Download as PDF, PPTX











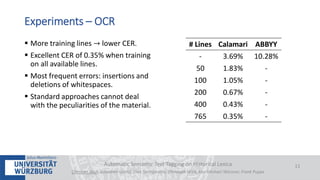
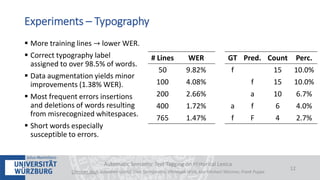

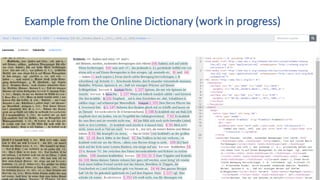



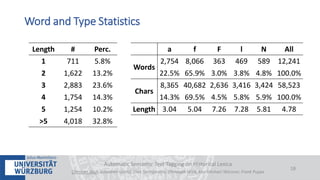


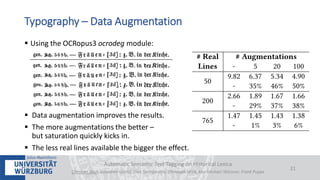
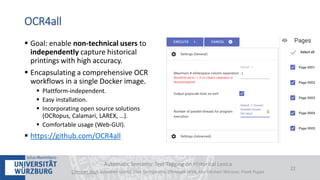

The document discusses a case study on the automatic semantic text tagging of Daniel Sanders' historical lexicon using optical character recognition (OCR) and typography classification. It highlights the methods for labeling typography classes, ground truth production, and the effectiveness of combining OCR outputs to improve recognition accuracy. The study aims to create a workflow for digitizing historical lexica and suggests further experimentation with different typographical attributes and OCR models.
































































