





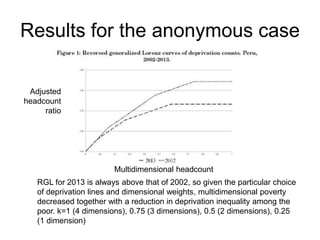
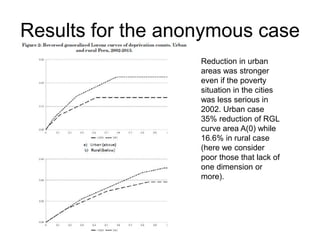
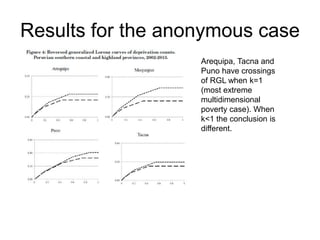

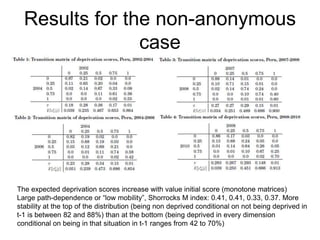
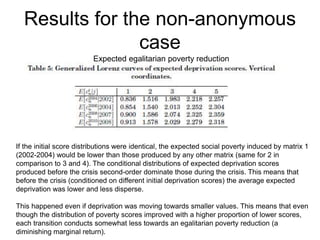


This paper proposes a framework for analyzing pro-poor reductions in multidimensional poverty that considers changes in both the average poverty level and inequality among the poor. The authors define a counting measure of multidimensional poverty based on equal weights across multiple dimensions of well-being. They illustrate how to identify when one poverty reduction is more pro-poor than another using reverse generalized Lorenz curves. An empirical application to Peru between 2002-2013 finds reductions in both multidimensional poverty and inequality among the poor during this period, with larger decreases occurring in urban versus rural areas.









![Pcnem [linguagens, códigos e suas tecnologias]](https://cdn.slidesharecdn.com/ss_thumbnails/pcnemlinguagenscdigosesuastecnologias-160312221151-thumbnail.jpg?width=640&height=640&fit=bounds)







































![Session 7 b commentson daneilkerpaperonukr&d servicelives2014iariw[1]](https://cdn.slidesharecdn.com/ss_thumbnails/pwfpecwntsmdld64j1xg-signature-6de5ee34a7e0a8be608105cfc95b1f55459403214875a488c94e063931d3b0c1-poli-140830080216-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)














![Awareness of digital currency[1] (1).pptx](https://cdn.slidesharecdn.com/ss_thumbnails/awarenessofdigitalcurrency11-260125155504-b1badee4-thumbnail.jpg?width=640&height=640&fit=bounds)











