Recommended
PDF
PPTX
PDF
畳み込みニューラルネットワークが なぜうまくいくのか?についての手がかり
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
PPTX
物体検出の歴史(R-CNNからSSD・YOLOまで)
PDF
PDF
Attentionの基礎からTransformerの入門まで
PPTX
【論文読み会】Pyraformer_Low-Complexity Pyramidal Attention for Long-Range Time Seri...
PPTX
TalkingData AdTracking Fraud Detection Challenge (1st place solution)
PDF
PDF
PDF
PPTX
PPTX
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
PDF
PPTX
表形式データで高性能な予測モデルを構築する「DNNとXGBoostのアンサンブル学習」
PPTX
大域的探索から局所的探索へデータ拡張 (Data Augmentation)を用いた学習の探索テクニック
PPTX
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」
PPTX
論文紹介: "MolGAN: An implicit generative model for small molecular graphs"
PDF
[DL輪読会]EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning
PPTX
Ponanzaにおける強化学習とディープラーニングの応用
PPTX
Image Retrieval Overview (from Traditional Local Features to Recent Deep Lear...
PDF
PDF
RDF Semantic Graph「RDF 超入門」
PDF
Cv勉強会cvpr2018読み会: Im2Flow: Motion Hallucination from Static Images for Action...
PDF
PDF
Overcoming Catastrophic Forgetting in Neural Networks読んだ
PDF
PDF
More Related Content
PDF
PPTX
PDF
畳み込みニューラルネットワークが なぜうまくいくのか?についての手がかり
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
PPTX
物体検出の歴史(R-CNNからSSD・YOLOまで)
PDF
PDF
Attentionの基礎からTransformerの入門まで
PPTX
【論文読み会】Pyraformer_Low-Complexity Pyramidal Attention for Long-Range Time Seri...
What's hot
PPTX
TalkingData AdTracking Fraud Detection Challenge (1st place solution)
PDF
PDF
PDF
PPTX
PPTX
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
PDF
PPTX
表形式データで高性能な予測モデルを構築する「DNNとXGBoostのアンサンブル学習」
PPTX
大域的探索から局所的探索へデータ拡張 (Data Augmentation)を用いた学習の探索テクニック
PPTX
東京大学2020年度深層学習(Deep learning基礎講座) 第9回「深層学習と自然言語処理」
PPTX
論文紹介: "MolGAN: An implicit generative model for small molecular graphs"
PDF
[DL輪読会]EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning
PPTX
Ponanzaにおける強化学習とディープラーニングの応用
PPTX
Image Retrieval Overview (from Traditional Local Features to Recent Deep Lear...
PDF
PDF
RDF Semantic Graph「RDF 超入門」
PDF
Cv勉強会cvpr2018読み会: Im2Flow: Motion Hallucination from Static Images for Action...
PDF
PDF
Overcoming Catastrophic Forgetting in Neural Networks読んだ
Viewers also liked
PDF
PDF
PDF
ABC 2012 Spring Robot Summit
PDF
PDF
PDF
ET2016 小さなRubyボード GR-CITRUSの紹介
PDF
PDF
Similar to スペル修正プログラムの作り方 #pronama
PPT
PDF
PDF
Effective search space reduction for spell correction using character neural ...
PPT
PDF
PDF
PDF
Web フィルタリング最前線: 「「検閲回避」回避」 角田孝昭
PPTX
PDF
構文情報に基づく機械翻訳のための能動学習手法と人手翻訳による評価
PPTX
英語学習者の文法的誤りをめぐって: 最近の動向とエッセイ自動評価のための基礎的検討.
PPTX
COLING2014 読み会@小町研 “Morphological Analysis for Japanese Noisy Text Based on C...
PDF
PDF
アルゴリズムのお勉強 アルゴリズムとデータ構造 [素数・文字列探索・簡単なソート]
PPTX
A Monolingual Tree-based Translation Model for Sentence Simplification
PDF
PDF
論文紹介:Improve smt quality with automatically extracted paraphrase rules
PDF
Segmenting Sponteneous Japanese using MDL principle
PDF
PDF
Paraphrasing rules for automatic evaluation of translation into japanese
PDF
スペル修正プログラムの作り方 #pronama 1. 2. 自己紹介
・名前は とろとき
・ 言 語 は P ython/ P erl/ Ja v a
( @t o r o t ki) ・ A nd roid と か 自 然 言 語 処 理 、
機械学習などを勉強中。
・中学生
3. 4. はじめに
・自然言語処理について
・コンピュータでテキストを 分析 させる試み
・ Micr o so ft の 選 ぶ 、 10年 後 テ ク ノ ロ ジ ー 分 野 で ホ ッ ト な 職 業 !
