



![Big Data example
• Apache log files are common for web properties
• Simple format
- 27.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /search?q=book HTTP/1.0" 200
2326 "http://www.example.com/start.html" "Mozilla/4.08 [en] (Win98; I ;Nav)"
• Contains wealth of information
- IP address of the client
- User requesting the resource
- Date and Time
- URL Path
- Result code
- Object size returned to the client
- Referrer
- User-Agent
• 5
Saturday, August 14, 2010](https://image.slidesharecdn.com/seattlehug2010-100819130319-phpapp01/75/Seattle-hug-2010-5-2048.jpg)


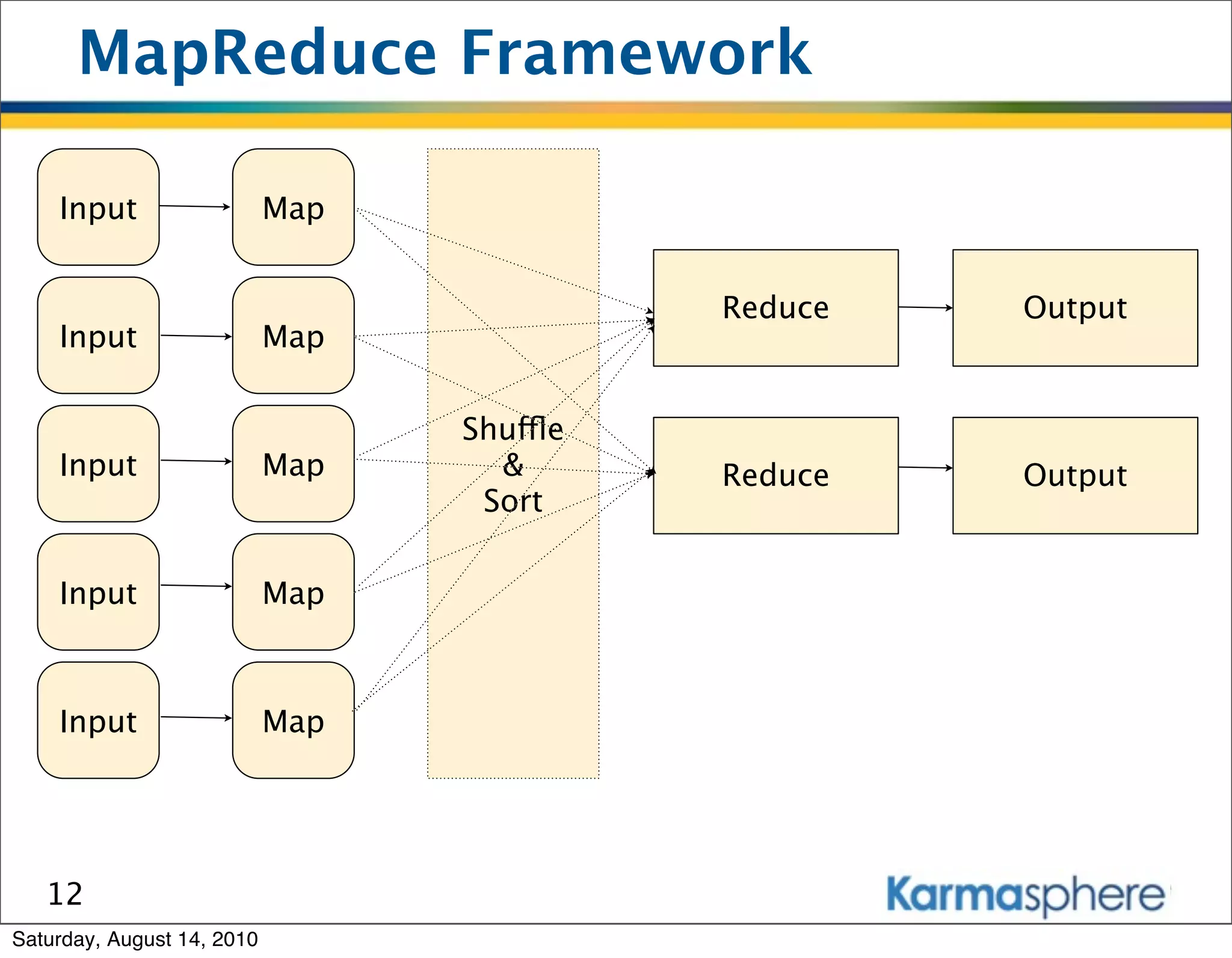
![What is MapReduce
• Old paradigm from functional languages
• Works on data tuples
