Download as PDF, PPTX







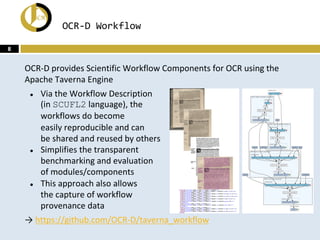












The OCR-D project is an open-source framework aimed at enhancing OCR capabilities for historical printed documents, leveraging advancements in artificial intelligence to meet the growing demand for high-quality text corpora. The project, funded until 2020, involves a coordination project and eight specific modules that focus on various OCR-related tasks such as image optimization, layout analysis, and automated postcorrection. Documentation and specifications are openly available, supporting sustainable and reproducible workflows for the digital humanities community.



































































