Downloaded 116 times













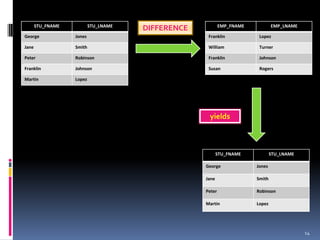















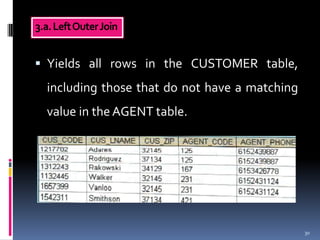







The document describes eight relational operators: SELECT, PROJECT, JOIN, INTERSECT, UNION, DIFFERENCE, PRODUCT, and DIVIDE. It provides examples of how each operator manipulates data from one or more tables by selecting, combining, or relating their contents.






















































