・ The Top Three hottest new majors for a career in technology
D at a Mining/ Mac hine Lear ning/ AI / Nat ur al Language P r oc essing
( デ ー タ マ イ ニ ン グ / 機 械 学 習 / 人工 知 能 / 自 然 言 語 処 理 ) ← コ レ
B usiness I nt elligenc e/ C ompet it ive I nt elligenc e
(ビジネスインテリジェンス/競合調査)
Analy t ic s/ S t at ist ic s
(分析/統計)
Mi cr osoft JobsBl og より引用
ht t p:/ / j obsbl og.com/ bl og/ t op- t hr e e - ne w- t e ch- m aj or s/
5. 6. 1/ 4 単語の辞書を用意
辞書選び
何種類も無料で配布されてる
単 語 だ け が 必 要 な の で 、 基 本 的 に ど れ で も OK
主要なものはこの三つ
IPA - dic
N A IS T - dic
U n iD ic
単 語 数 は N A IS T - dic < U n iD ic < IPA - dic
・ 今 回 は IPA - dicを 使 用 ( Me Ca bに 付 属 し て い た せ い )
7. 1/ 4 単語の辞書を用意
辞 書 の 中 身 ( IPA - dicの 場 合 )
きらびやか,1287,1287,8349,名詞,形容動詞語幹,*,*,*,*,きらびやか,キラビヤカ,キラビヤカ
史的,1287,1287,6608,名詞,形容動詞語幹,*,*,*,*,史的,シテキ,シテキ
プラトニック,1287,1287,5077,名詞,形容動詞語幹,*,*,*,*,プラトニック,プラトニック,..(略)
てらてら,1287,1287,8349,名詞,形容動詞語幹,*,*,*,*,てらてら,テラテラ,テラテラ
静謐,1287,1287,4845,名詞,形容動詞語幹,*,*,*,*,静謐,セイヒツ,セイヒツ
今回はここしか使わない
8. 9. 10. 11. 3/ 4 誤字を辞書と比較
編集距離の例
誤字 単語
・挿入: スペルミッス → スペルミス
・削除: スペミス → スペルミス
・置換: スプルミス → スペルミス
・転置: スペミルス → スペルミス
12. 13. 14. 3/ 4 誤字を辞書と比較
・問題点
漢字が多すぎて実用的じゃない(アルファベットだけなら大丈夫)
毎 回 20万 語 と 比 較 し な き ゃ い け な い
3文 字 の 比 較 量 は 1回 の 編 集 距 離 だ け で
{(5, 000* 4)+3+(5, 000* 3)+3}* 200, 000 = 7, 001, 200, 000回
15. 16. 3/ 4 誤字を辞書と比較
・ N -g r am で 修 正 候 補 の 絞 り 込 み
N - gr a mっ て ?
文字をN個ずつ切り出すという意味
自然言語処理にいろいろと使われてる。
と ろ と き = [と ろ ][ろ と ][と き ]
Nの個数で名前が変わる
1 文 字 ・・・ ユ ニ グ ラ ム [ と ] [ ろ ] [ と ] [ き ]
2 文 字 ・・・ バ イ グ ラ ム [ と ろ ] [ ろ と ] [ と き ]
3 文 字 ・・・ ト リ グ ラ ム [ と ろ と ] [ ろ と ろ ] [ と き ]
単 純 に N - gr a mと い え ば 基 本 的 に バ イ グ ラ ム ( 2文 字 ず つ )
・例外にもれず今回はバイグラムを使用
17. 3/ 4 誤字を辞書と比較
・ N -g r am で 修 正 候 補 の 絞 り 込 み
どうやって絞り込むの?
辞 書 か ら 全 単 語 の N - gr a mイ ン デ ッ ク ス を 作 る
いう あ い う ち , あ っ と い う 間 , ね ら い う ち , ..
ごり に ご り 酒 , お ご り , 名 ご り , ご り ご り , ..
