Download to read offline











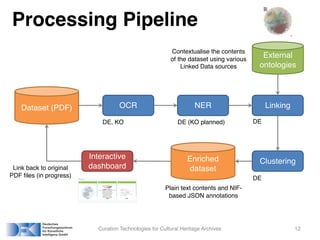







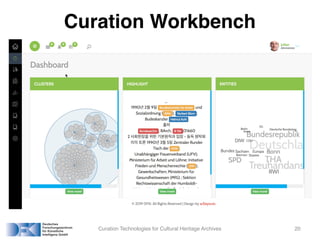





The document presents an overview of curation technologies aimed at enhancing cultural heritage archives through an interactive workbench, highlighting a project focused on the German reunification data set. It discusses the processing pipeline involving OCR, NER, and clustering for improved data access, and the goal is to create a user-friendly dashboard for intuitive analysis and exploration. Future work includes user studies, linking tools to original documents, and developing additional services.



































































