Download as PDF, PPTX
































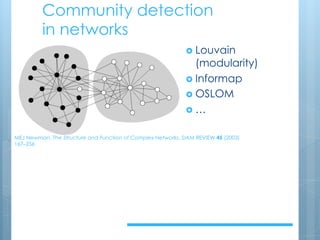
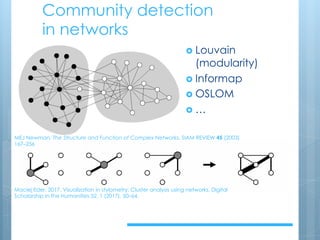




















The document discusses the stylometry of literary papyri and addresses how to improve uncertain metadata, such as authorship and dating, using text extraction and data cleaning techniques. It describes methods for clustering texts through distance-based and community detection algorithms, along with their effectiveness and limitations. The conclusions emphasize the need for regularization in clustering and propose future directions including the use of n-grams and supervised machine learning to enhance textual analysis.




![[DCSB] Yannick Anné and Toon Van Hal (U of Leuven), "Creating a Dynamic Gramm...](https://cdn.slidesharecdn.com/ss_thumbnails/yannickanne-141212042315-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)

























































