Download as PDF, PPTX



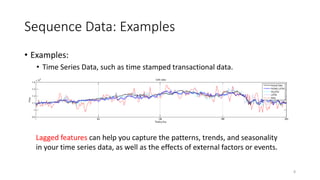
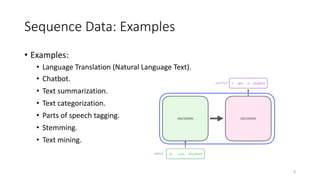
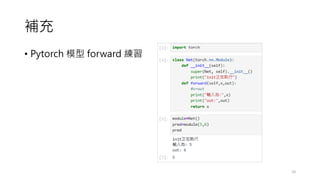

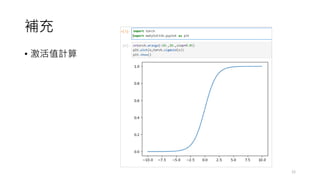
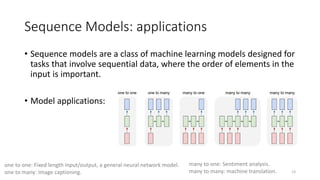

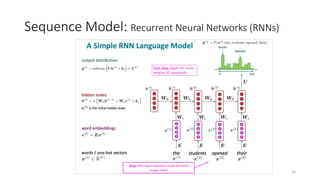
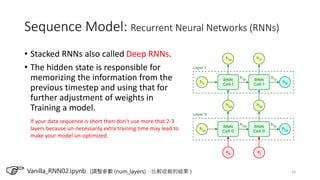

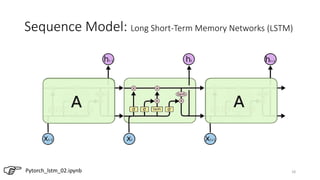

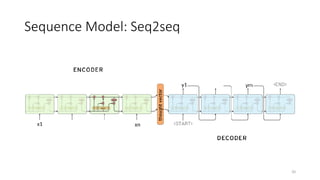

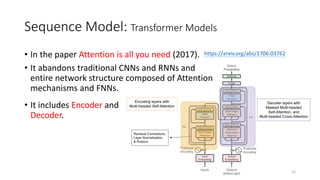

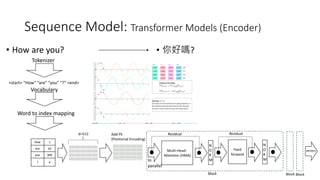

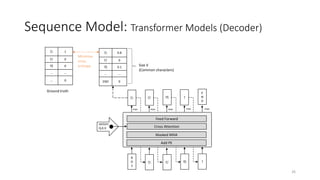
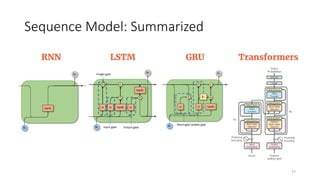
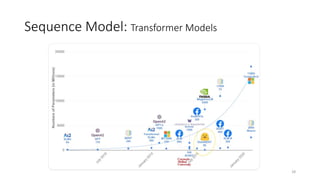
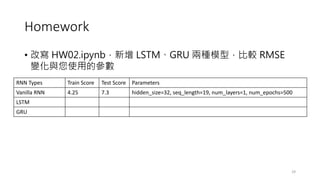
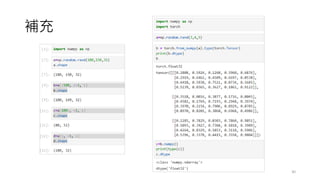

The document provides an overview of sequence models used in machine learning, detailing types like RNNs, LSTMs, GRUs, and transformer models. It highlights their applications in processing sequential data, addressing issues like the vanishing gradient problem, and the significance of self-attention mechanisms in transformers. Additionally, it includes tutorial content and homework assignments related to implementing these models in PyTorch.
















![_Deep learning in python Trustworthy [RNN].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearninginpythonrnn-251207084551-1fa069f9-thumbnail.jpg?width=640&height=640&fit=bounds)

















