次官 次官, 政治次官, 次官補, 事務次官
18. 3/ 4 誤字を辞書と比較
・ N -g r am で 修 正 候 補 の 絞 り 込 み
どうやって絞り込むの?
入力 データベaス → デー + ータ + タベ + ベa + aス
N - gr a mイ ン デ ッ ク ス で 複 数 回 ヒ ッ ト す る も の
デ ー : " デ ー タ テ レ ホ ン " , " デ ー タ セ ッ ト " , " デ ータ タ ブ レ ッ ト " , " デ ー タ ベ ー ス "
ータ : "インバータ", "データベース","オータックス", "ポータブル",
タベ : "ベタベタ", "データベース", "ヌタベット", "カンタベリー",
ベa : ...
aス : ...
参 考 : http: / / www.slideshare.net/naoya1977/spell-correction
19. 3/ 4 誤字を辞書と比較
・編集距離にも工夫
N - gr a mを 使 っ て 候 補 を 減 ら す ( 4つ に 絞 っ た と 仮 定 ) こ と で
比較量を
{(5, 000* 4)+3+(5, 000* 3)+3}* 200, 000 = 7, 001, 200, 000回
から
{(5, 000* 4)+3+(5, 000* 3)+3}* 4 = 140, 024回
にまで減らすことができた。
・ た だ し こ れ は 編 集 距 離 が 1回 ま で の 話
( smt h in g → so me t h in g) な ど が で き て い な い
編集距離を少しでも多く出すためには?
20. 3/ 4 誤字を辞書と比較
・編集距離にも工夫
挿入 削除 置換 転置
{(5, 000* 4)+3+(5, 000* 3)+3}* 4 = 140, 024回
編集距離の計算で回数を多くしているのは
5, 000* 4( 挿 入 ) と 5, 000* 3( 置 き 換 え ) の 式
※ 5,000 は漢字及びひらがなとカタカナの数
2回 目 以 降 に 編 集 距 離 を 求 め る と き は 、
挿入 置き換え の作業を消せばよいのでは?
21. 3/ 4 誤字を辞書と比較
・編集距離にも工夫
2回 目 以 降 は 挿 入 と 置 換 を 求 め な い こ と で
({(5, 000* 4)+3+(5, 000* 3)+3} * 4 * {(3+3)* 4} = 3, 360, 576回
と 編 集 距 離 2も ギ リ ギ リ 求 め ら れ る く ら い に で き る
( た だ し や っ て み た と こ ろ 4 6秒 の 時 間 が か か っ た )
言語を変える、並列化する、などして高速化の必要あり?
22. 3/ 4 誤字を辞書と比較
・編集距離が同じ場合の対処
go o lに 対 し て 編 集 距 離 が 1
go a l / go o / go o d / . . .
ス ペ ル ミ ス の 80 95%は 編 集 距 離 が 1ら し い [ 要 出 典 ]
・文章の出現頻度が高い語ほど正解に近いとする(DF)
go o dの 頻 度 が 高 い → go o dが 正 解 と 推 測
で も go a lが 正 解 で も お か し く な い じ ゃ ん !
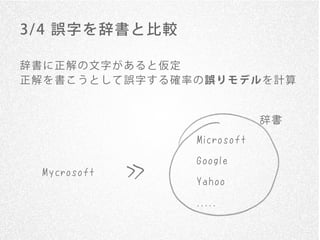
23. 3/ 4 誤字を辞書と比較
・短い単語は求めにくい
go o l は ス ペ ル ミ ス だ け ど 、 「 go o d」 が 正 解 と は い い に く い
実は結構難しい問題
・ そ も そ も 短 い 語 に 対 し て は Go o gle す ら で き て な い
「もしかして」が出てない図
24. 3/ 4 誤字を辞書と比較
・短い単語は求めにくい
・ 応 急 策 ( そ の 1)
I mpro v ed E rro r M o del( ち ょ っ と だ け 取 り 入 れ )
単語の先頭は誤りにくいよね?
