対する「やさしい日本語」への変換システムへの構築
PDF
【Schoo web campus】「相手に伝わる」文章を書く技術 2限目
PPTX
PDF
09 manual writing20130611sample
PDF
Similar to Dynamic Entity Representations in Neural Language Models
PPTX
Neural Architecture for Named Entity Recognition
PDF
Memory Networks (End-to-End Memory Networks の Chainer 実装)
PPTX
[PaperReading]Unsupervised Discrete Sentence Representation Learning for Inte...
PDF
Facebookの人工知能アルゴリズム「memory networks」について調べてみた
PDF
PDF
PPTX
Neural relation extraction for knowledge base enrichment introduced by Yoshia...
PDF
[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」
PPTX
Neural Models for Information Retrieval
PDF
PDF
CV勉強会ICCV2017読み会:Towards Diverse and Natural Image Descriptions via a Conditi...
PDF
東京大学2021年度深層学習(Deep learning基礎講座2021) 第8回「深層学習と自然言語処理」
PPTX
Dynamic Entity Representations in Neural Language Models 1. 2. 概要
• 目標: 参照表現 (Entity) を活用する文章読解モデル
• アプローチ: 言語モデル + 参照表現
• 提案手法: EntityNLM
• 単語予測と同時に,単語の参照先を予測
• 各参照表現には専用の分散表現を生成・更新
• 複数のタスクでベースラインに勝利
• 言語モデル (Perplexity)
• 共参照解析機のn-bestのリランキング
• Entity予測タスク
2
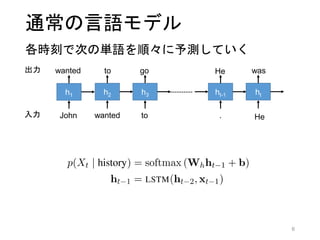
3. 解きたいタスク: 言語モデル
3
John wanted to go to the coffee shop in downtown Copenhagen.
He was told that it sold [xxx] in the whole [xxx]
「xxx」に入る単語列は何か?
4. 解きたいタスク: 言語モデル
• ①参照表現間の共参照関係を把握する
• He=Johnであり,it=the coffee shopである
• ②参照表現の情報を保持する
• the coffee shopだから豆とかコーヒーかな…
• Copenhagenだからヨーロッパとかかな… 4
John wanted to go to the coffee shop in downtown Copenhagen.
He was told that it sold [xxx] in the whole [xxx]
「xxx」に入る単語列は何か?
単語列を予測するために必要なことは?
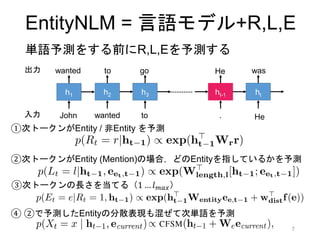
5. アイデア: 単語予測と同時に
共参照解析をする - EntityNLM
5
①参照表現間の共参照関係を把握する
②各参照表現についての情報を保持する
⇛次の単語を予測する際,その単語の共参照関係を同時に予測する
⇛参照表現ごとに専用の分散表現を生成・動的に更新
h1
John
wanted
h2
wanted
to
h3
to
go
ht-1
.
John
The coffee shop
Downtown Copenhagen
John
The coffee shop
Downtown Copenhagen
参照表現ベクトル
サンプリング
文脈に応じて
更新
正規分布
6. 7. 8. 9. 10. 目的関数・最適化手法など
• 目的関数
• 𝑙 𝜃 = 𝑙𝑜𝑔𝑃 𝑅, 𝐸, 𝐿, 𝑋; 𝜃 = 𝑡 𝑙𝑜𝑔𝑃(𝑅𝑡, 𝐸𝑡, 𝐿 𝑡, 𝑋𝑡; 𝜃)
• ハイパーパラメータなど (Devデータで調整)
• AdaGrad (lr=0.1) / Adam (lr=0.001)
• Dropout {0.2, 0.5}
• LSTM Hidden State & Word Embedding
{32,48,64,128,256}
• GloVeによる初期化 / ランダムに初期化
• 実装(by DyNet)は公開されてません
• https://github.com/jiyfeng/entitynlm
• (会議も終わったというのに)
10
11. 12. 実験1: 言語モデル
• データセット: CoNLL2012
• 2802/343/348 文書
• 100万/15万/15万 トークン
• 低頻度語はUNKで置換,数字はNUMで置換
• ボキャブラリ: 約1万語
• ベースライン
• 5-gram 言語モデル [Heafield+ 2013]
• RNN言語モデル with LSTM
• DyNet実装です,とのみ記述あり
12
13. 実験1: 言語モデル
• EntityNLMはベースラインよりも高性能
• ベースラインが弱すぎるのではないか?
• 「提案手法は普通の言語モデルとしても使える」
としか言えないのでは?
• 言語モデルの評価によく使われるMikolovPTBの場合:
• 総トークン数90万 / 語彙1万 / UNK&NUM置換アリ
• LSTM [Zaremba+ 2014]でPerplexity 78.4 13
Perplexityで評価
14. 実験2: 共参照解析のリランキング
• EntityNLMは P(R,E,L,X)を計算可能
• i.e. 各Coreference Chainに対して確率値が求まる
• 共参照解析機の出力のリランキングが可能
• 共参照解析機にはCORT [Martschat+ 2015]を使用
した
• 今回は 𝒦 = 100とした
• 𝒦 = 500としても性能は上がらなかった
14
𝒦: 共参照解析機の出力したk-best
15. 16. 17. Editor's Notes #4 Inputが何で,何を当てたいのか?
INPUT: f(John wanted to go to the coffee shop in downtown Copenhagen. He was told that it sold )
ここに何が入るかを当てたい,つまり言語モデルです
CorefにおけるEntity Mentionのこと
Entityの定義を最初に言う
CONLL2012のアノテーションガイドラインor 井上尚弥
最終的な目標: より良い言語モデル
#5 Inputが何で,何を当てたいのか?
INPUT: f(John wanted to go to the coffee shop in downtown Copenhagen. He was told that it sold )
ここに何が入るかを当てたい,つまり言語モデルです
CorefにおけるEntity Mentionのこと
Entityの定義を最初に言う
CONLL2012のアノテーションガイドラインor 井上尚弥
最終的な目標: より良い言語モデル




