About me
2
• Education
•NCU (MIS)、NCCU (CS)
• Experiences
• Telecom big data Innovation
• Retail Media Network (RMN)
• Customer Data Platform (CDP)
• Know-your-customer (KYC)
• Digital Transformation
• LLM Architecture & Development
• Research
• Data Ops (ML Ops)
• Generative AI research
• Business Data Analysis, AI
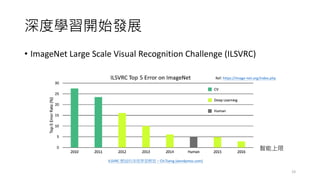
深度學習開始發展
• 2018 TuringAward
• Bengio, Hinton, and LeCun, are sometimes referred to as the "Godfathers of
AI" and "Godfathers of Deep Learning
17
Ref: https://awards.acm.org/about/2018-turing
18.
強化學習脫穎而出
• 2024 TuringAward
• 強化學習(Reinforcement Learning)奠基者 Andrew Barto 和 Richard
Sutton,表彰他們開創性的研究
18
圖靈獎也納入 AI 版圖:2024 年得主為強化學習先驅 Andrew Barto 與 Richard Sutton | TechNews 科技新報
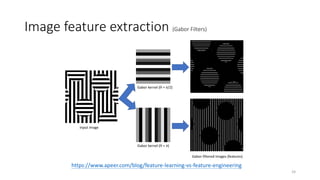
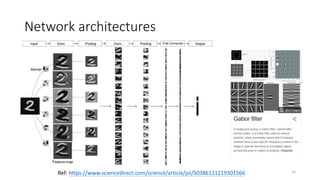
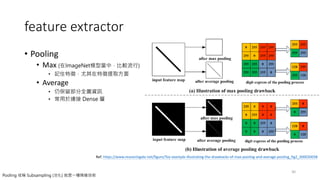
Feature extractor
• Kernelmaps: Image features of edge-
detection, sharpen…etc. (一般為奇數,例如: 1x1,
3x3, 5x5)
• Convolutional: Convolutional and
pooling layers which act as the feature
extractor.
• Feature maps: The outputs of kernel
map process.
26
https://zhuanlan.zhihu.com/p/77471866
27.
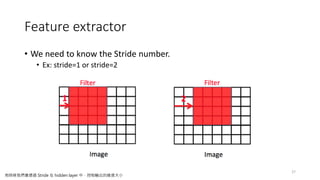
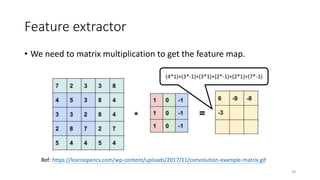
Feature extractor
• Weneed to know the Stride number.
• Ex: stride=1 or stride=2
27
有時候我們會透過 Stride 在 hidden layer 中,控制輸出的維度大小
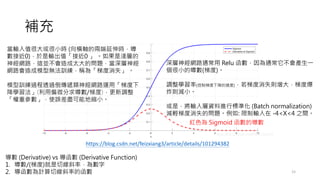
補充
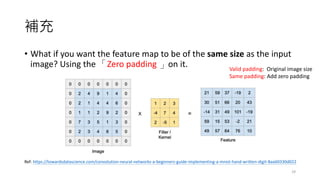
• What ifyou want the feature map to be of the same size as the input
image? Using the 「Zero padding 」on it.
29
Ref: https://towardsdatascience.com/convolution-neural-networks-a-beginners-guide-implementing-a-mnist-hand-written-digit-8aa60330d022
Valid padding: Original image size
Same padding: Add zero padding
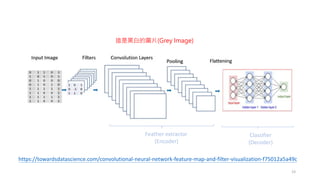
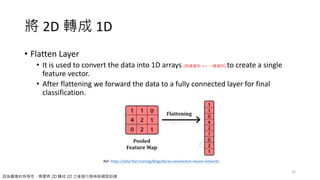
將 2D 轉成1D
• Flatten Layer
• It is used to convert the data into 1D arrays (多維資料 => 一維資料) to create a single
feature vector.
• After flattening we forward the data to a fully connected layer for final
classification.
33
Ref: https://data-flair.training/blogs/keras-convolution-neural-network/
因為圖像的特殊性,需要將 2D 轉成 1D 之後進行類神經網路訓練
34.
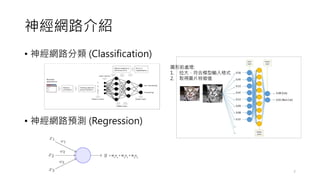
Classifier (分類器)
• DenseLayer
• It is a fully connected layer. Each node in this layer is connected to the
previous layer.
• This layer is used at the final stage of CNN to perform classification.
• Dropout Layer
• It is used to prevent the network from overfitting.
34
Ref: https://data-flair.training/blogs/keras-convolution-neural-network/
分類器可以是所有機器學習當中的監督式學習模型



































![[台灣人工智慧學校] 人工智慧民主化在台灣](https://cdn.slidesharecdn.com/ss_thumbnails/aidemocratization180512sw-180515030532-thumbnail.jpg?width=640&height=640&fit=bounds)













![[台灣人工智慧學校] 人工智慧技術發展與應用](https://cdn.slidesharecdn.com/ss_thumbnails/version5-final-190319060225-thumbnail.jpg?width=640&height=640&fit=bounds)























