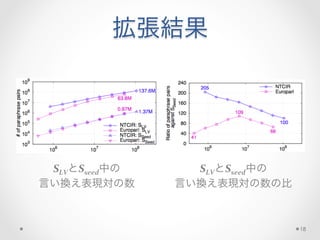
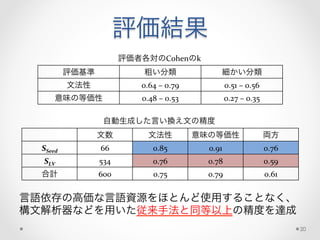
提案手法
Amendment
of
regulation
amending
regulation
X
:
ment
of
Y
:
ϕ ⇔ X : ing Y : ϕ
investment
of
resources
investing
resources
recruitment
of
engineers
recruiting
engineers
• 上記のような元々の対とは表層的に全く異なる語で構成
される対も得られる。
9
10.
着目する語群
• 派生語
o 表記や意味の一部を共有する異なる語の群
{“develop”,
“developer”,
“development”,
…}
• 活用形/屈折形
o 活用や屈折に由来する同じ語の異なる出現形
{“amend”,
“amends”,
“amending”,
…}
• 異表記
o 同じ語の同じ活用形/屈折形の異なる表記
{“color”,
“colour”},
{“authorize”,
“authorise”,
…}
10
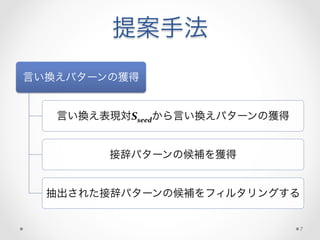
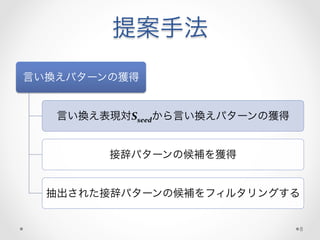
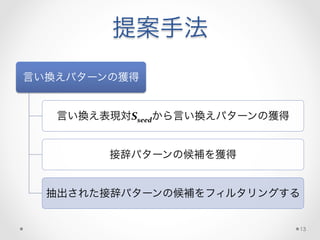
提案手法
• 高品質なSseedを前提として
• 言い換え表現対の各辺にあり、同じ語幹をもつ語の対は、
特定の(意味的な)関係を持つ
語1 語2 接辞1 接辞2 語幹
aimed
aimed
achieving
achieving
aims
achieve
aims
achieve
X
:
ed
X
:
imed
X
:
chieving
X
:
ing
X
:
s
X
:
chieve
X
:
ims
X
:
e
aim
a
a
achiev
12
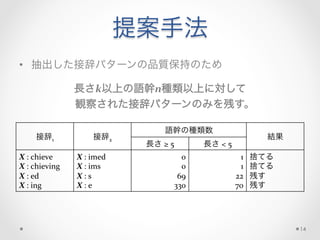
提案手法
• 抽出した接辞パターンの品質保持のため
長さk以上の語幹n種類以上に対して
観察された接辞パターンのみを残す。
接辞1 接辞2
語幹の種類数
結果
長さ
≥
5
長さ
<
5
X
:
chieve
X
:
chieving
X
:
ed
X
:
ing
X
:
imed
X
:
ims
X
:
s
X
:
e
0
0
69
330
1
1
22
70
捨てる
捨てる
残す
残す
14
コーパス
• Europarl
o 英仏対200万文(英語5570万語、仏語6190万語)
o 使用したコーパス
• 英語側とNews
Crawl
5,200万文、12.0億語
• NTCIR
o 日英対320万文(英語1.07億語、日本語1.16億形態素)
o 使用したコーパス
• 英語側とNTCIRの単言語文書3,990万文、13.6億語
16
17.
問題点
People
of
Europe
European
population
People
of
X
:
ϕ
⇔
X
:
an
population
単言語コーパスで同じ関係を持つ
(“Haiti”,
”Haitian”),
(“suburb”,
“suburban”)だけでなく
(“uncle”,
“unclean”)など語の意味ではなく、語の形だけで
抽出されてしまう
文脈類似度を単言語コーパスから計算して、置き換え出来
ないような対を除外する
17
考察
文法カテゴリの変化
• The
safety
issue
was
considered
sufficiently
serious
for
all
affected
parties
to
be
informed
• The
safety
issue
was
sufficient
consideration
serious
for
all
affected
parties
to
be
informed
数や冠詞の違い
• There
are
tons
of
potential
buyers
of
military
weapons
• There
are
a
potential
buyer
of
military
weapons
21