• For each tuple apply mapper function f: [k1, v1]
-> [k2, v2]
• Collect tuples with similar keys and apply a
combine function g: [k2, [v1, v2, …,vn]]->[k3,v3]
• 9
Saturday, August 14, 2010](https://image.slidesharecdn.com/seattlehug2010-100819130319-phpapp01/75/Seattle-hug-2010-9-2048.jpg)


![Example
• Find the maximum number in a list
• Luckily max A = max(max(A[1..k]), max(A[k..N]))
• A = [1, 2, 3, 4, 5, …, 10]
• Divide A into chunks
- A1=[1,..,5]
- A2=[6,…,10]
• Map max on A1 to get 5
• Map max on A2 to get 10
• Reduce [5,10] by using max to get 10
• 13
Saturday, August 14, 2010](https://image.slidesharecdn.com/seattlehug2010-100819130319-phpapp01/75/Seattle-hug-2010-13-2048.jpg)
![Another example
• Add Numbers from 1..100
• Sum of A[1..100] = Sum of A[1..k] + Sum of A[k
+1..p] + Sum of A[p+1..100]
Text
1 2 3 4 5 6 7 8 9 . . . . . 100
15 N M
5050
• 14
Saturday, August 14, 2010](https://image.slidesharecdn.com/seattlehug2010-100819130319-phpapp01/75/Seattle-hug-2010-14-2048.jpg)
![Another example
• Canonical word count
• Divide a text into words
- “To be or not to be”
- To, be, or, not, to, be
• Mapper
- For every word emit a tuple (word, 1)
- (To, 1), (be, 1), (or, 1), (not, 1), (to, 1), (be, 1)
• Collect output by word
- (To, [1, 1]), (be, [1,1]), (or, [1]), (not, [1])
• Reduce the tuples
- (To, 2), (be, 2), (or, 1), (not, 1)
• 15
