About me
2
• Education
•NCU (MIS)、NCCU (CS)
• Experiences
• Telecom big data Innovation
• Retail Media Network (RMN)
• Customer Data Platform (CDP)
• Know-your-customer (KYC)
• Digital Transformation
• LLM Architecture & Development
• Research
• Data Ops (ML Ops)
• Generative AI research
• Business Data Analysis, AI
Sequence Data: Types
•Sequence Data:
• The order of elements is significant.
• It can have variable lengths. In natural language, sentences can be of different
lengths, and in genomics, DNA sequences can vary in length depending on the
organism.
5
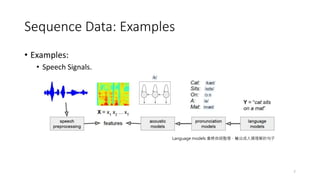
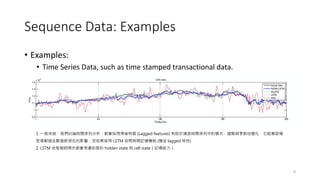
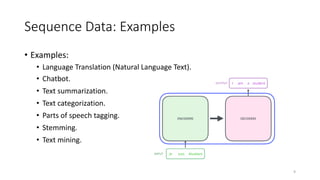
Sequence Data: Examples
•Examples:
• Time Series Data, such as time stamped transactional data.
8
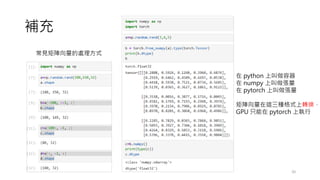
1. 一般來說,我們討論時間序列分析,都會採用滯後特徵 (Lagged features) 有助於捕捉時間序列中的模式、趨勢與季節性變化,它能幫助模
型理解過去數值對現在的影響;但如果採用 LSTM 自帶時間記憶機制 (隱含 lagged 特性)
2. LSTM 在每個時間步都會考慮前面的 hidden state 和 cell state(記憶能力)
9.
• Examples:
• LanguageTranslation (Natural Language Text).
• Chatbot.
• Text summarization.
• Text categorization.
• Parts of speech tagging.
• Stemming.
• Text mining.
Sequence Data: Examples
9
10.
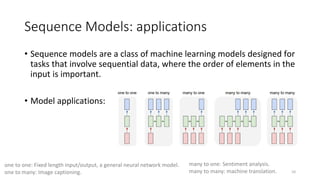
Sequence Models: applications
•Sequence models are a class of machine learning models designed for
tasks that involve sequential data, where the order of elements in the
input is important.
• Model applications:
10
one to one: Fixed length input/output, a general neural network model.
one to many: Image captioning.
many to one: Sentiment analysis.
many to many: machine translation.
11.
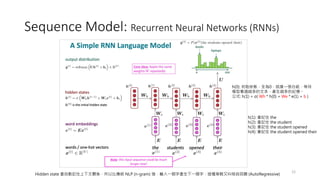
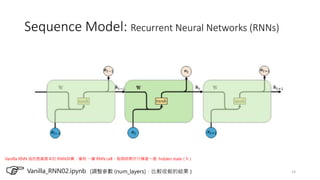
Sequence Model: RecurrentNeural Networks (RNNs)
• RNNs are a fundamental type of sequence model.
• They process sequences one element at a time sequentially while
maintaining an internal hidden state that stores information about
previous elements in the sequence.
• Traditional RNNs suffer from the Vanishing gradient problem, which
limits their ability to capture long-range dependencies.
11
12.
Sequence Model: RecurrentNeural Networks (RNNs)
12
Hidden state 會自動記住上下文關係,所以比傳統 NLP (n-gram) 強,輸入一個字產生下一個字,這種策略又叫做自回饋 (AutoRegressive)
h(0): 初始狀態,全為0,就像一張白紙,等待
模型看過越多的文本,產生越多的記憶。
公式: h(1) = σ( Wh * h(0) + We * e(1) + b )
h(1): 會記住 the
h(2): 會記住 the student
h(3): 會記住 the student opened
h(4): 會記住 the student opened their
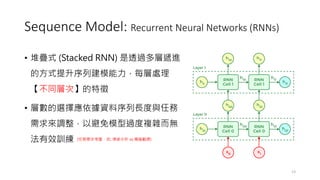
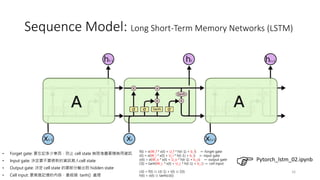
Sequence Model: LongShort-Term Memory Networks (LSTM)
• They are a type of RNNs designed to overcome the Vanishing gradient
problem.
• They introduce specialized memory cells and gating mechanisms that
allow them to capture and preserve information over long sequences.
• Gates (input, forget, and output) to regulate the flow of information.
• 傳統的 NLP 當中, 依賴前一個狀態進行文字生成的做法
• Hidden Markov Models (HMM)
• N-Gram
15
(LSTM 梯度消失問題仍存在,只是相較 RNNs 會好一些而已)
(不考慮上下文)
(額外引入了 cell state,用來保留長期記憶,進而有效處理長距離依賴問題)
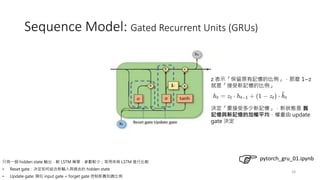
Sequence Model: GatedRecurrent Units (GRUs)
• They are another variant of RNNs that are similar to LSTM but with a
simplified structure.
• They also use gating mechanisms to control the flow of information
within the network.
• Gates (reset gate and update gate) to regulate the flow of information
• They are computationally more efficient than LSTM while still being
able to capture dependencies in sequential data.
17
(權重參數的數量比較少一些,所以收斂速度上會比較快)



























![_Deep learning in python Trustworthy [RNN].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearninginpythonrnn-251207084551-1fa069f9-thumbnail.jpg?width=640&height=640&fit=bounds)
















































