Downloaded 10 times




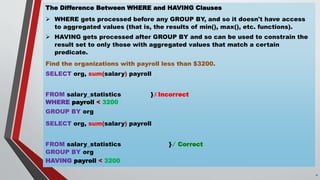
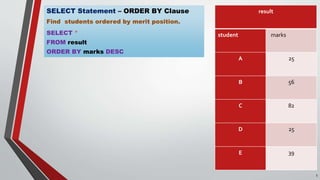

The document explains SQL concepts including the GROUP BY, HAVING, and ORDER BY clauses, illustrating how to group and filter data from a salary statistics table. It highlights the difference between WHERE and HAVING clauses, noting that WHERE is applied before grouping, and HAVING can filter results based on aggregated values. Additionally, it provides examples of SQL queries to analyze payroll and student results.































![Sql query [select, sub] 4](https://cdn.slidesharecdn.com/ss_thumbnails/sqlqueryselectsub4-111119075704-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
















