・ 先 頭 、 中 間 、 最 後 の 3値 で 計 算
・ た だ し 、 ま だ go o l→ go o d の 問 題 は 解 決 で き な い 。
むしろ悪化
25. 3/ 4 誤字を辞書と比較
・応急策その2
置換操作の文字によって優先順位をつける
- 「a」と「n」は間違えにくい
- 「 p」 と 「 o 」 は 間 違 え や す い
- こ れ だ と go o l→ go o d問 題 は 解 決 で き そ う だ け ど ・・・。
- 当然、漢字は不可
26. 3/ 4 誤字を辞書と比較
A sp e lling C orre ction p rog ram b ase d on a
noisy channe l mod e l( M . Ke rnig han1 9 9 0 )
・応急策その2
27. 3/ 4 誤字を辞書と比較
・まとめ
・まず誤字かどうか判別
・ N - gr a mで 候 補 を 絞 る
・絞った候補と入力文字の編集距離を計算
- 候補が被ったら最も一般的な語を使う
・最も数値の高かった候補を出す
28. 29. 豆 知識的 な 応用 事例
・ N -g r am
N - gr a mに よ る 誤 字 候 補 の 絞 り
- 類似文字の索引にも使える
- コピペ論文を検出する論文まであった
剽窃レポート発見に利用する1文単位での検索クエリ作成手法
http: / / c i. nii. ac . jp/ naid/ 1 1 0 0 0 7 4 6 7 2 4 8
30. 豆 知識的 な 応用 事例
・ EM-b ased Er r or Mod el
E M- ba se d E r r o r Mo de l
・検索エンジンからスペルミスを機械学習
・あまり詳しくない
・引用すると
・(検索エンジンの)クエリログからクエリの訂正を行う
・誤りと正解のペアデータは必要ない
・ ク エ リ ロ グ は 10 15%の ス ペ ル ミ ス を
含むので、ここから学習
引 用 : ス ペ ル 訂 正 エ ン ジ ン に つ い て の サ ー ベ イ # T okyoN LP
http : / / www. slid e share . ne t/ nokuno/ tokyonlp 0 5 -sp e ll-corre ction
31. 32. 参考文献
・「入門自然言語処理」
オ ラ イ リ ー ジ ャ パ ン 2010年 11月 発 行 , 592ペ ー ジ
・スペル修正プログラムはどう書くか
h t t p: //bit . ly/c3B H f
・スペルミス修正プログラムを作ろう
h t t p: //slide sh a . r e /qgh ImL
・スペル訂正エンジンのサーベイ
h t t p: //slide sh a . r e /g7S ImR















![3/ 4 誤字を辞書と比較
・ N -g r am で 修 正 候 補 の 絞 り 込 み
N - gr a mっ て ?
文字をN個ずつ切り出すという意味
自然言語処理にいろいろと使われてる。
と ろ と き = [と ろ ][ろ と ][と き ]
Nの個数で名前が変わる
1 文 字 ・・・ ユ ニ グ ラ ム [ と ] [ ろ ] [ と ] [ き ]
2 文 字 ・・・ バ イ グ ラ ム [ と ろ ] [ ろ と ] [ と き ]
3 文 字 ・・・ ト リ グ ラ ム [ と ろ と ] [ ろ と ろ ] [ と き ]
単 純 に N - gr a mと い え ば 基 本 的 に バ イ グ ラ ム ( 2文 字 ず つ )
・例外にもれず今回はバイグラムを使用](https://image.slidesharecdn.com/pronama10slide-110904073813-phpapp01/85/pronama-16-320.jpg)





![3/ 4 誤字を辞書と比較
・編集距離が同じ場合の対処
go o lに 対 し て 編 集 距 離 が 1
go a l / go o / go o d / . . .
ス ペ ル ミ ス の 80 95%は 編 集 距 離 が 1ら し い [ 要 出 典 ]
・文章の出現頻度が高い語ほど正解に近いとする(DF)
go o dの 頻 度 が 高 い → go o dが 正 解 と 推 測
で も go a lが 正 解 で も お か し く な い じ ゃ ん !](https://image.slidesharecdn.com/pronama10slide-110904073813-phpapp01/85/pronama-22-320.jpg)












![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning](https://cdn.slidesharecdn.com/ss_thumbnails/slidev2reduced-190422065109-thumbnail.jpg?width=640&height=640&fit=bounds)



























![アルゴリズムのお勉強 アルゴリズムとデータ構造 [素数・文字列探索・簡単なソート]](https://cdn.slidesharecdn.com/ss_thumbnails/random-160606142552-thumbnail.jpg?width=640&height=640&fit=bounds)