Saturday, August 14, 2010](https://image.slidesharecdn.com/seattlehug2010-100819130319-phpapp01/75/Seattle-hug-2010-15-2048.jpg)




![And how would WordCount look?
public class HadoopMapper extends MapReduceBase implements
Mapper<LongWritable,Text,Text,LongWritable> {
@Override
public void map(LongWritable key, Text value, OutputCollector<Text, LongWritable> output,
Reporter reporter)
throws IOException {
String[] line = value.toString().split("[,s]+");
for(String token : line) {
output.collect(new Text(token), new LongWritable(1));
}
}
}
• 20
Saturday, August 14, 2010](https://image.slidesharecdn.com/seattlehug2010-100819130319-phpapp01/75/Seattle-hug-2010-20-2048.jpg)

![Max - Mapper
public void map(LongWritable key, Text value, OutputCollector<Text, LongWritable> output,
Reporter reporter)
throws IOException {
String numbers[] = value.toString().split("[,s]+");
long max = -1;
for (String token : numbers) {
long number = Long.parseLong(token);
if (number > max) {
max = number;
}
}
output.collect(new Text("k"), new LongWritable(max));
}
• 22
Saturday, August 14, 2010](https://image.slidesharecdn.com/seattlehug2010-100819130319-phpapp01/75/Seattle-hug-2010-22-2048.jpg)

![Sum - Mapper
public void map(LongWritable key, Text value, OutputCollector<Text, LongWritable> output,
Reporter reporter)
throws IOException {
String numbers[] = value.toString().split("[,s]+");
long sum = 0;
for(String token : numbers) {
