Download to read offline


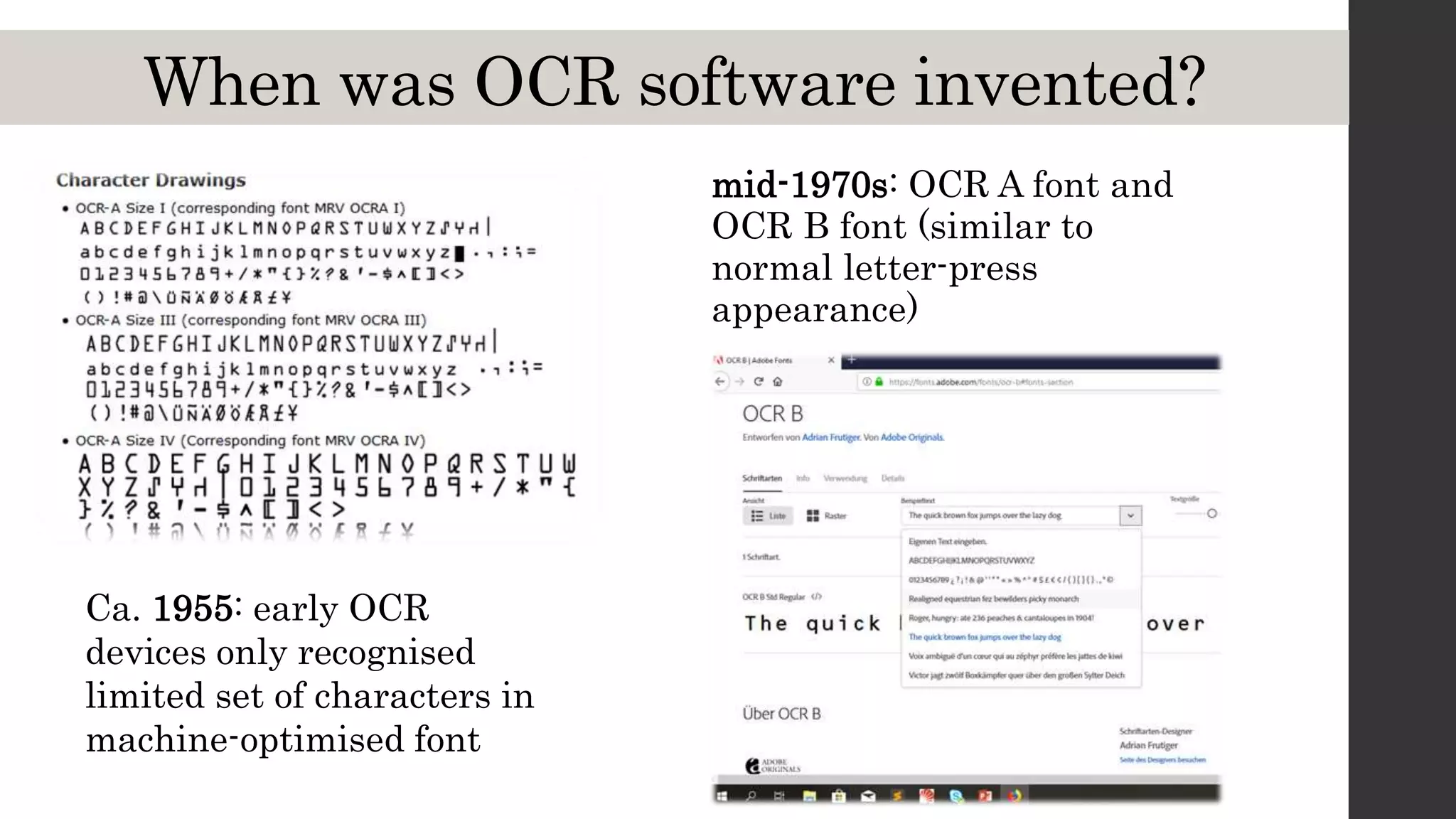

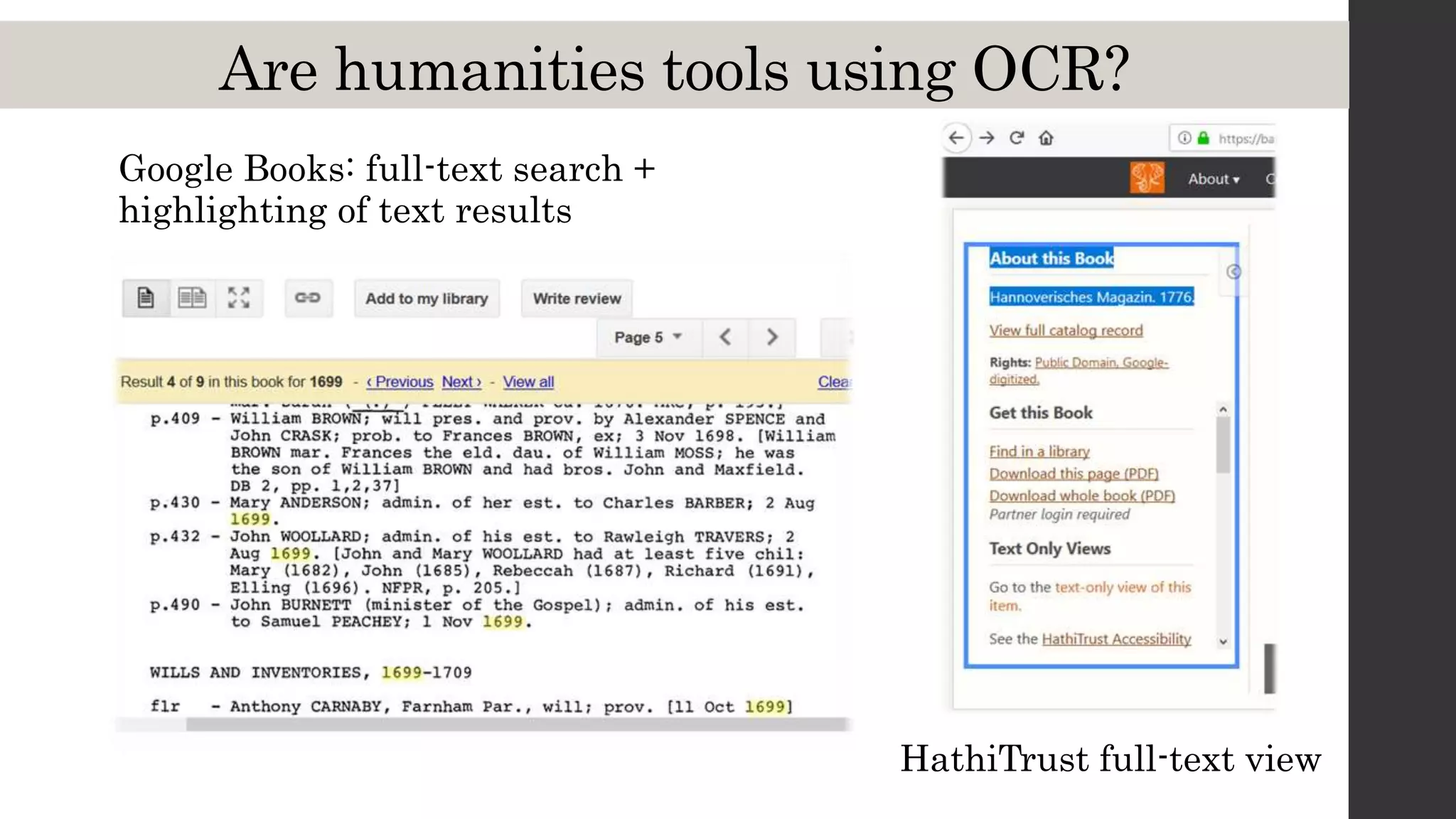
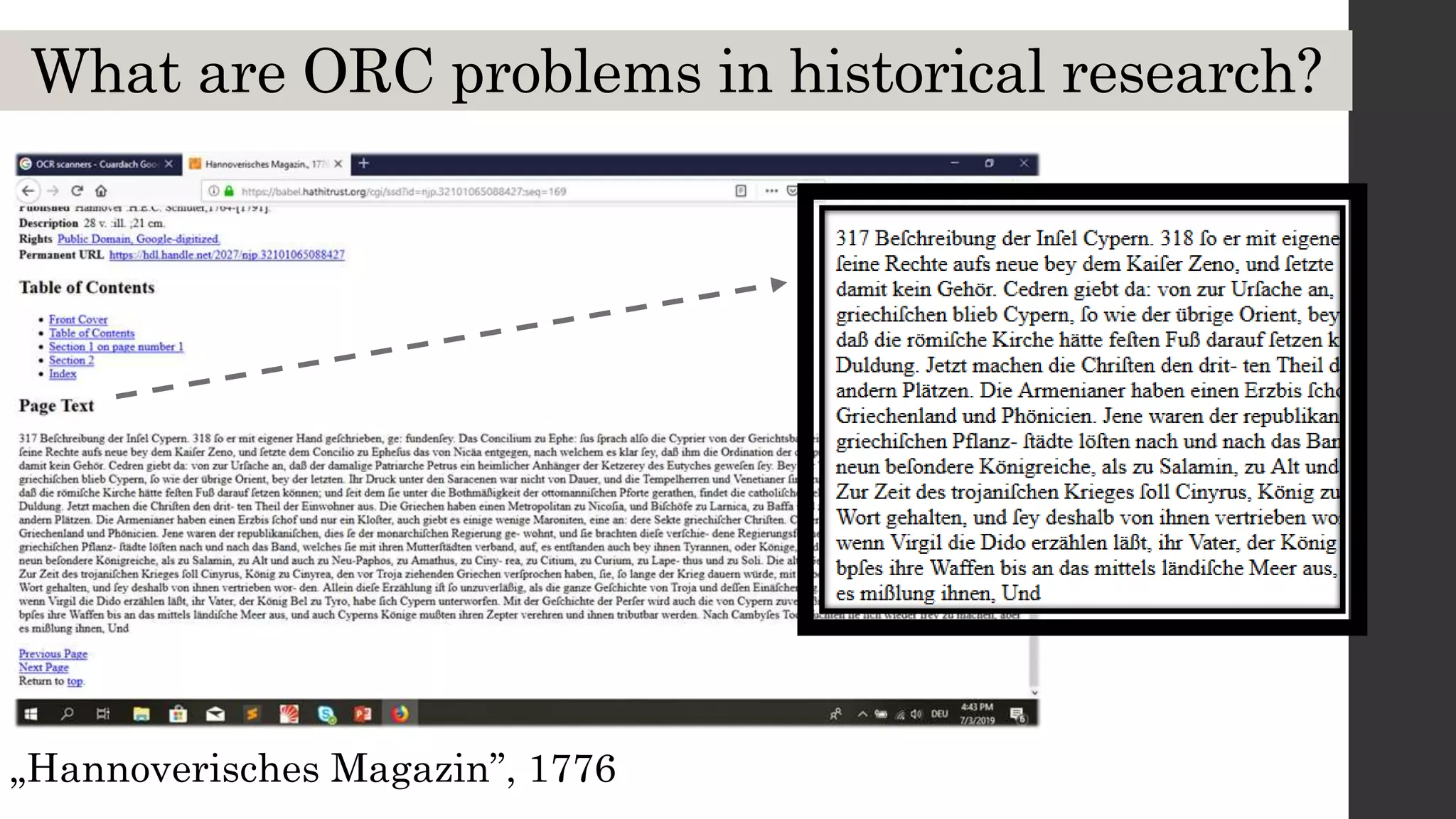

