Download to read offline






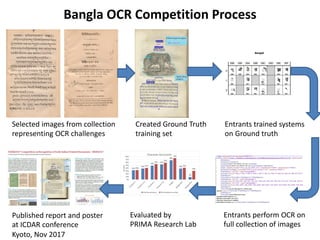
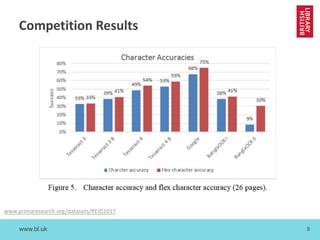
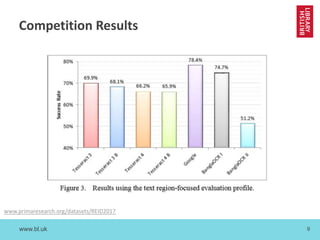

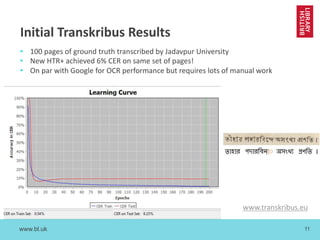









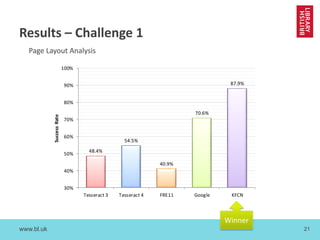
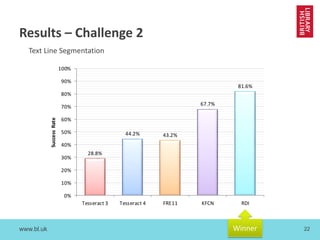
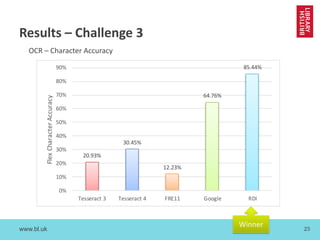




The document discusses cross-disciplinary collaborations aimed at enhancing access to non-Western language materials, specifically focusing on South Asian printed books and Arabic manuscripts within the British Library's digital collections. It details challenges in optical character recognition (OCR) for Bengali and Arabic scripts, including unique characteristics of the scripts and results from various competitions and initiatives aimed at improving OCR accuracy. Future plans include further training of OCR software, as well as workshops in South Asia to continue enhancing the accessibility and usability of these historical texts.



































