sum += Long.parseLong(token);
}
output.collect(new Text("k"), new LongWritable(sum));
}
• 24
Saturday, August 14, 2010](https://image.slidesharecdn.com/seattlehug2010-100819130319-phpapp01/75/Seattle-hug-2010-24-2048.jpg)





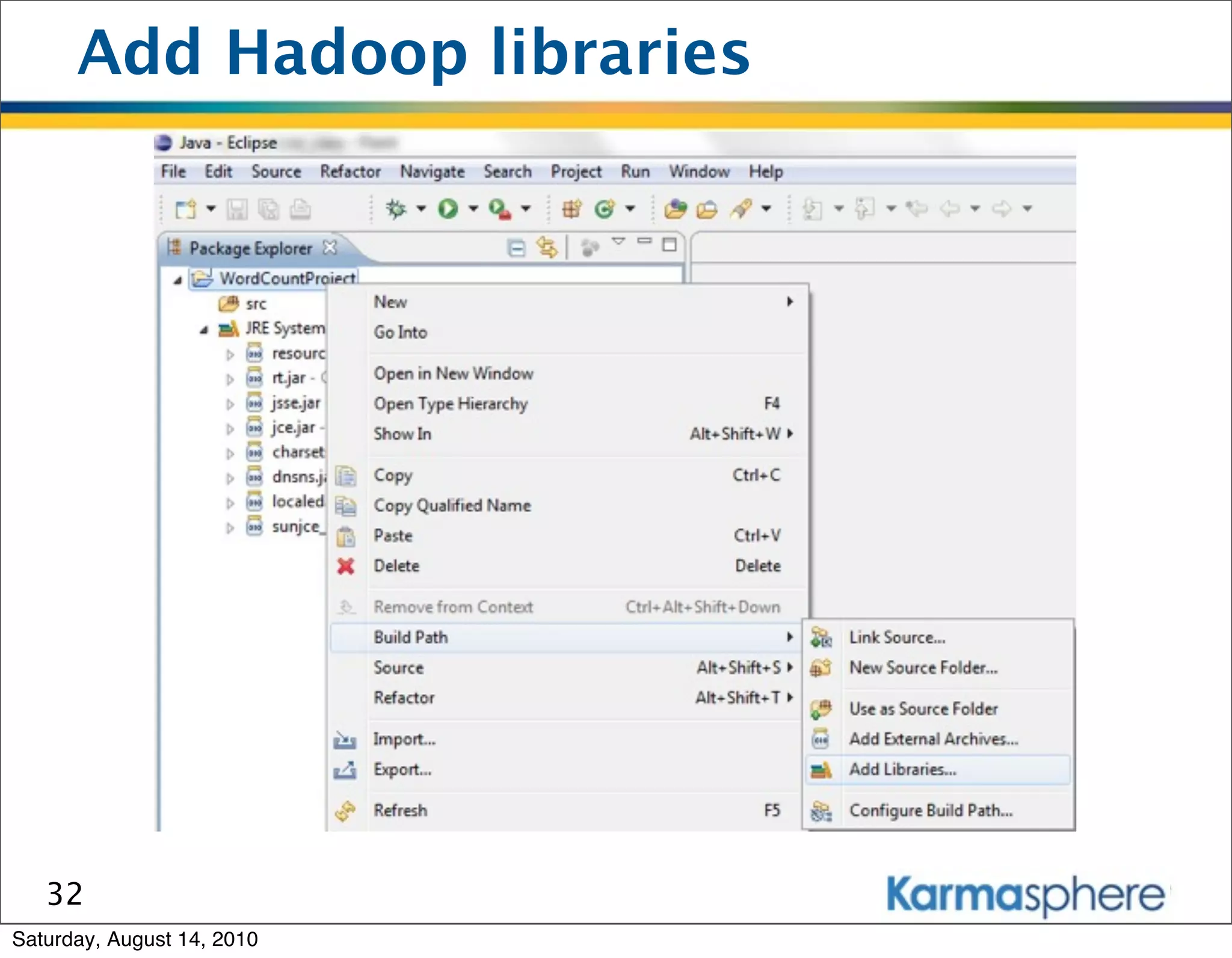
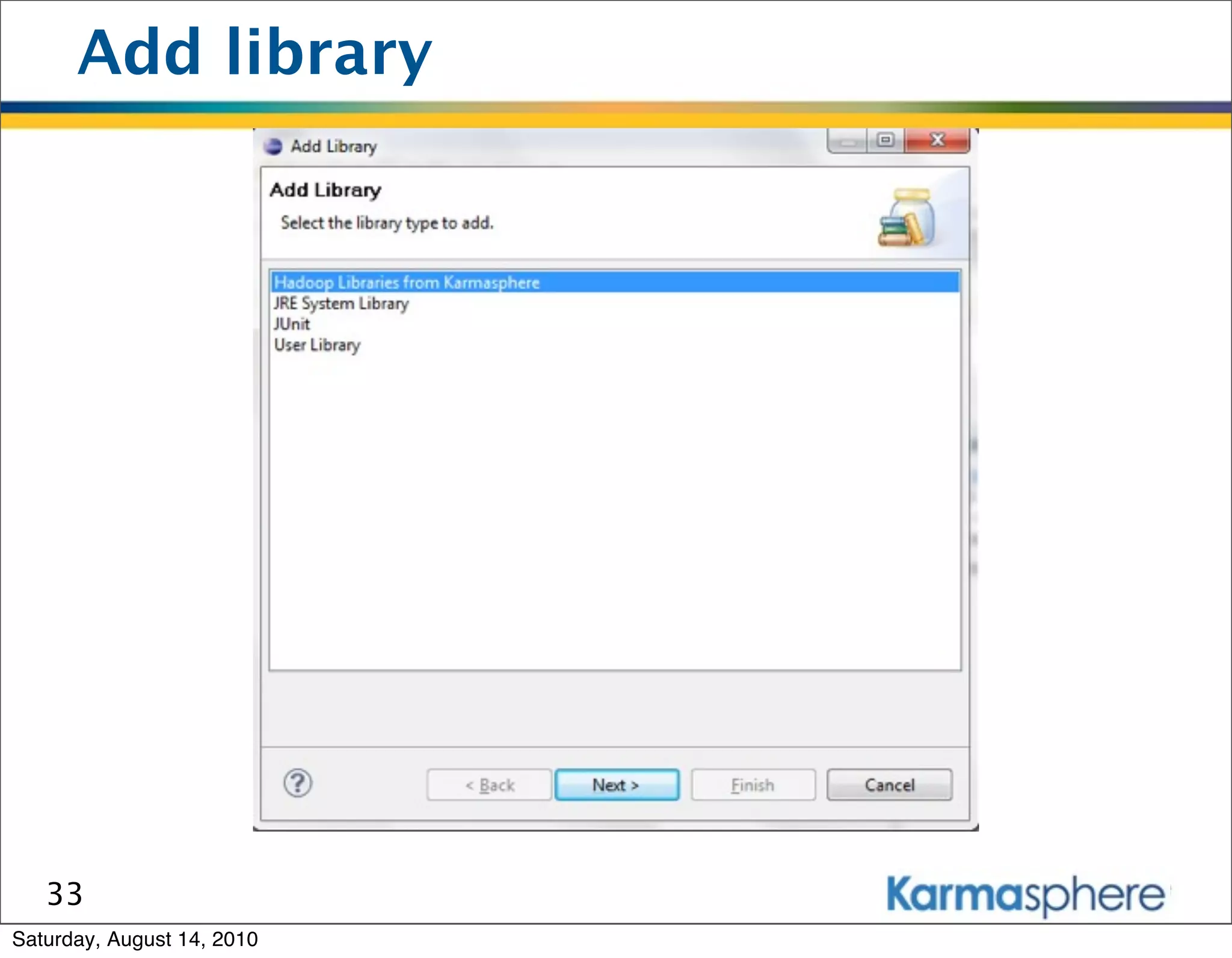
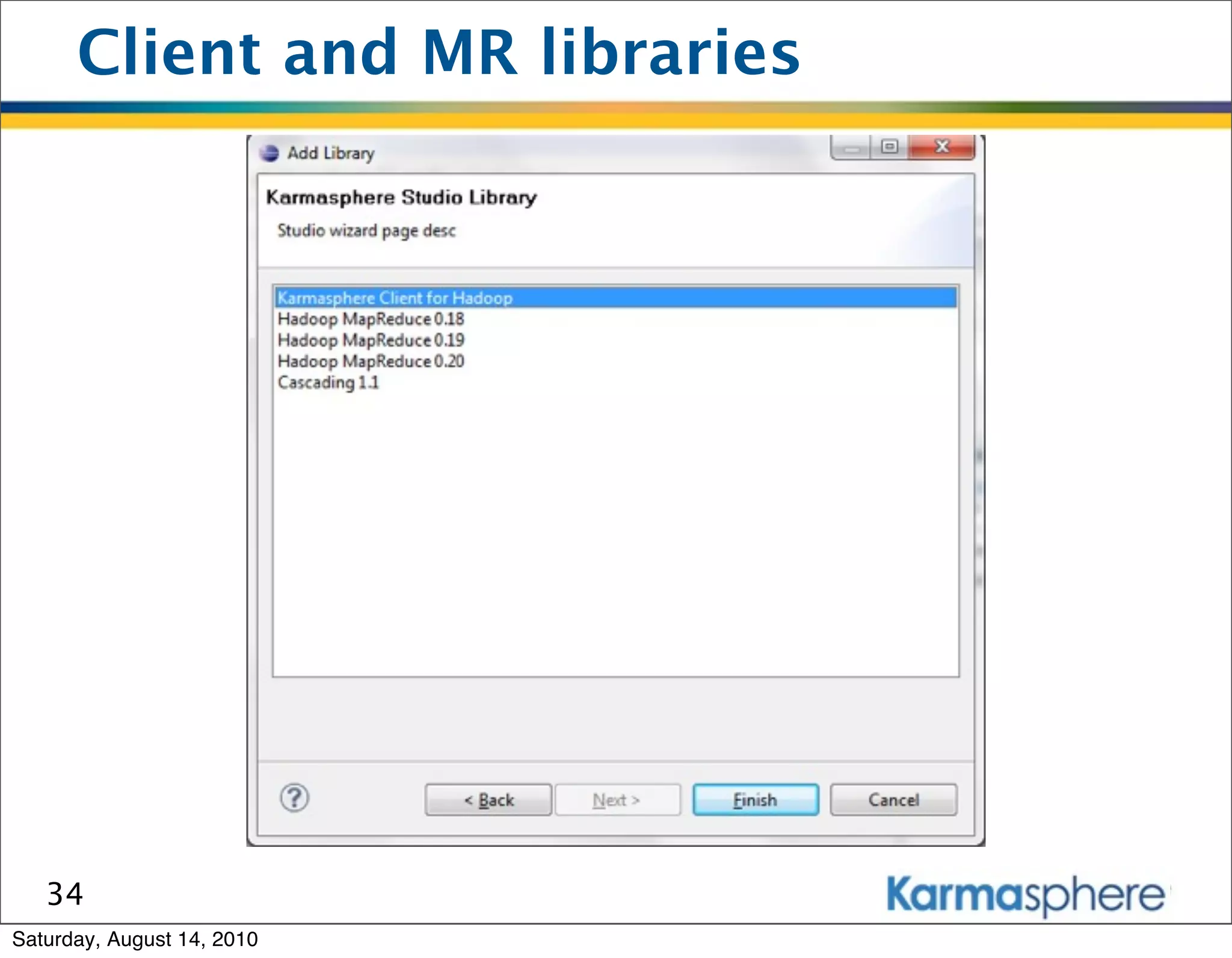
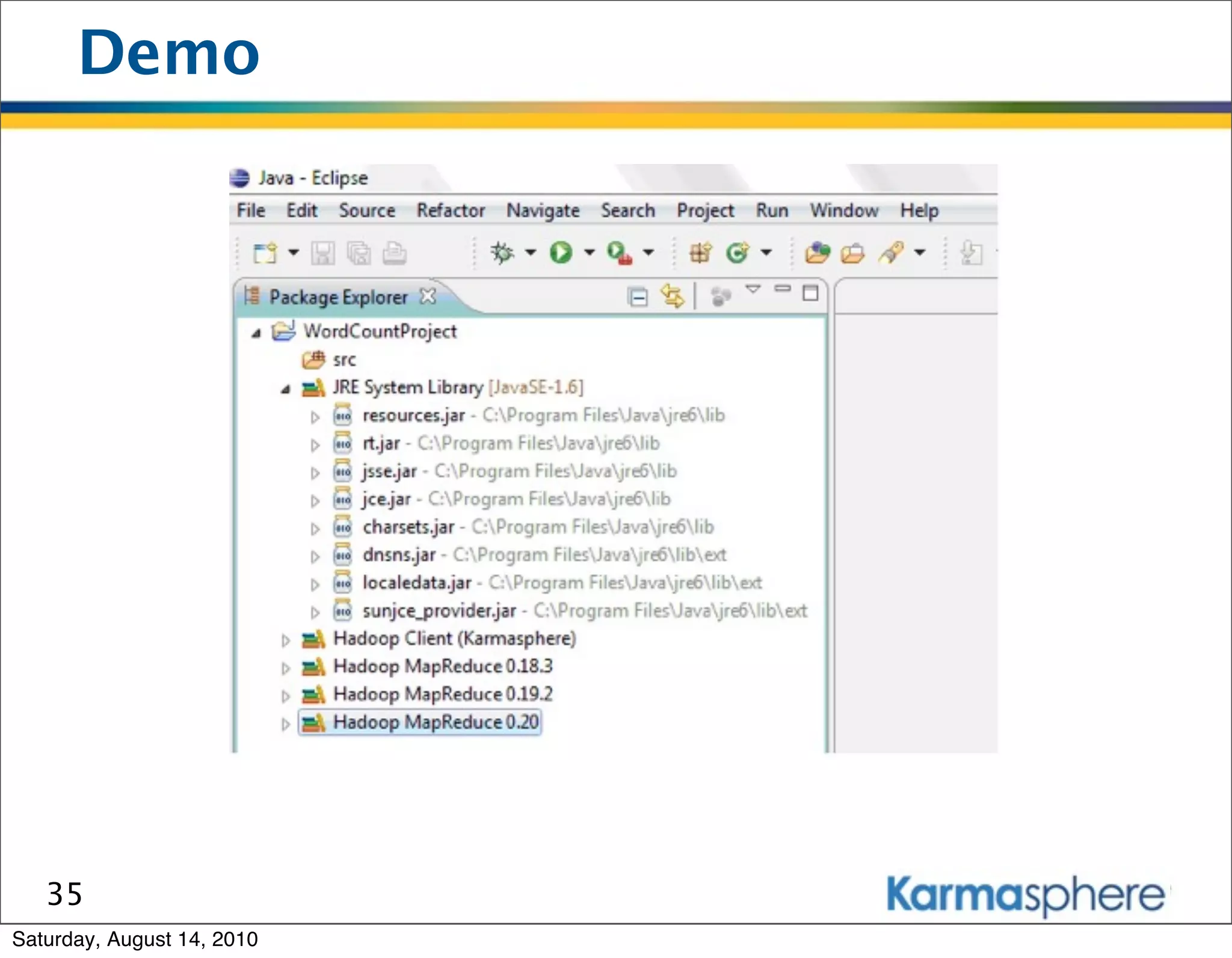
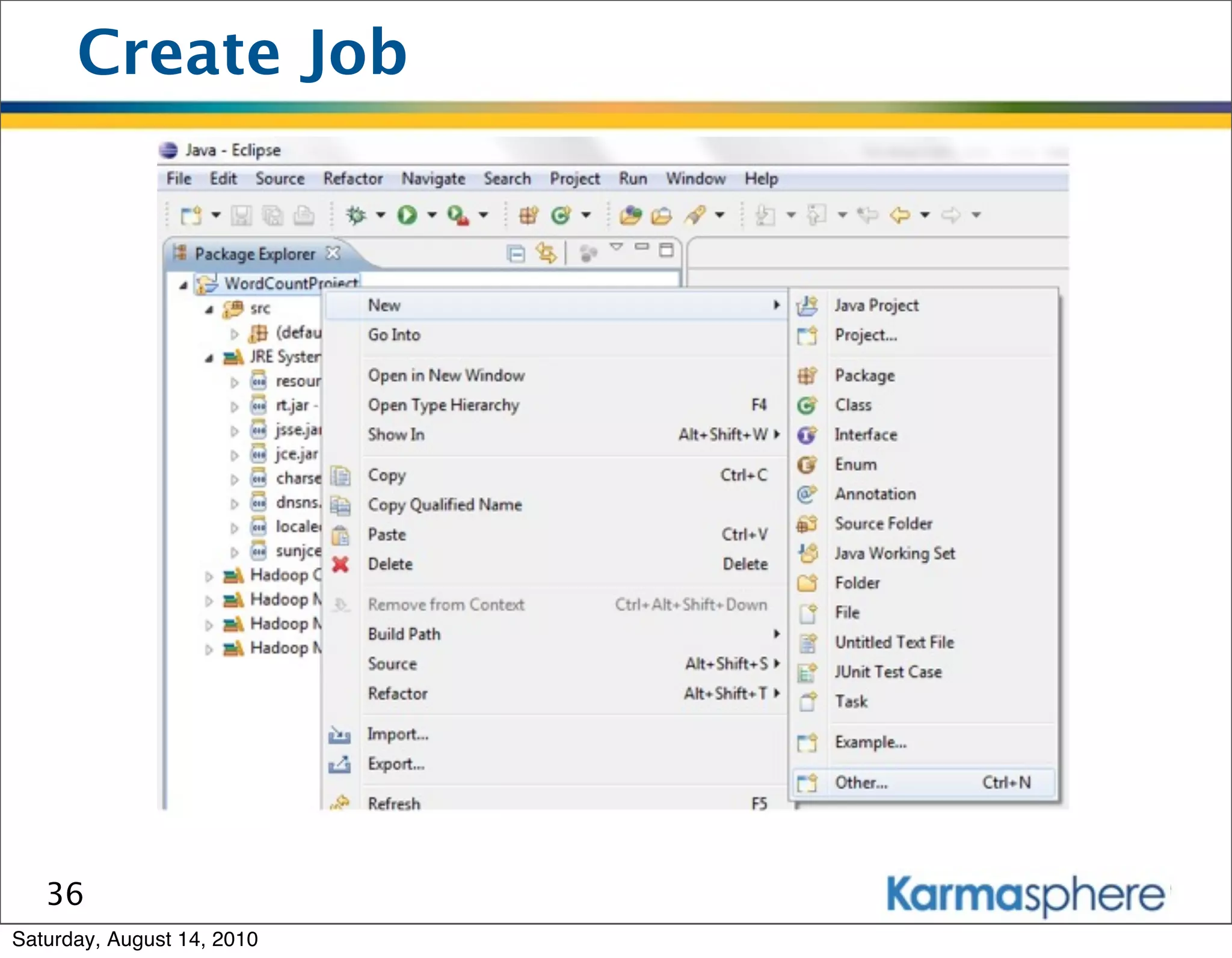
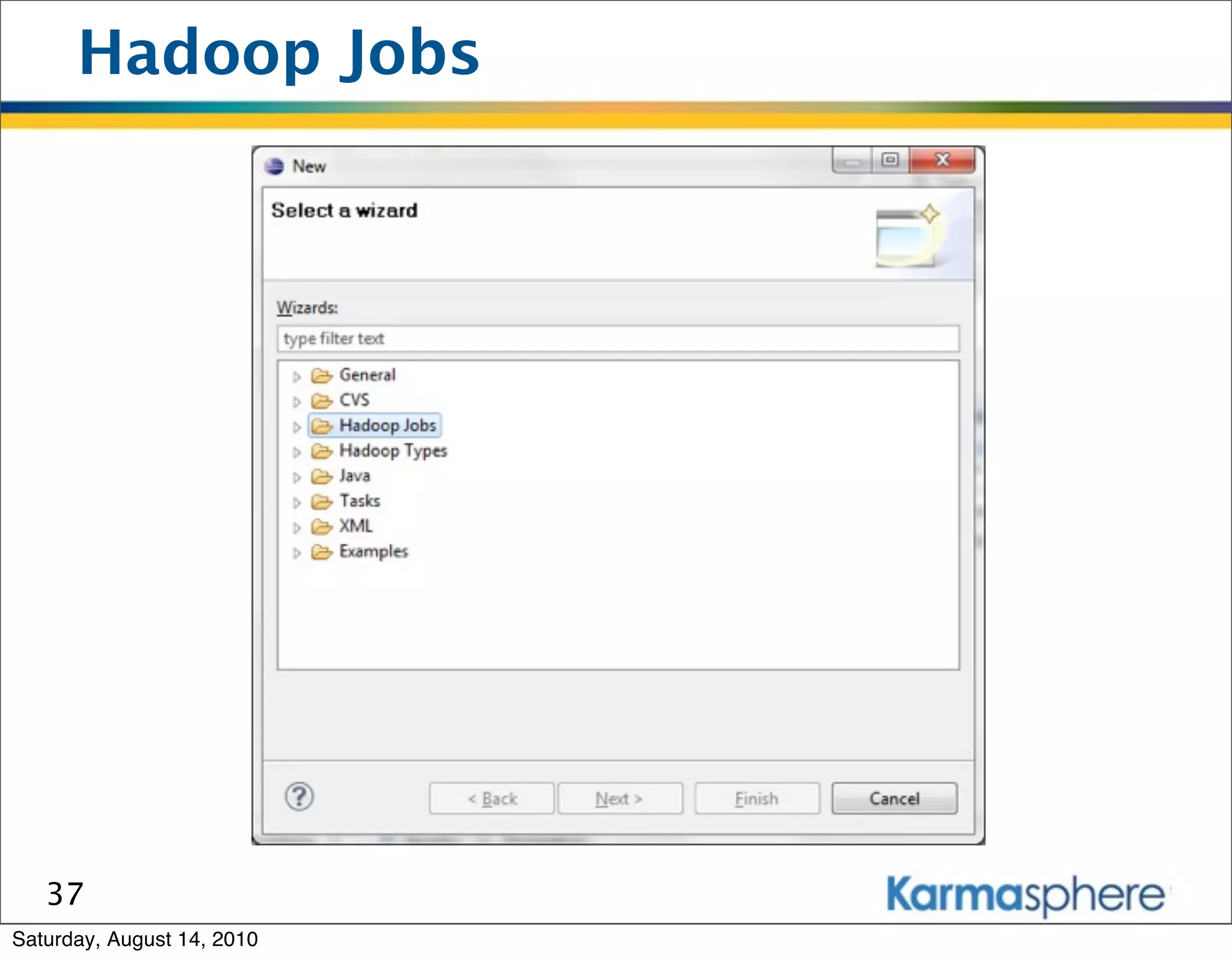
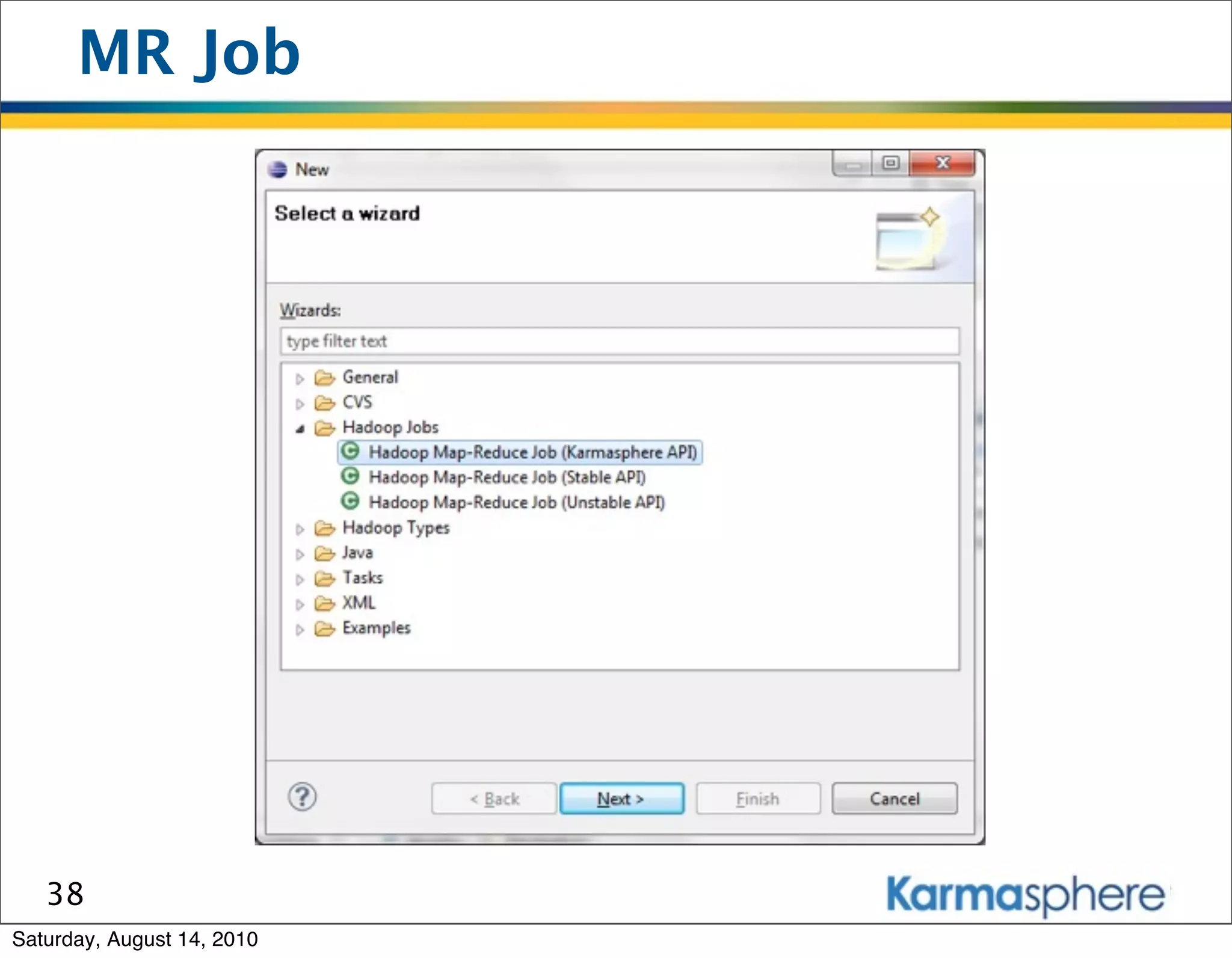
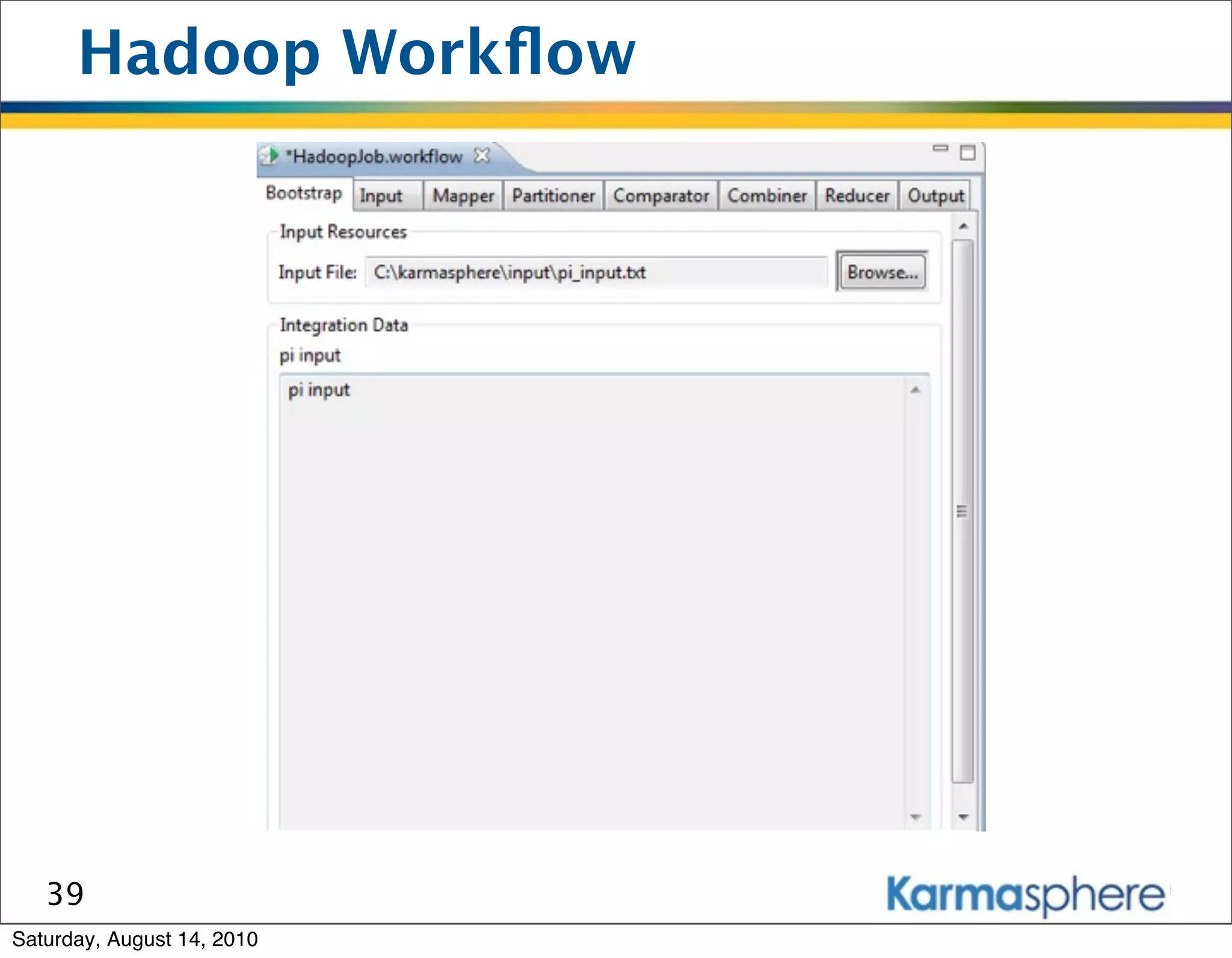
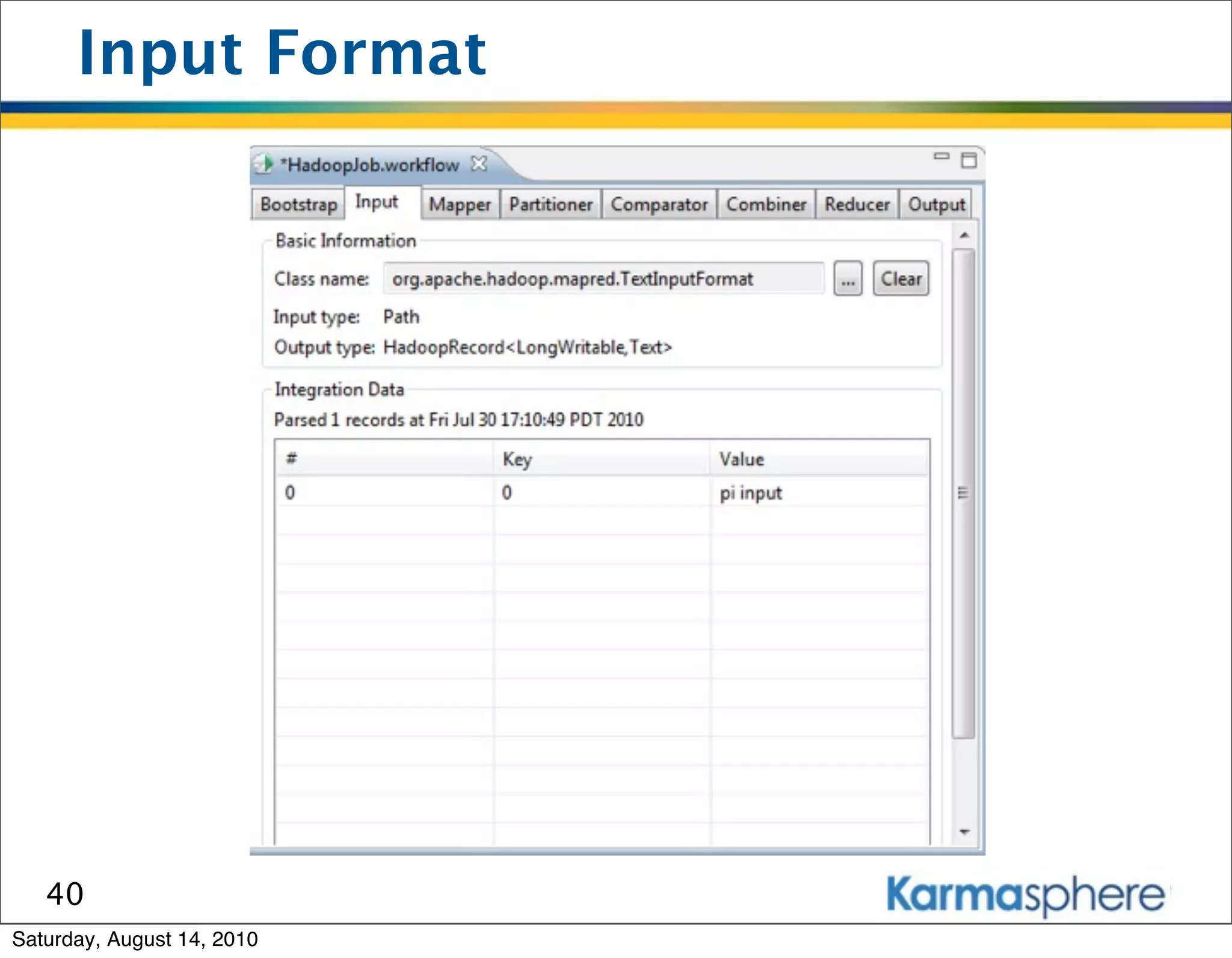
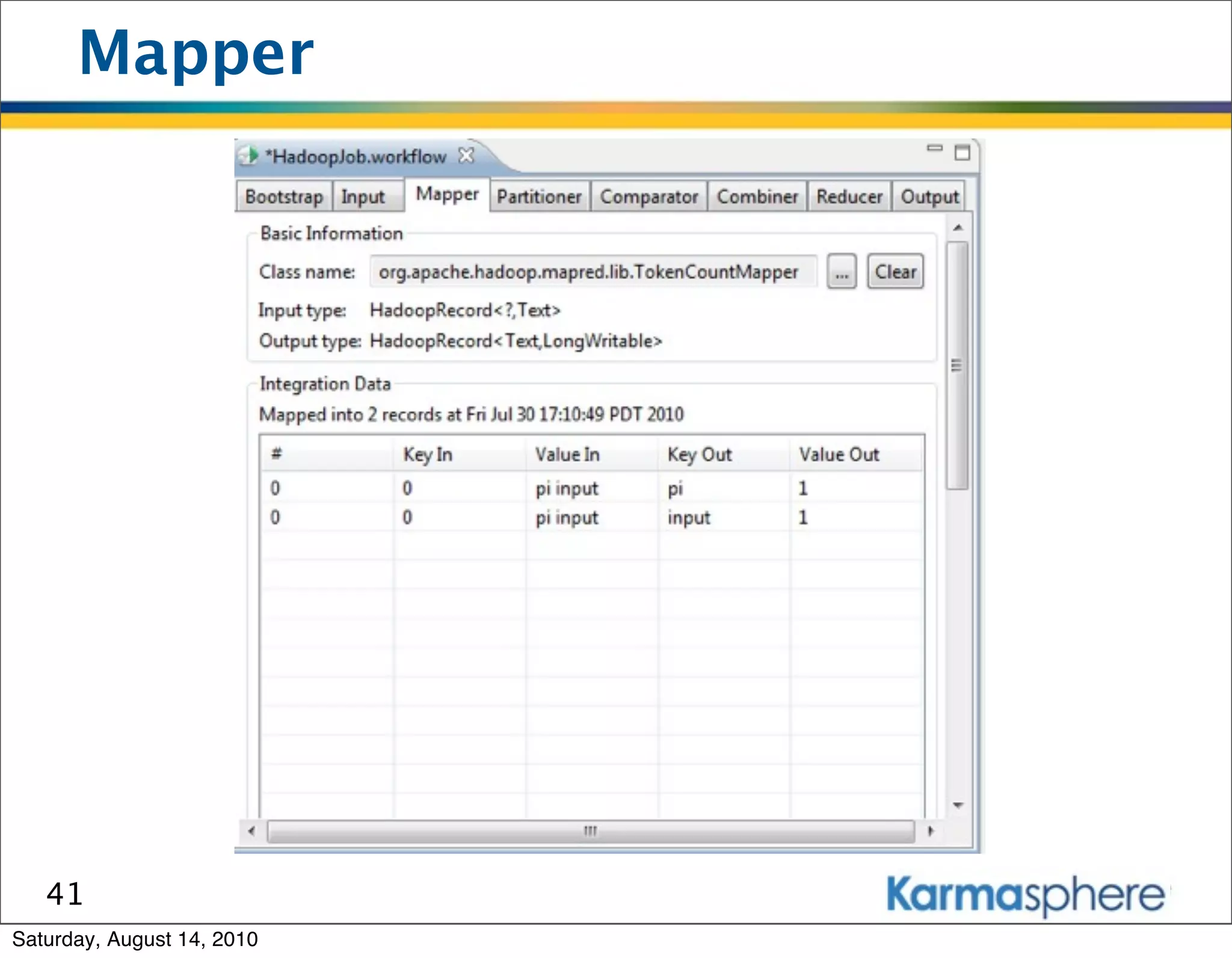
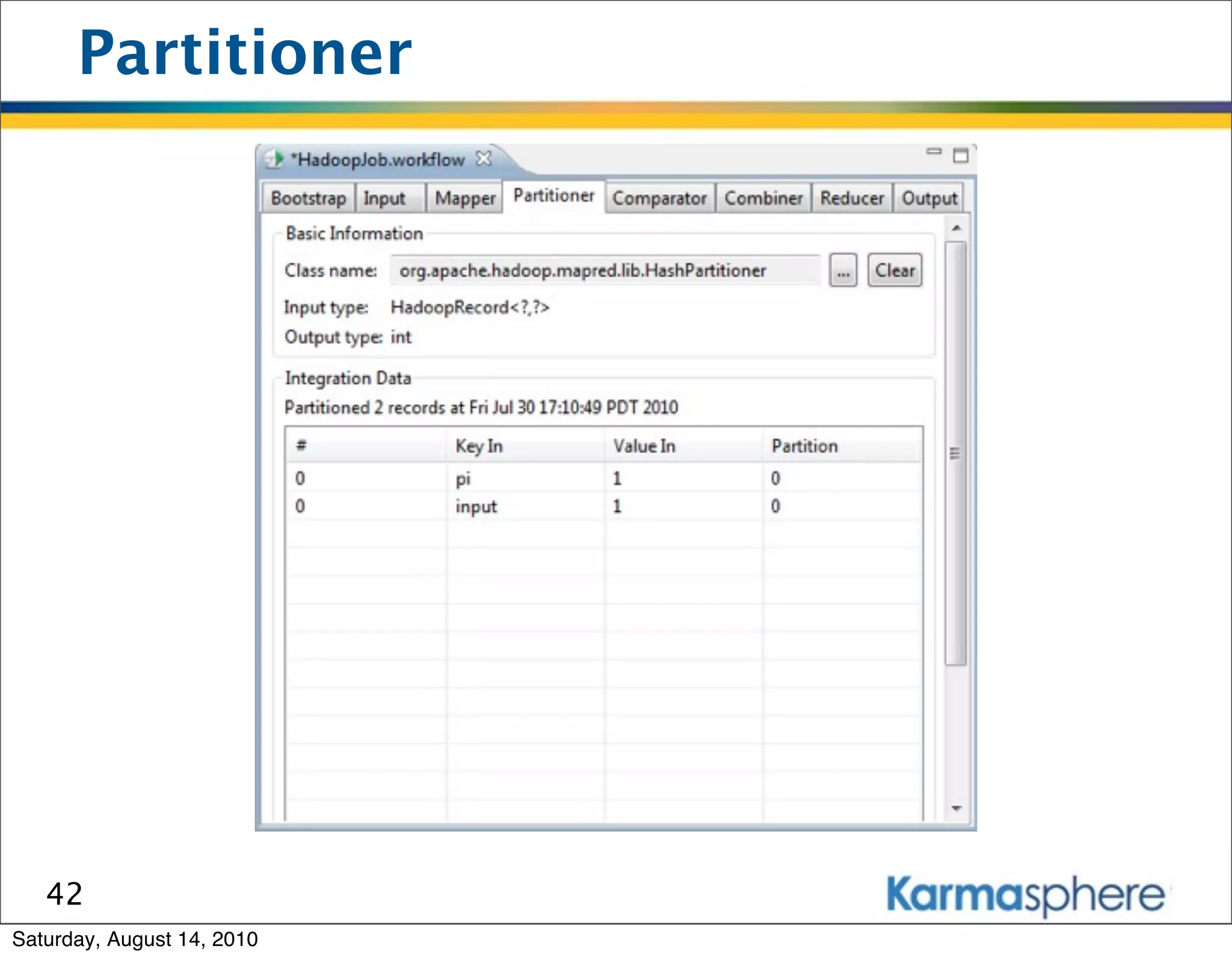