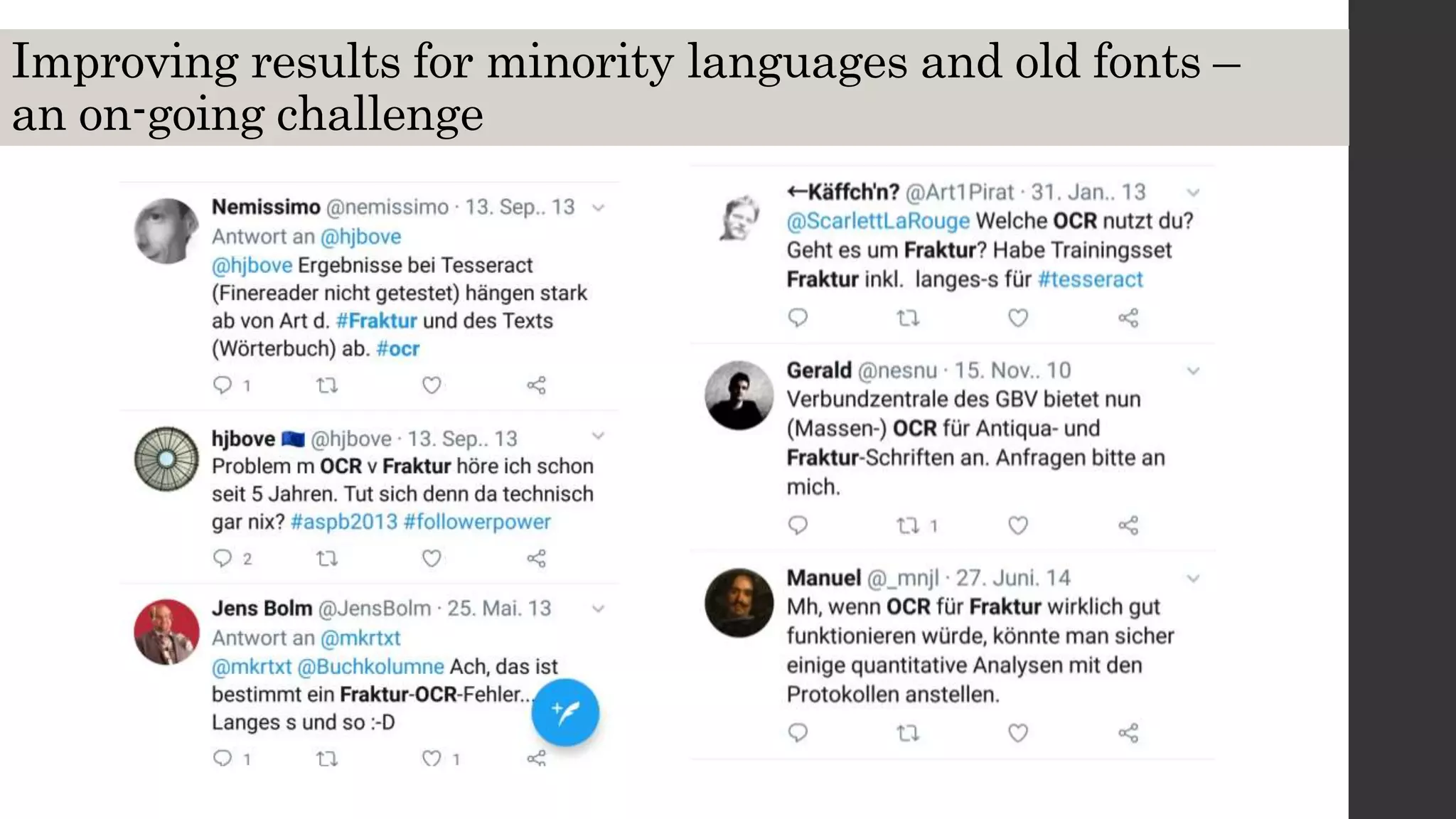



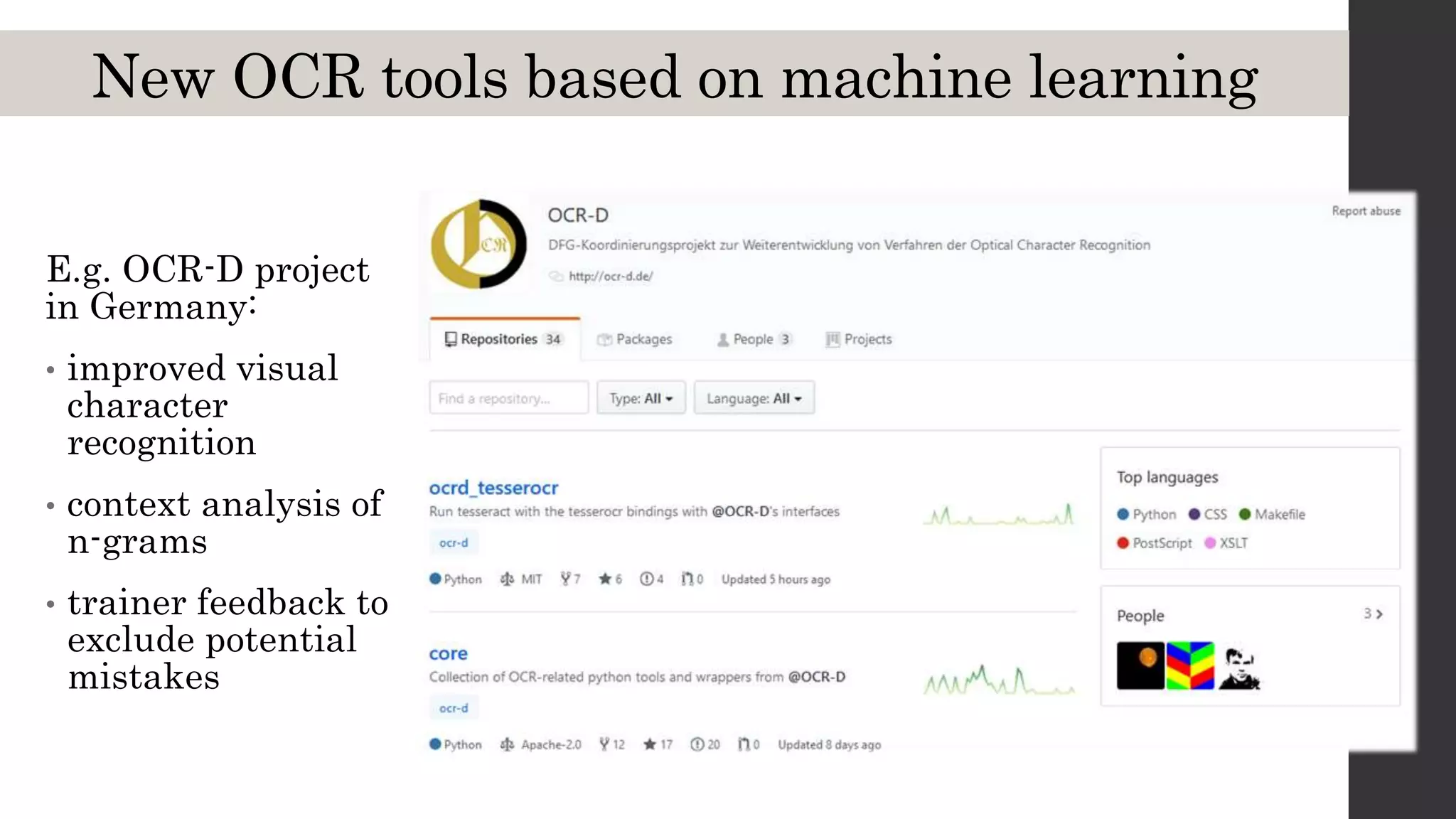



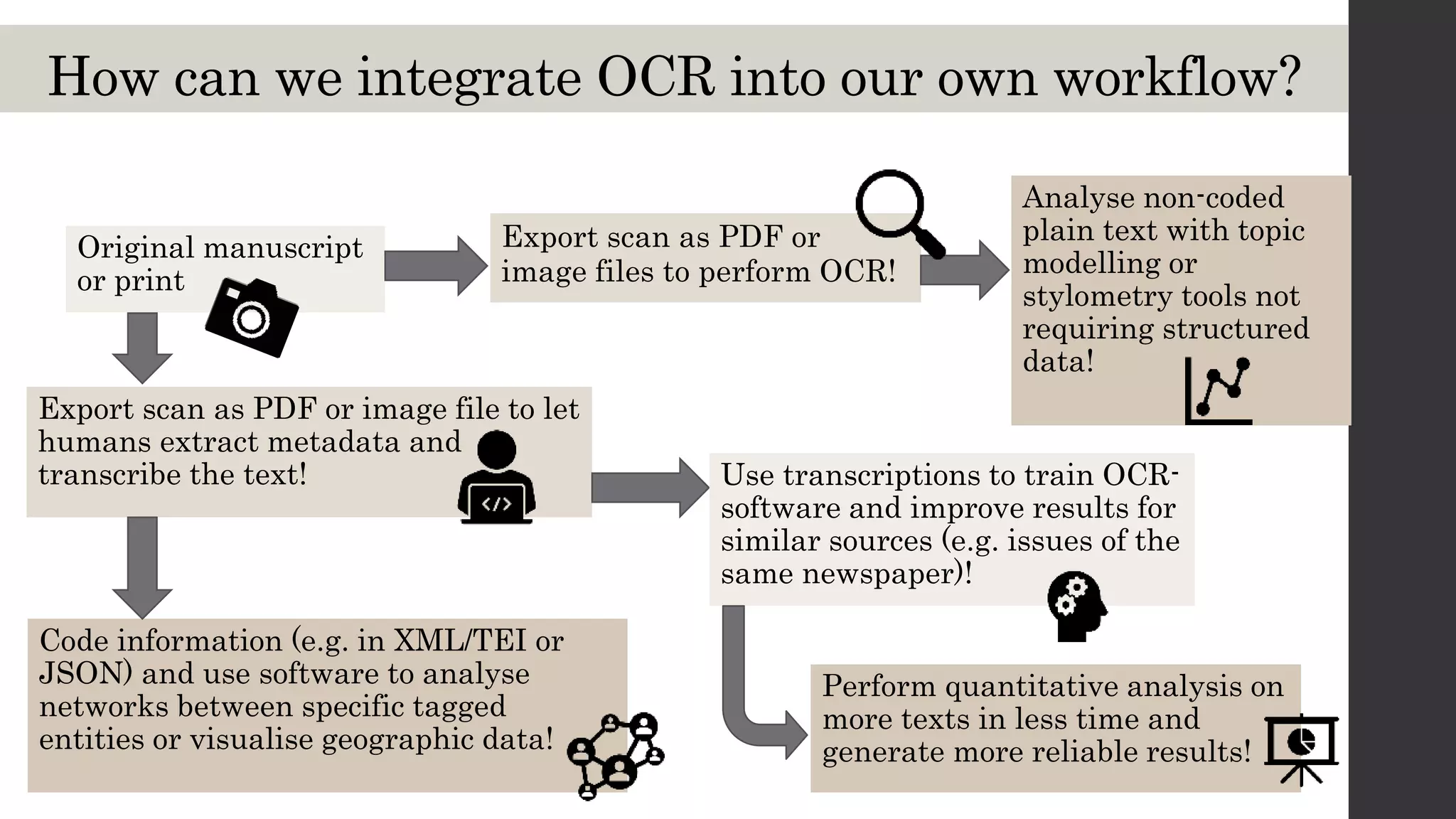
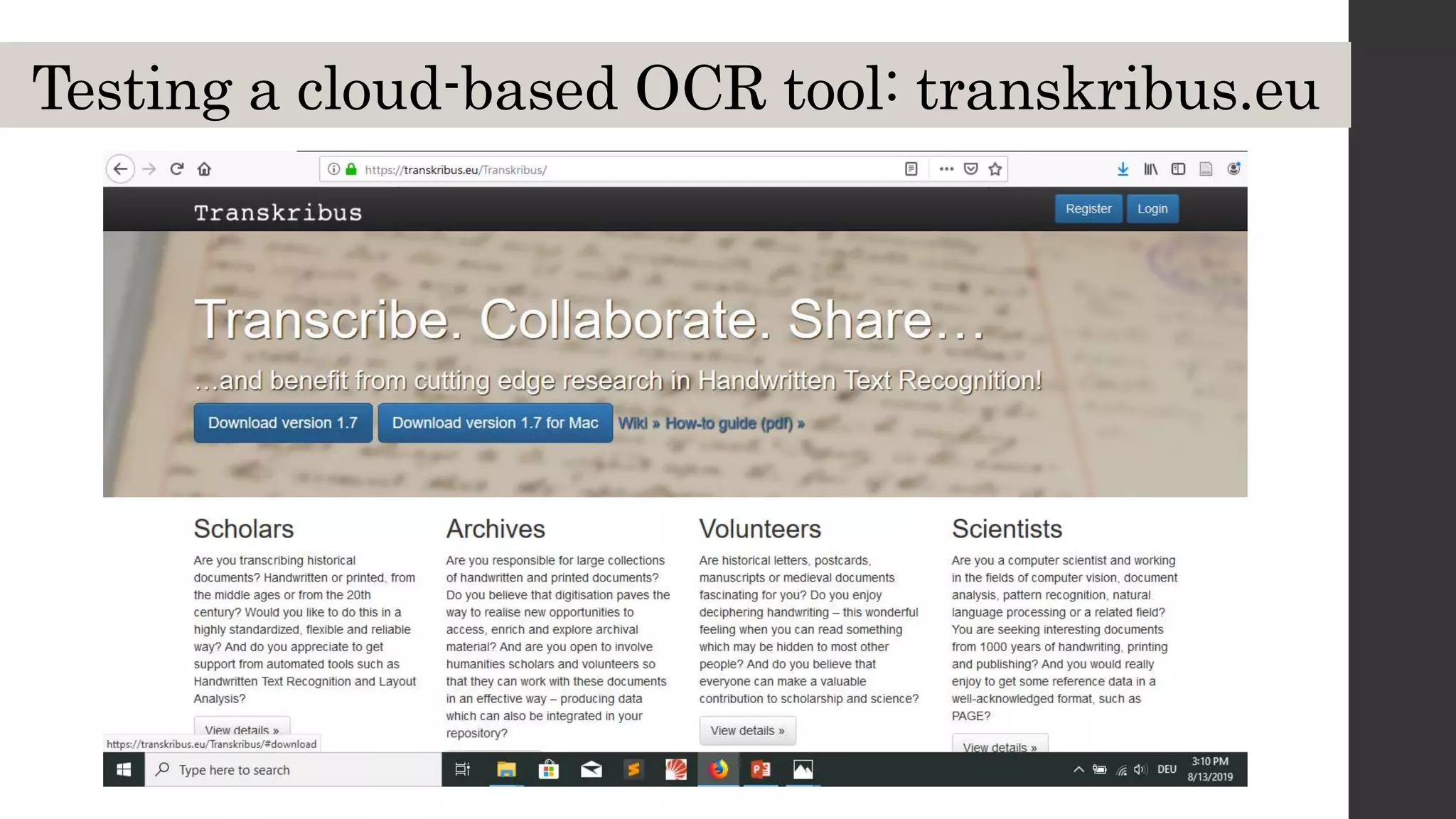

This document discusses optical character recognition (OCR) and its use and challenges in digitizing historical texts for research. It begins by defining OCR and how it works, then discusses its history and development from the 1950s to present. Current OCR tools use machine learning to improve accuracy, but open-source tools can be difficult to install and use. The document evaluates several popular OCR tools and services available to researchers and provides tips on integrating OCR into one's own workflow.



![Text reader [OCR]](https://cdn.slidesharecdn.com/ss_thumbnails/textreaderocr-191031162423-thumbnail.jpg?width=640&height=640&fit=bounds)



















































![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)





