Download to read offline








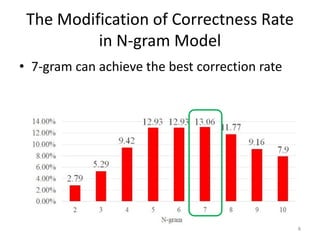
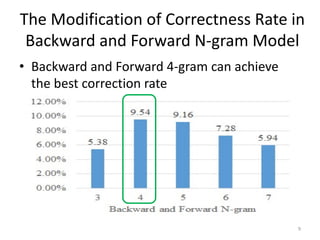

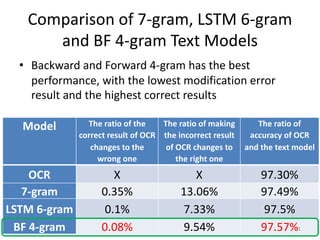






This document discusses using text models to improve the accuracy of optical character recognition (OCR) on Chinese rare books. It conducted experiments using n-gram, backward/forward n-gram, and LSTM models on OCR data from ancient medicine books. The backward and forward 4-gram model achieved the highest correction rate at 97.57%. Mixing the LSTM 6-gram model with the OCR's top 5 candidates and probability of the top candidate further improved accuracy to 97.71%, demonstrating that combining text models with OCR probabilities can better correct OCR errors than text models alone. In conclusion, text models are effective for increasing OCR accuracy on rare books, with backward/forward 4-gram and LSTM 6-gram
























