![解きたいタスク: 言語モデル
3
John wanted to go to the coffee shop in downtown Copenhagen.
He was told that it sold [xxx] in the whole [xxx]
「xxx」に入る単語列は何か?](https://image.slidesharecdn.com/snlp-170910121009/85/Dynamic-Entity-Representations-in-Neural-Language-Models-3-320.jpg)
![解きたいタスク: 言語モデル
• ①参照表現間の共参照関係を把握する
• He=Johnであり,it=the coffee shopである
• ②参照表現の情報を保持する
• the coffee shopだから豆とかコーヒーかな…
• Copenhagenだからヨーロッパとかかな… 4
John wanted to go to the coffee shop in downtown Copenhagen.
He was told that it sold [xxx] in the whole [xxx]
「xxx」に入る単語列は何か?
単語列を予測するために必要なことは?](https://image.slidesharecdn.com/snlp-170910121009/85/Dynamic-Entity-Representations-in-Neural-Language-Models-4-320.jpg)





![実験1: 言語モデル
• データセット: CoNLL2012
• 2802/343/348 文書
• 100万/15万/15万 トークン
• 低頻度語はUNKで置換,数字はNUMで置換
• ボキャブラリ: 約1万語
• ベースライン
• 5-gram 言語モデル [Heafield+ 2013]
• RNN言語モデル with LSTM
• DyNet実装です,とのみ記述あり
12](https://image.slidesharecdn.com/snlp-170910121009/85/Dynamic-Entity-Representations-in-Neural-Language-Models-12-320.jpg)
![実験1: 言語モデル
• EntityNLMはベースラインよりも高性能
• ベースラインが弱すぎるのではないか?
• 「提案手法は普通の言語モデルとしても使える」
としか言えないのでは?
• 言語モデルの評価によく使われるMikolovPTBの場合:
• 総トークン数90万 / 語彙1万 / UNK&NUM置換アリ
• LSTM [Zaremba+ 2014]でPerplexity 78.4 13
Perplexityで評価](https://image.slidesharecdn.com/snlp-170910121009/85/Dynamic-Entity-Representations-in-Neural-Language-Models-13-320.jpg)
![実験2: 共参照解析のリランキング
• EntityNLMは P(R,E,L,X)を計算可能
• i.e. 各Coreference Chainに対して確率値が求まる
• 共参照解析機の出力のリランキングが可能
• 共参照解析機にはCORT [Martschat+ 2015]を使用
した
• 今回は 𝒦 = 100とした
• 𝒦 = 500としても性能は上がらなかった
14
𝒦: 共参照解析機の出力したk-best](https://image.slidesharecdn.com/snlp-170910121009/85/Dynamic-Entity-Representations-in-Neural-Language-Models-14-320.jpg)
![実験2:共参照解析のリランキング
• CoNLLスコア上では1%性能が向上した
• CORTのスコアとの線形和をすると一番良い
• CORT自体の性能も低いのでは?
15
[Clark+ 2016]](https://image.slidesharecdn.com/snlp-170910121009/85/Dynamic-Entity-Representations-in-Neural-Language-Models-15-320.jpg)
![既存研究: 外部メモリを持つような
言語モデル
• 外部メモリを持つような言語モデルはこれまで
にも提案されている
• 参照表現にに限らない”general contextual
information”を保持するモデル
• 例: Recurrent Memory Network [Tran+ 2016]
• (これらは共参照関係をImplicitに取り扱っていると
見ることもできるはず)
• 提案手法(EntityNLM)は個々の参照表現に
専用の分散表現を付与するようなモデル
• (共参照のタグ付きデータが少ないから今までやら
れなかった,という側面もありそう…)
16](https://image.slidesharecdn.com/snlp-170910121009/85/Dynamic-Entity-Representations-in-Neural-Language-Models-16-320.jpg)






![[DL輪読会]Attention InterpretabilityAcross NLPTasks](https://cdn.slidesharecdn.com/ss_thumbnails/dlrindokukai-190927013932-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Paper Reading] The price of debasing automatic metrics in natural language e...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreading-20181012-shinoda-181013064855-thumbnail.jpg?width=640&height=640&fit=bounds)














![[PaperReading]Unsupervised Discrete Sentence Representation Learning for Inte...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreading-20180702shinoda-180702111612-thumbnail.jpg?width=640&height=640&fit=bounds)




![[旧版] JSAI2018 チュートリアル「"深層学習時代の" ゼロから始める自然言語処理」](https://cdn.slidesharecdn.com/ss_thumbnails/jsai2018tutorialslideshare-180606065226-thumbnail.jpg?width=640&height=640&fit=bounds)




