Semantic Search Component
•
3 likes•1,047 views

Concept and example of a semantic solution implemented with SQL views to cooperate with users on queries over structured data with independence from database schema knowledge and technology.
![The Problem ,[object Object],[object Object],[object Object],[object Object],[object Object],2](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
Recommended
Recommended
More Related Content
What's hot
What's hot (20)
Viewers also liked
Viewers also liked (20)
Similar to Semantic Search Component
Similar to Semantic Search Component (20)
Semantic Search Component
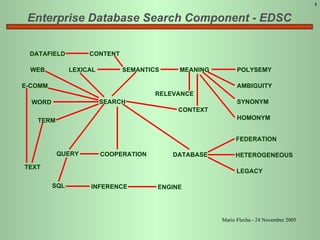
- 1. Enterprise Database Search Component - EDSC DATAFIELD CONTENT WEB LEXICAL SEMANTICS MEANING RELEVANCE CONTEXT POLYSEMY AMBIGUITY SYNONYM HOMONYM DATABASE FEDERATION HETEROGENEOUS LEGACY E-COMM WORD TERM TEXT SQL QUERY INFERENCE ENGINE COOPERATION SEARCH 1 Mario Flecha - 24 November 2005
- 5. Handle context to cope with....... AMBIGUITY -> Polysemy, Homonymy, Synonymy POLYSEMY TERM MEANING SAME SOUND ONE MEANING T M 1 M 2 M n . . . ONE TERM VARIOUS MEANINGS M T 1 T 2 T n . . . ONE MEANING VARIOUS TERMS HOMONYMY BY PHONETIC CONVERGENGE T 1 T 2 M 1 M 2 HOMONYMY BY SEMANTIC DIVERGENCE T T 1 T 2 M 1 M 2 SAME SOUND PASSAGE TO POLYSEMY T 1 M 1 T 2 M 2 T M 1 M 2 5 Legend: T = Term M = Meaning
- 6. Handle context to cope with....... SEMANTIC CONSTELLATION (SEMANTIC FIELD) TEACHING ANALPHABETISM STUDY STUDENT ANALPHABET TEACH KNOWLEDGE EDUCATE EDUCATION ALPHABETIZE ALPHABETIZING LEARN APPRENTICESHIP APPRENTICE 6
- 11. Contextualizing Terms 11 (a) Example: city*Seattle; state*WS; year*1998. The context database, beyond the prefix, keeps processing information for term treatment, like phonetization, words breaking etc Context Prefix * Term = Contextualized Term Lexical Domain
- 12. Overall Search Component Architecture 12 User’s Application RIM’s Auxiliary Objects Facts Databases - X,Y,Z... And Instances Facts database instance X Contextualized Term (Semantic Knowledge Base) Contextualized Term (Ontology) Database X Instance 1 . . . . . . . . . . . . . . . . . . . . . . . . . . Database X Instance 1 Term 3 . . . . . . . . . . . . term 1 . . . . . . . . . . . . RIM User * Knowledge Acquisition Consultation * User could be a human or software Mediator Mediator Mediator Database Y Database Z Instance 2 Instance N Instance 1 . Instance 2 Instance N . Instance N Database X Instance 1 Term 2 Database X Instance 2 Term 90 Database X Instance 1000 Term 10 Database Y Instance 5 Term 100 Database Y Instance 3 Term 100 term 2 term 3 term 10 term 30 term 100 term 1000 term K Database L Instance 2 Term 2000 Database Z Instance Z Term K Relations and composite Views of RIM Downward Upward User’s Application Answer (set of tuple Ids) Question (set of questions Knowledge Acquisition Methods
- 13. EXAMPLES CITY NAME SEARCH 13
- 14. EXAMPLES: LOCATION SEARCH 14 State City Kind of Street Street’s Name Quarter’s Name Did CepDigital find? Did Medi a tor find? Aníbal Matos * São Pedro ** N SL St Aníbal Matos São Pedro N SL Street Aníbal Matos São Pedro N SL Street Professor Aníbal Matos São Pedro N Y Street Professor Aníbal de Matos São Pedro N Y Avenue Prof.Aníbal Matos São Pedro N Y MG Belo Horizonte Street Professor Aníbal de Matos Santo Antônio N Y MG Belo Horizonte Street Prof Anïbal de Matos Santo Antônio N Y MG Belo Horizonte St Professor Aníbal de Matos Santo Antônio Y Y MG Belo Horizonte Street Professor Aníbal de Matos or S Antônio N N BL BL MG Belo Horizonte Street Professor or S Antônio BL BL BL SL MG Belo Horizonte Street Anïbal or S Antônio N SL
- 15. CONCLUSION 15