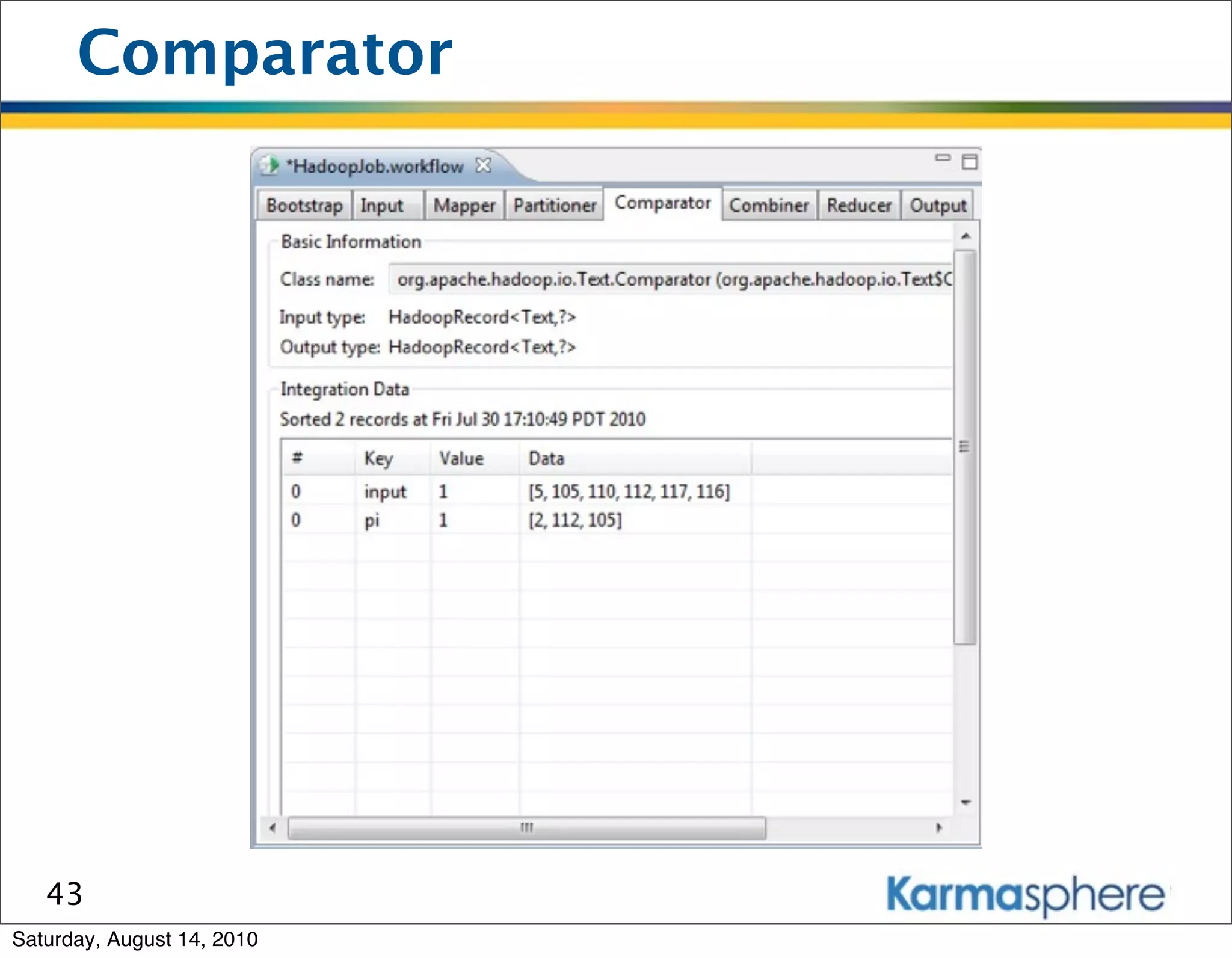
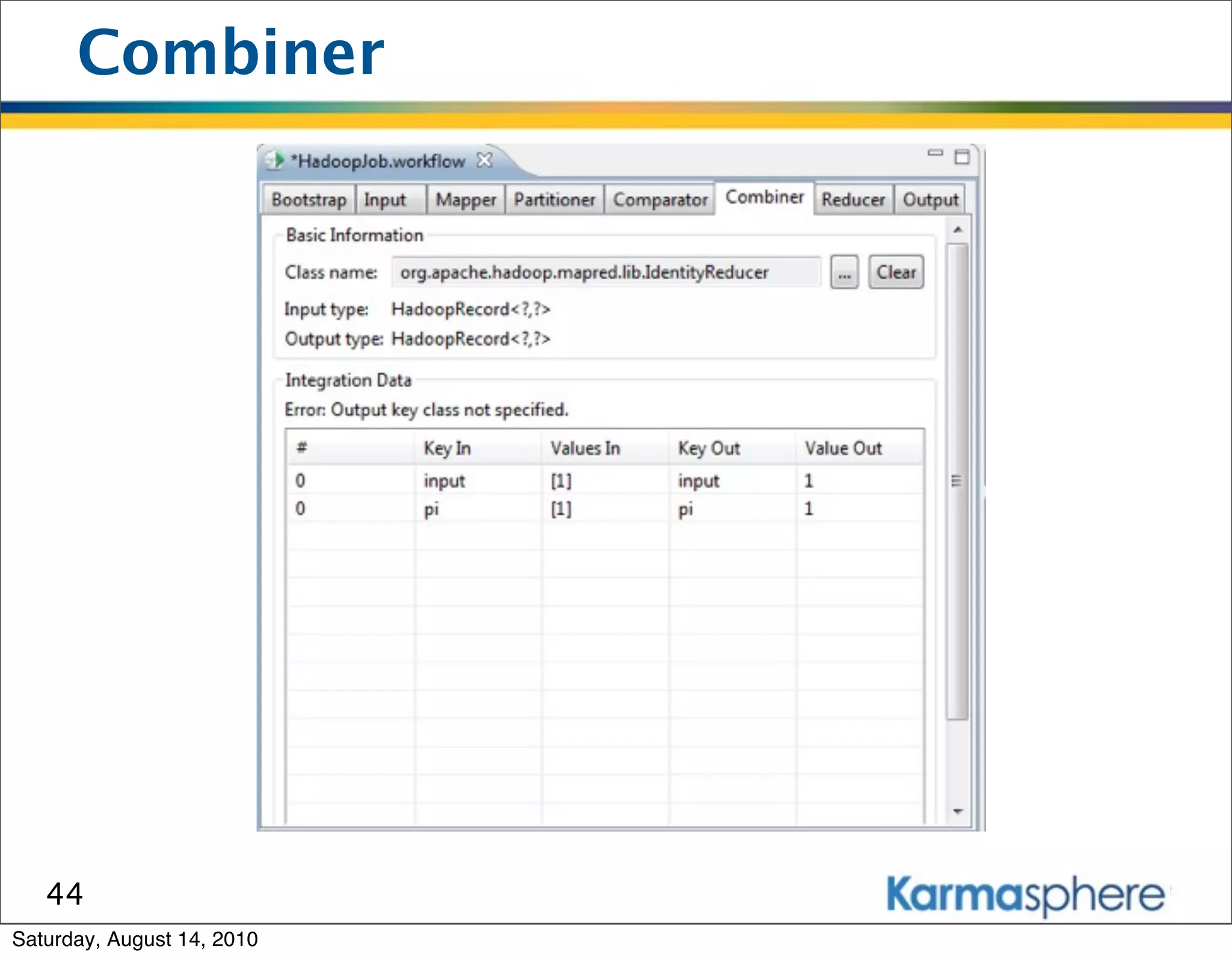
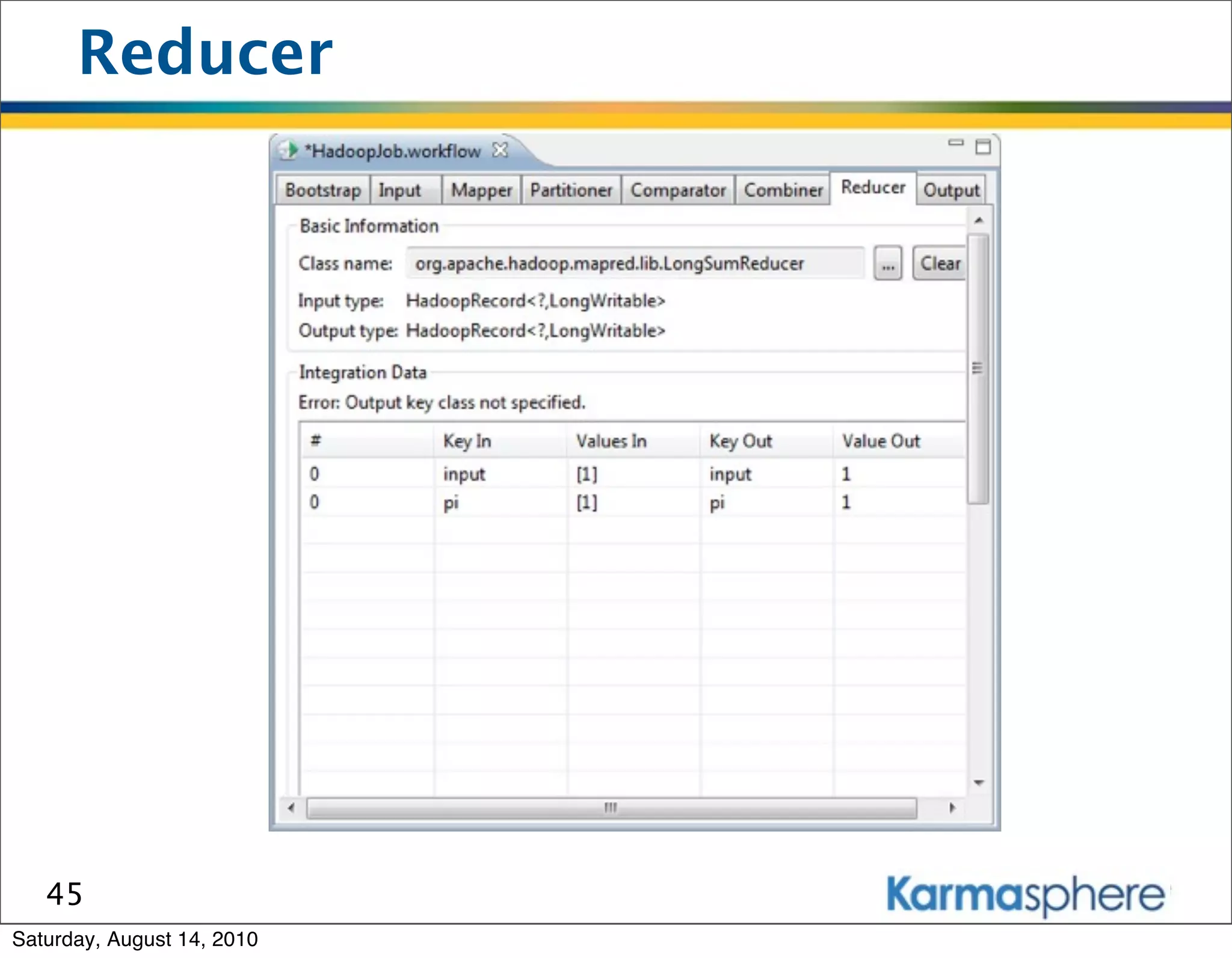
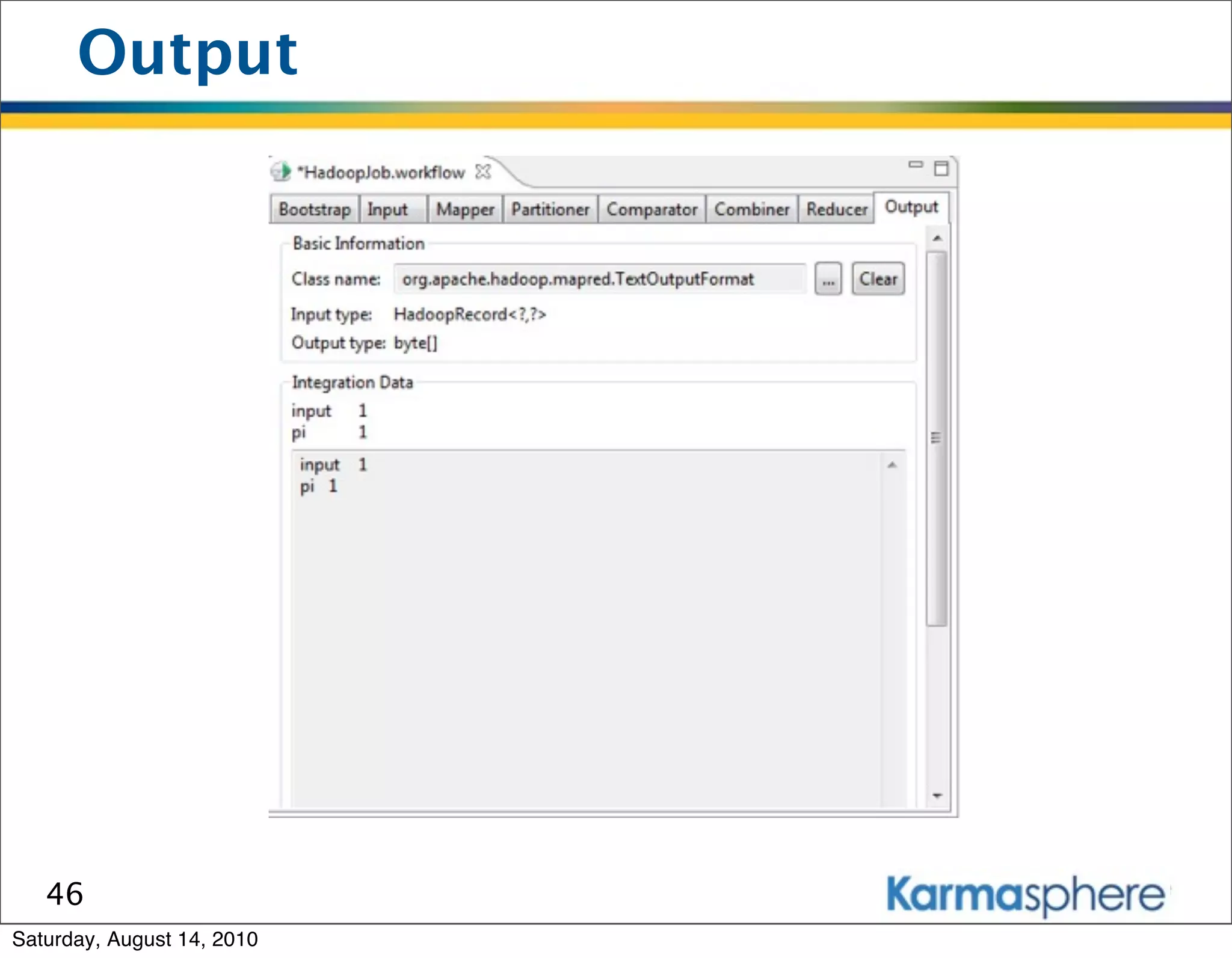


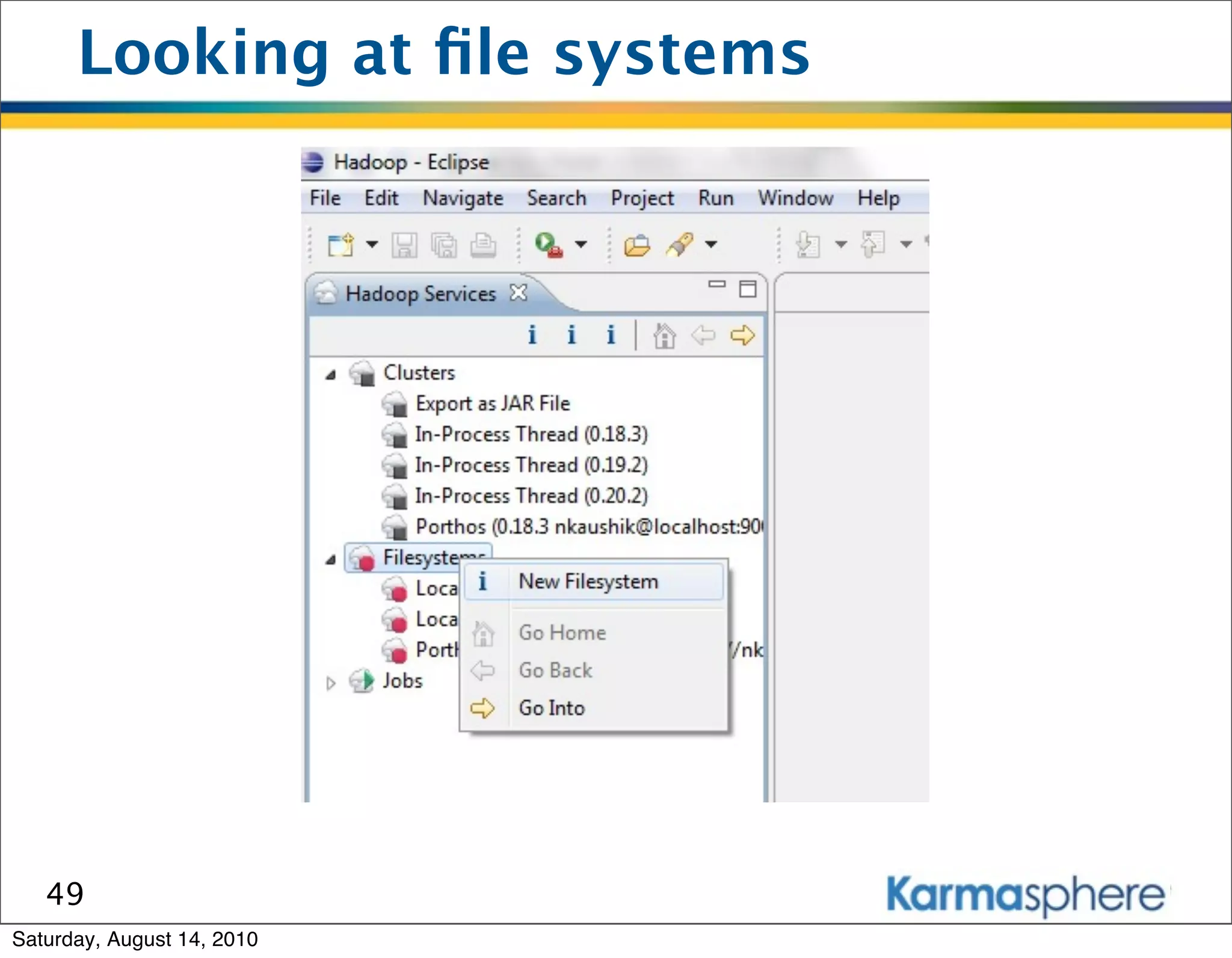
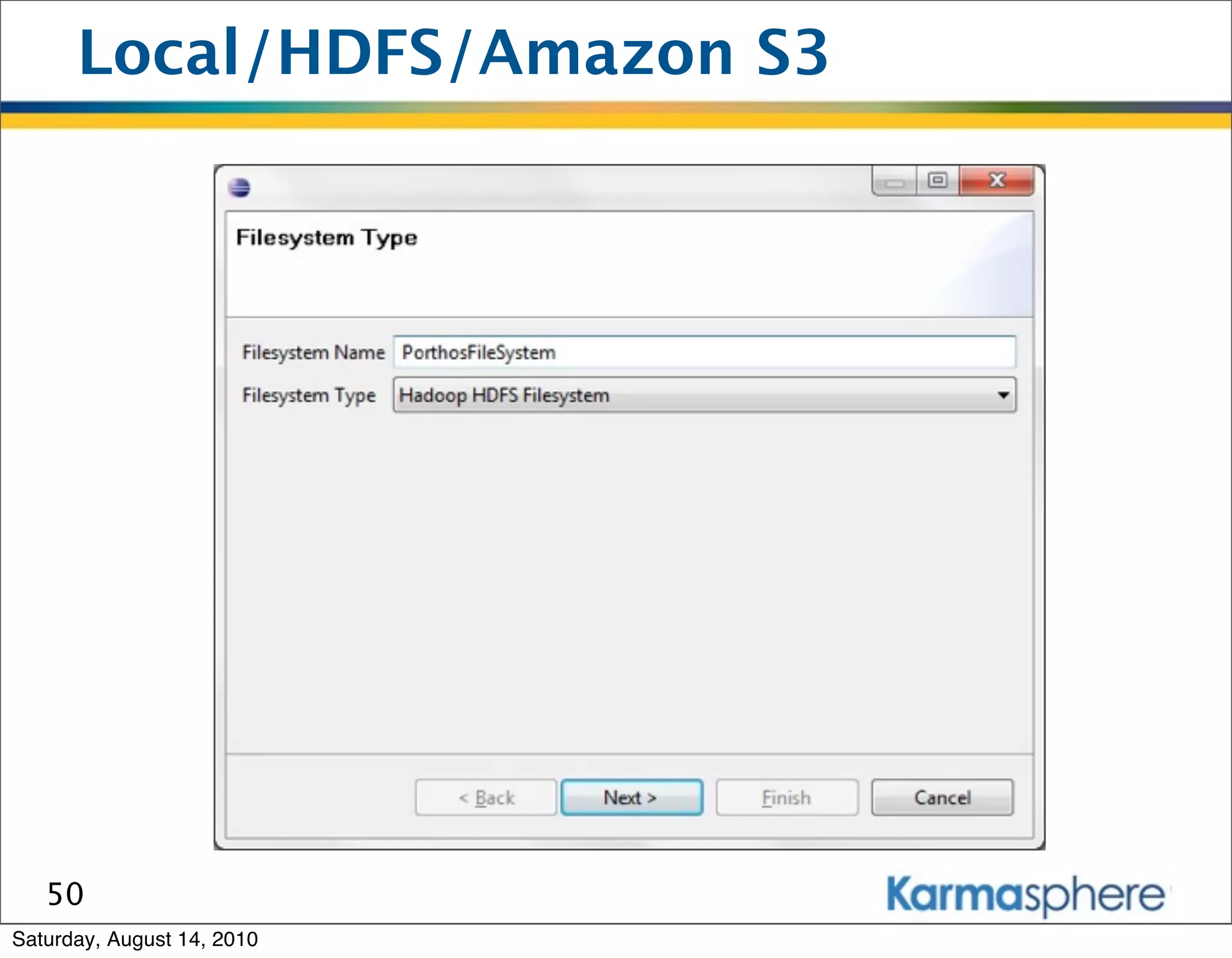
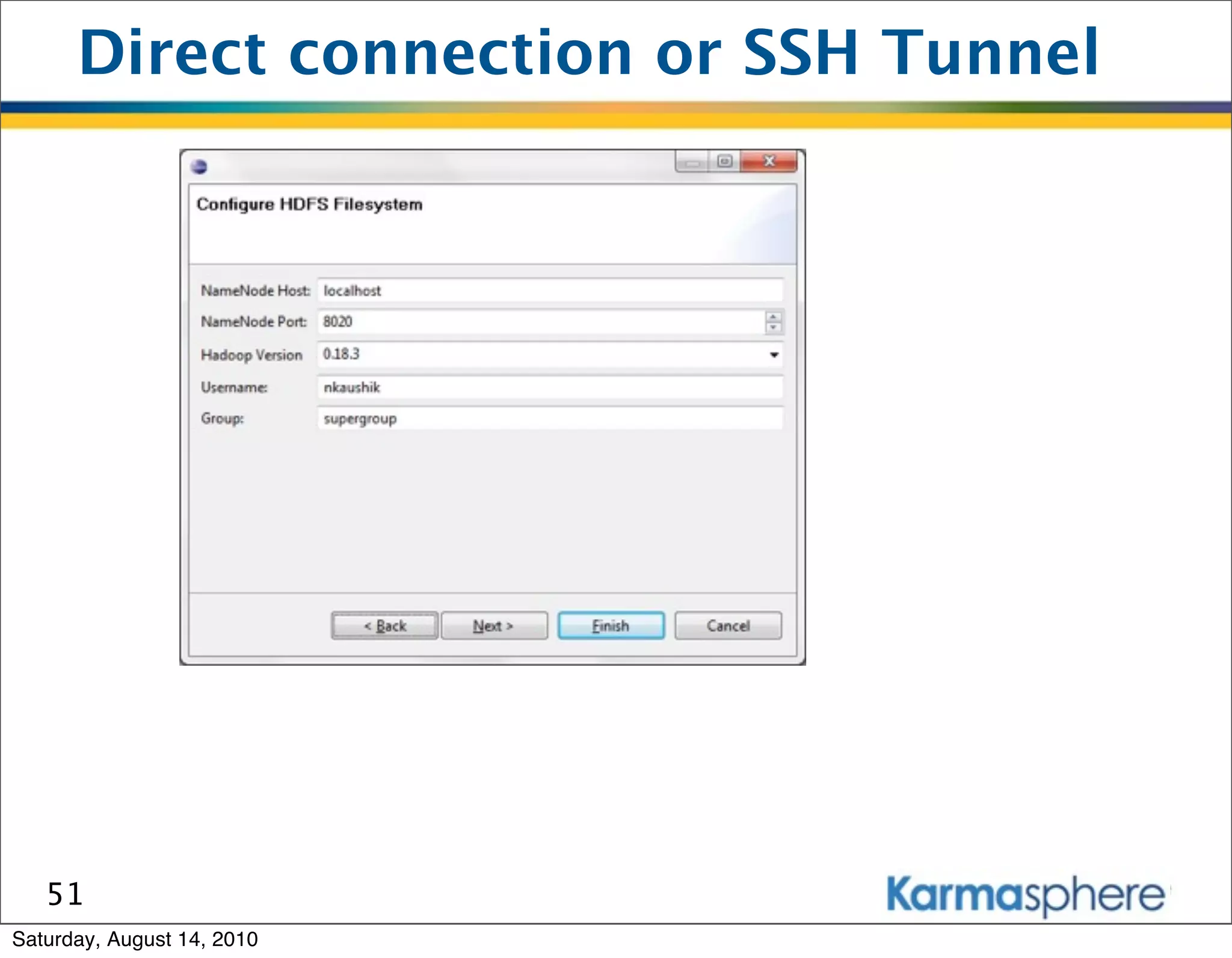
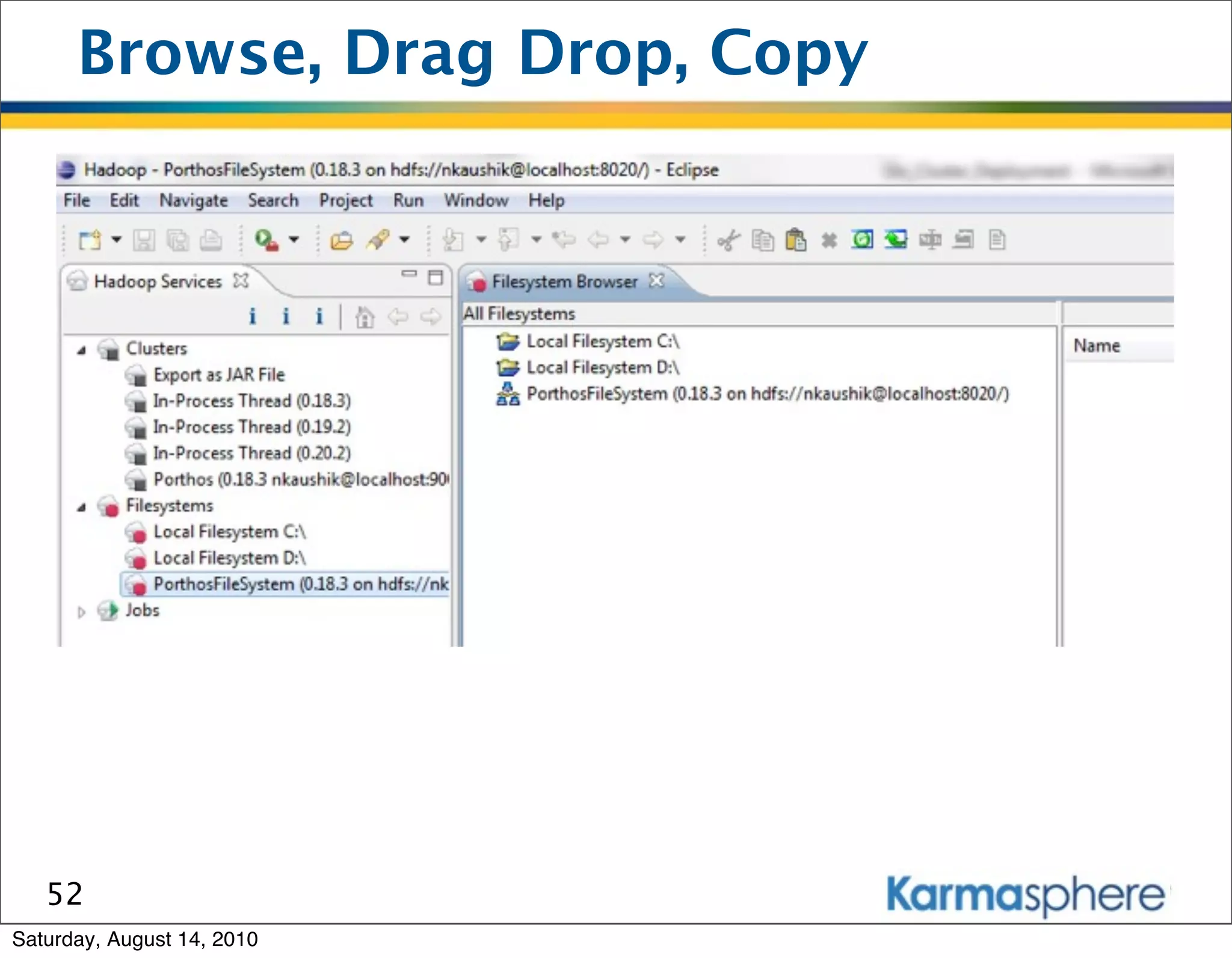
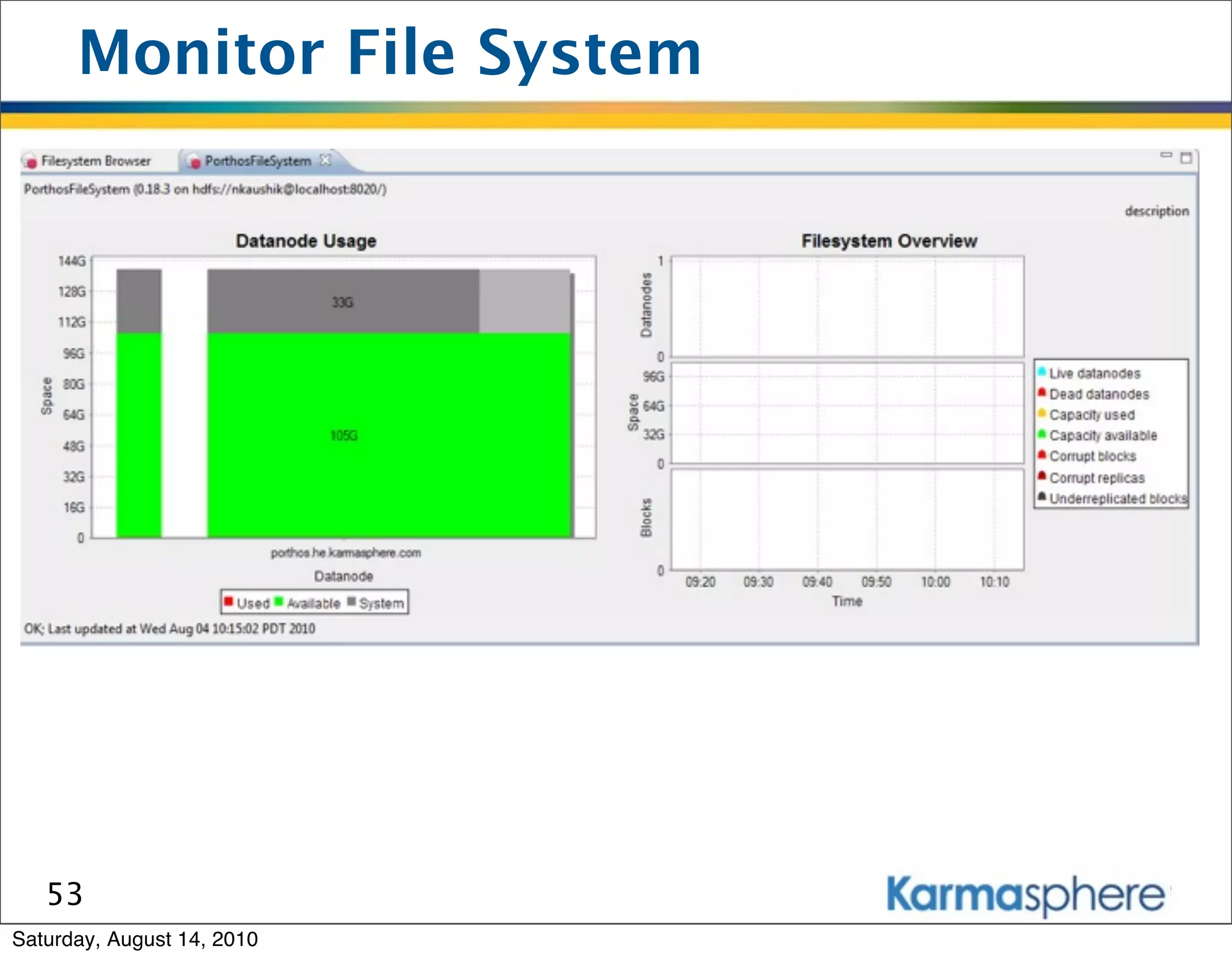

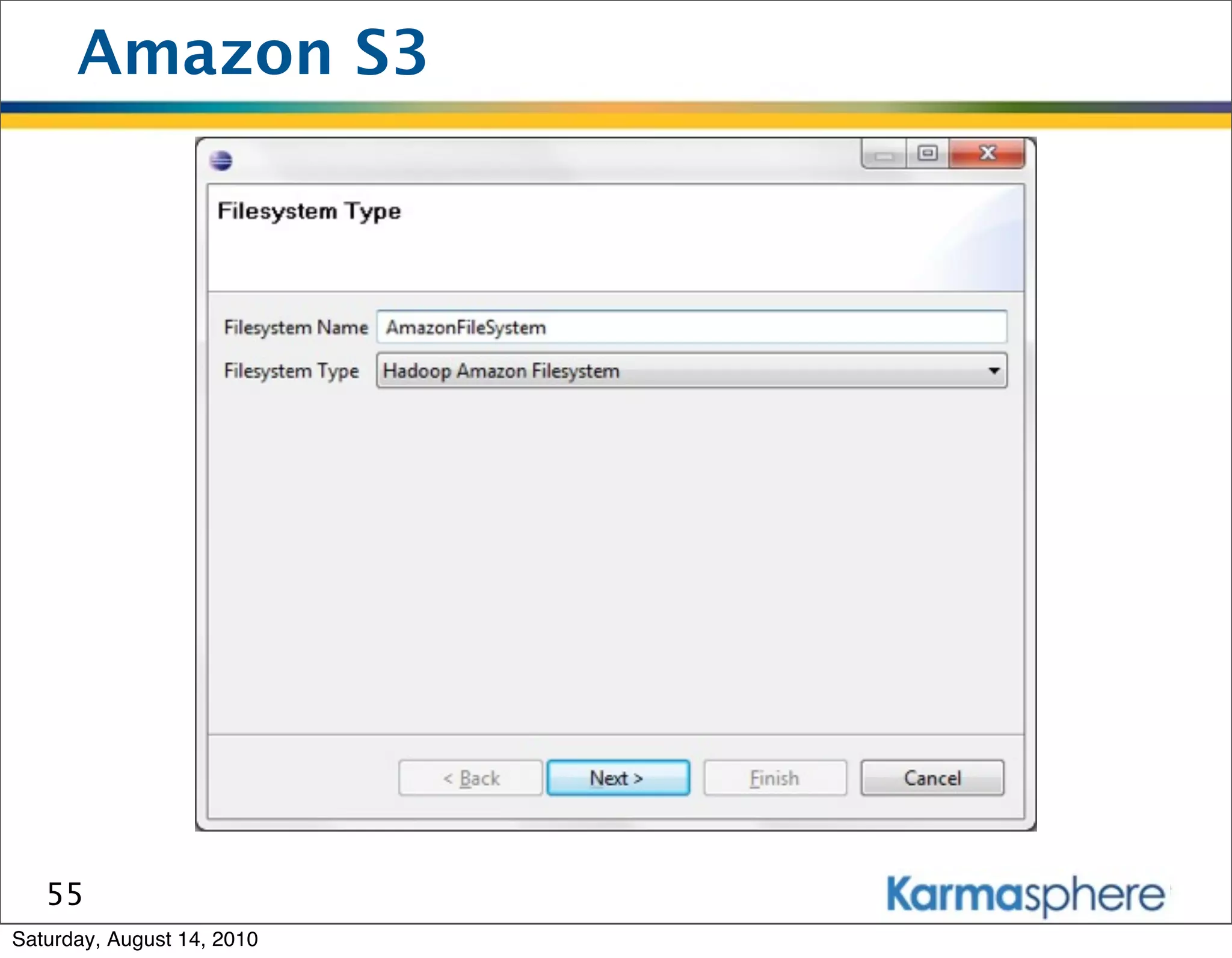
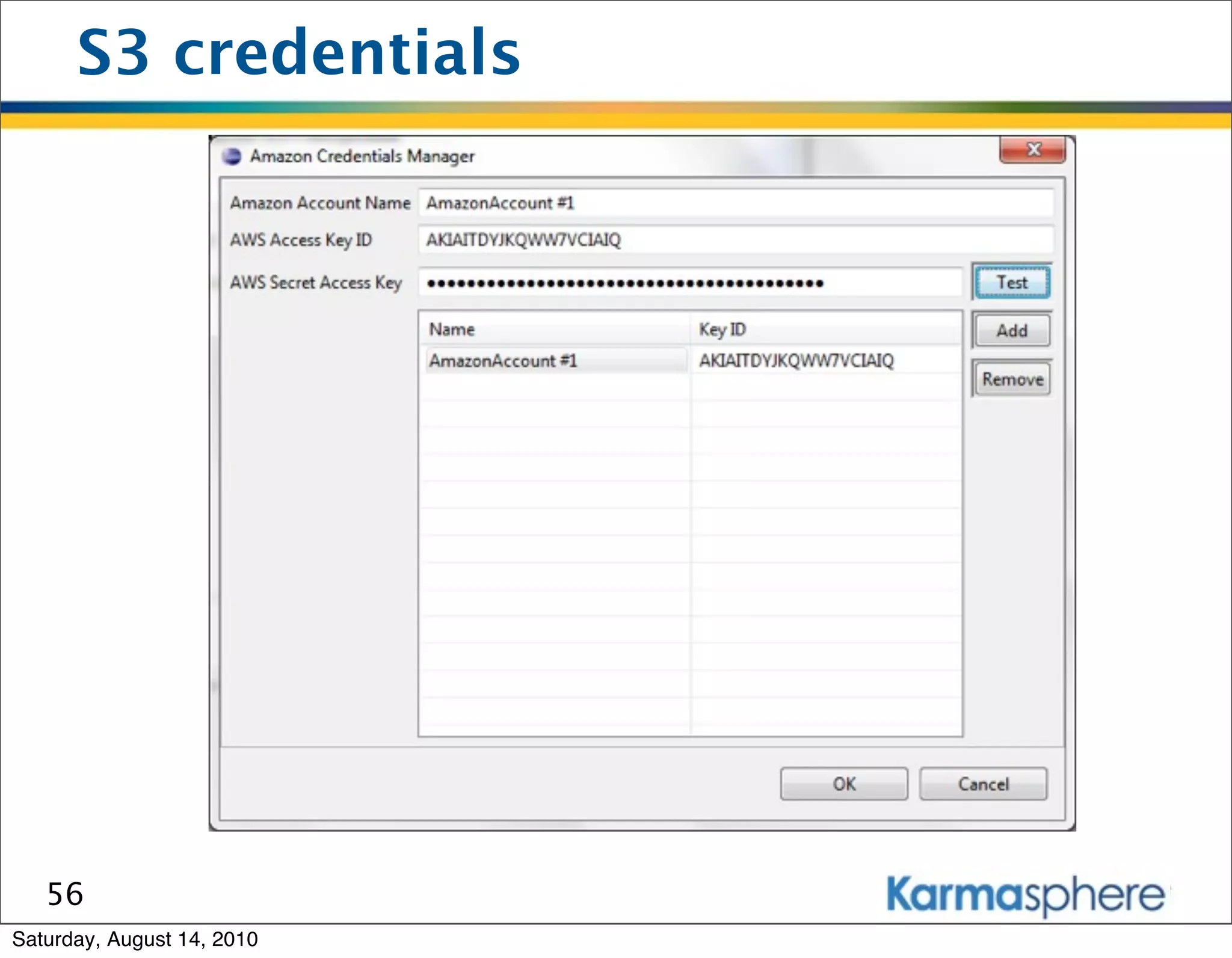
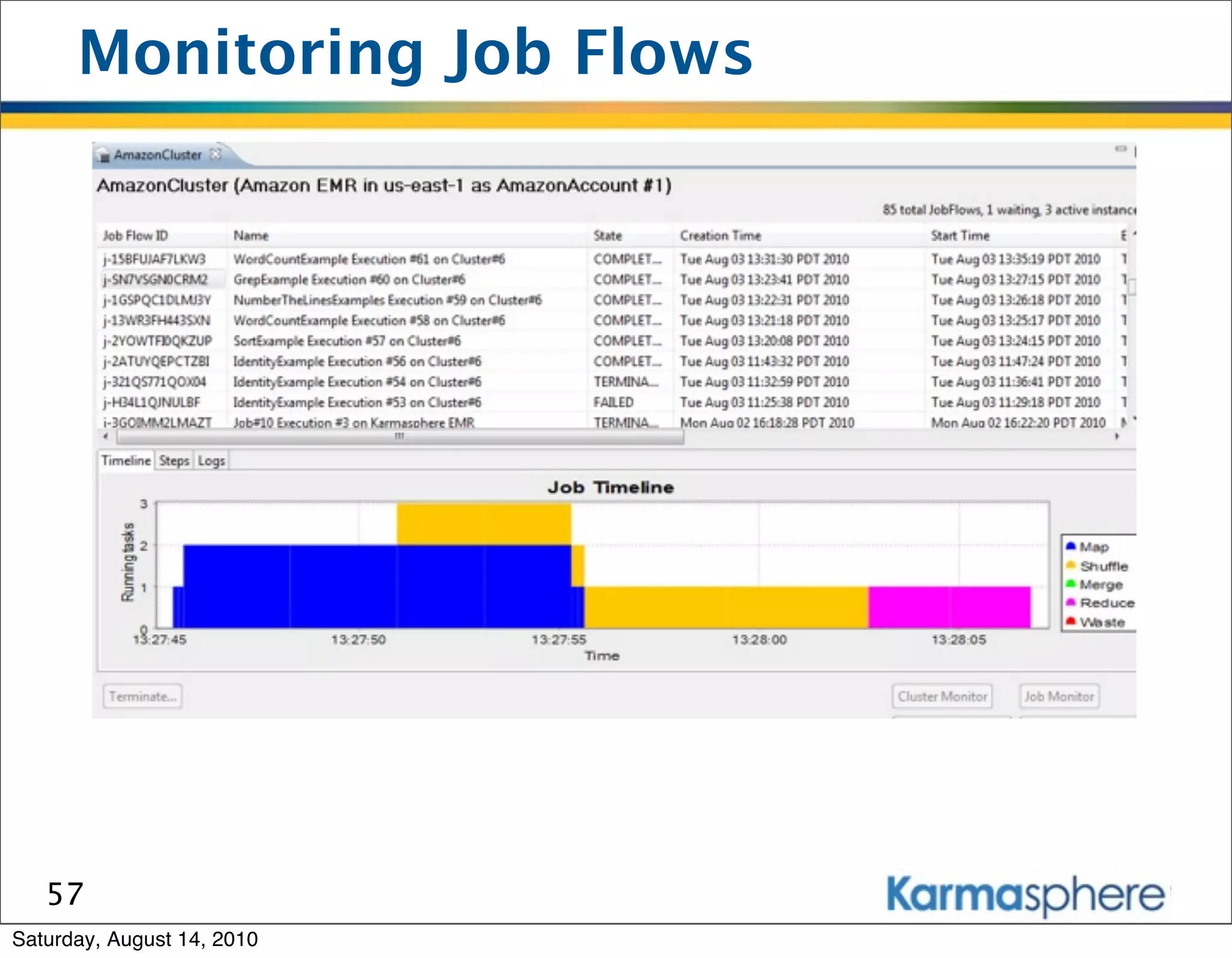
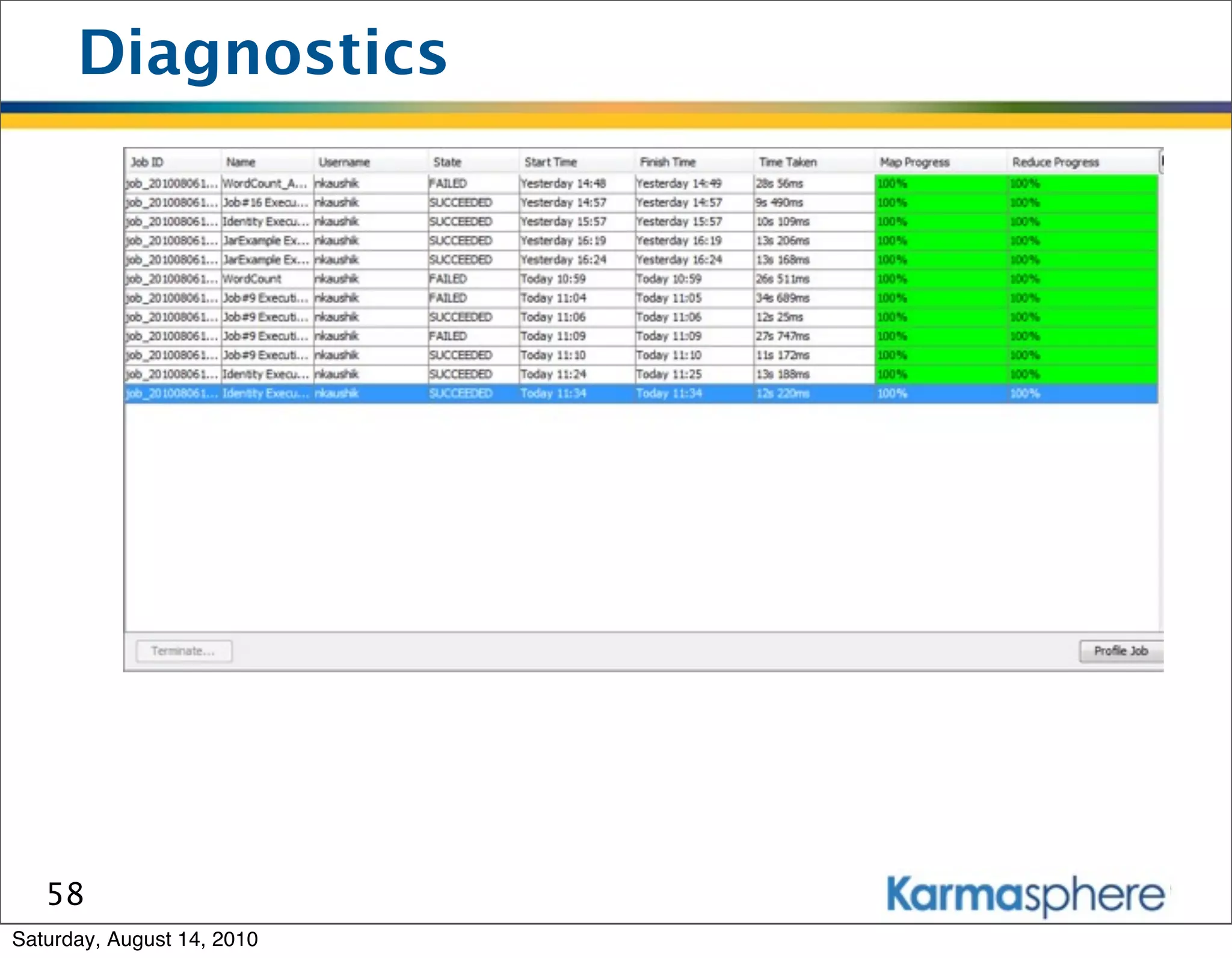

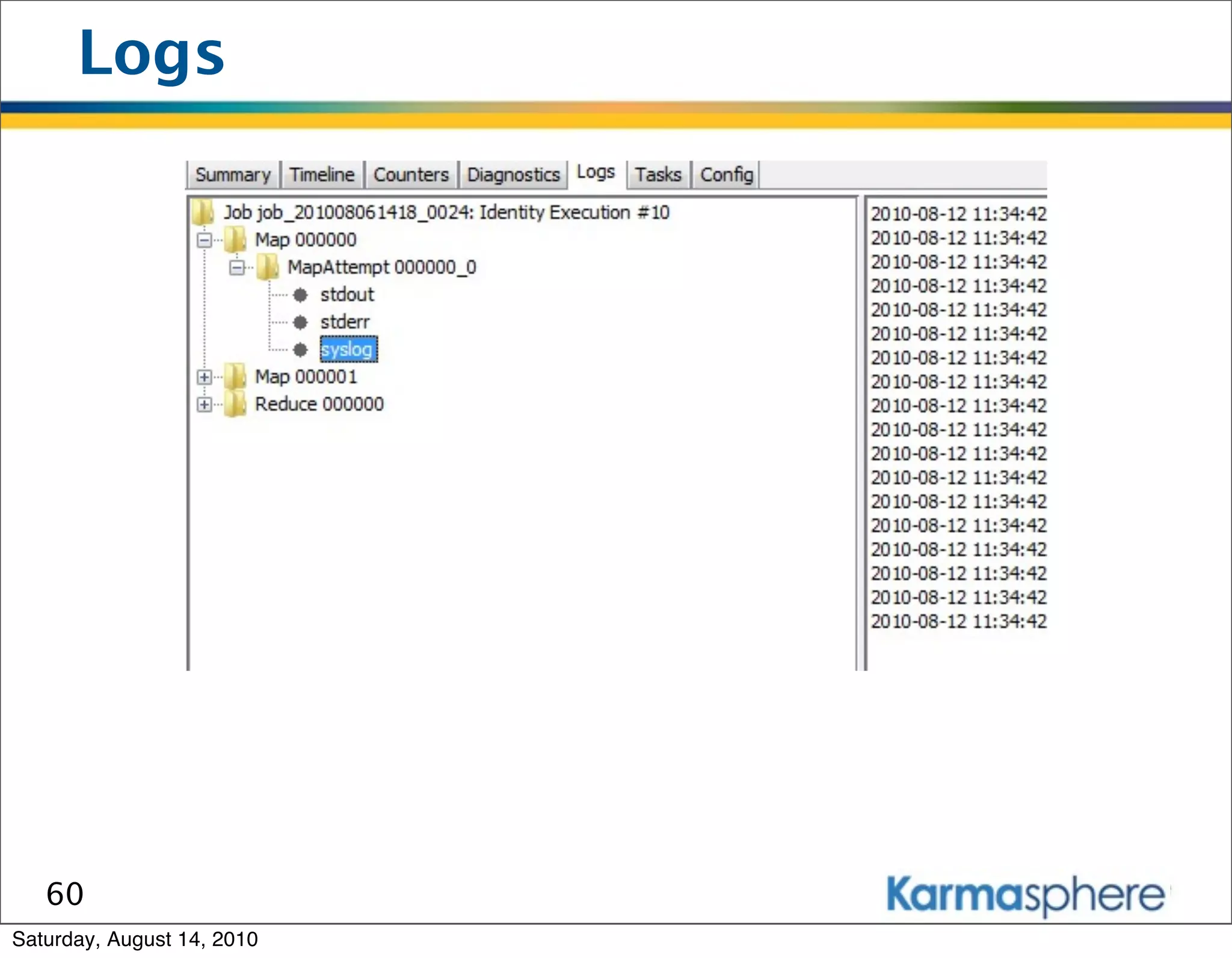
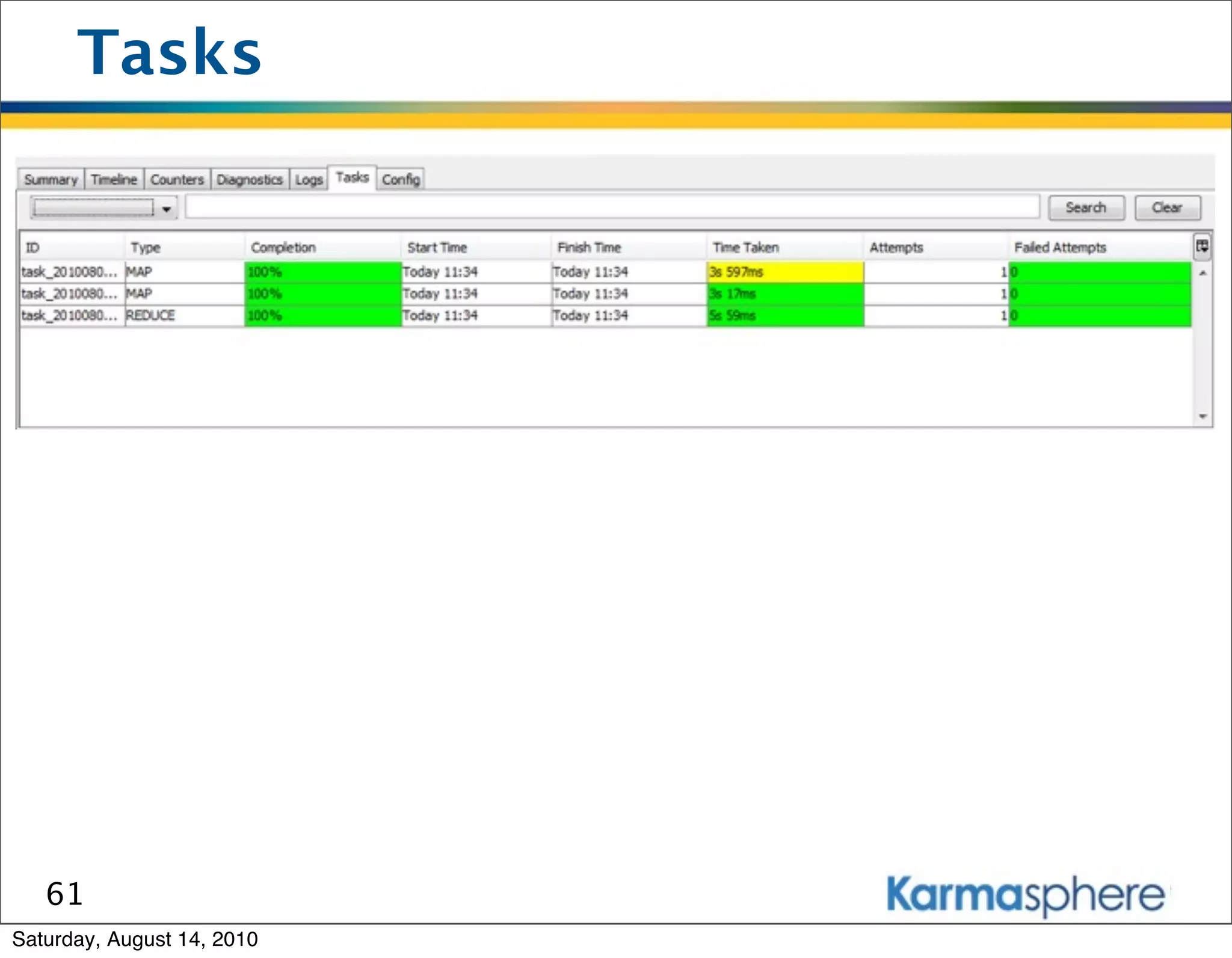





The document is a presentation on Hadoop and MapReduce frameworks. It begins with an agenda that includes background on Hadoop, its architecture including HDFS and MapReduce, example jobs, Karmasphere Studio tool, and related technologies. It then goes into more detail on topics like motivation for Hadoop due to big data, HDFS and MapReduce frameworks, example jobs like word count and max/sum functions written in MapReduce, and use of Karmasphere Studio for local development and testing of MapReduce jobs.
















































![[Harvard CS264] 08b - MapReduce and Hadoop (Zak Stone, Harvard)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264hadooplecture2011-110322172329-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

























