Download to read offline


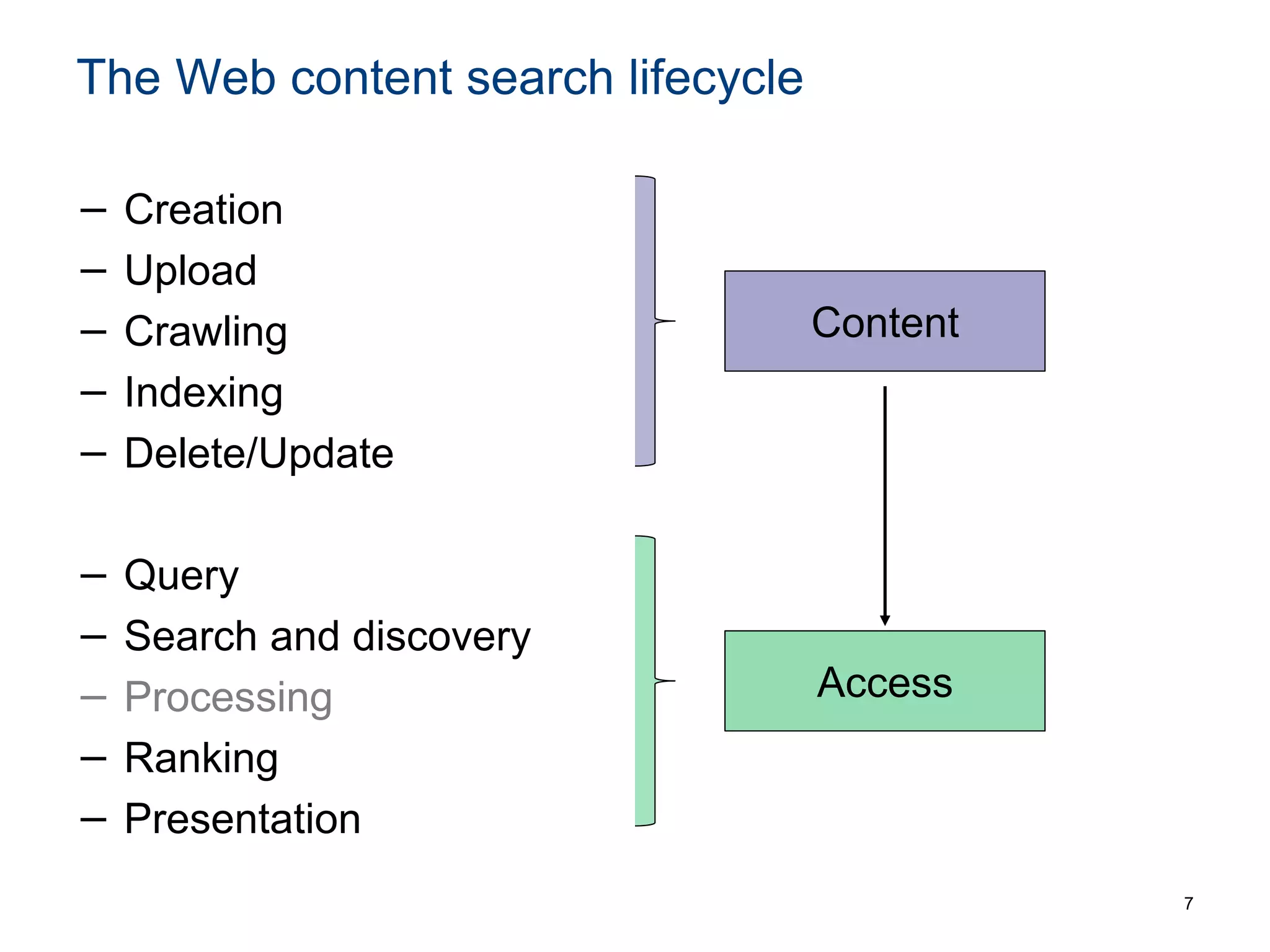
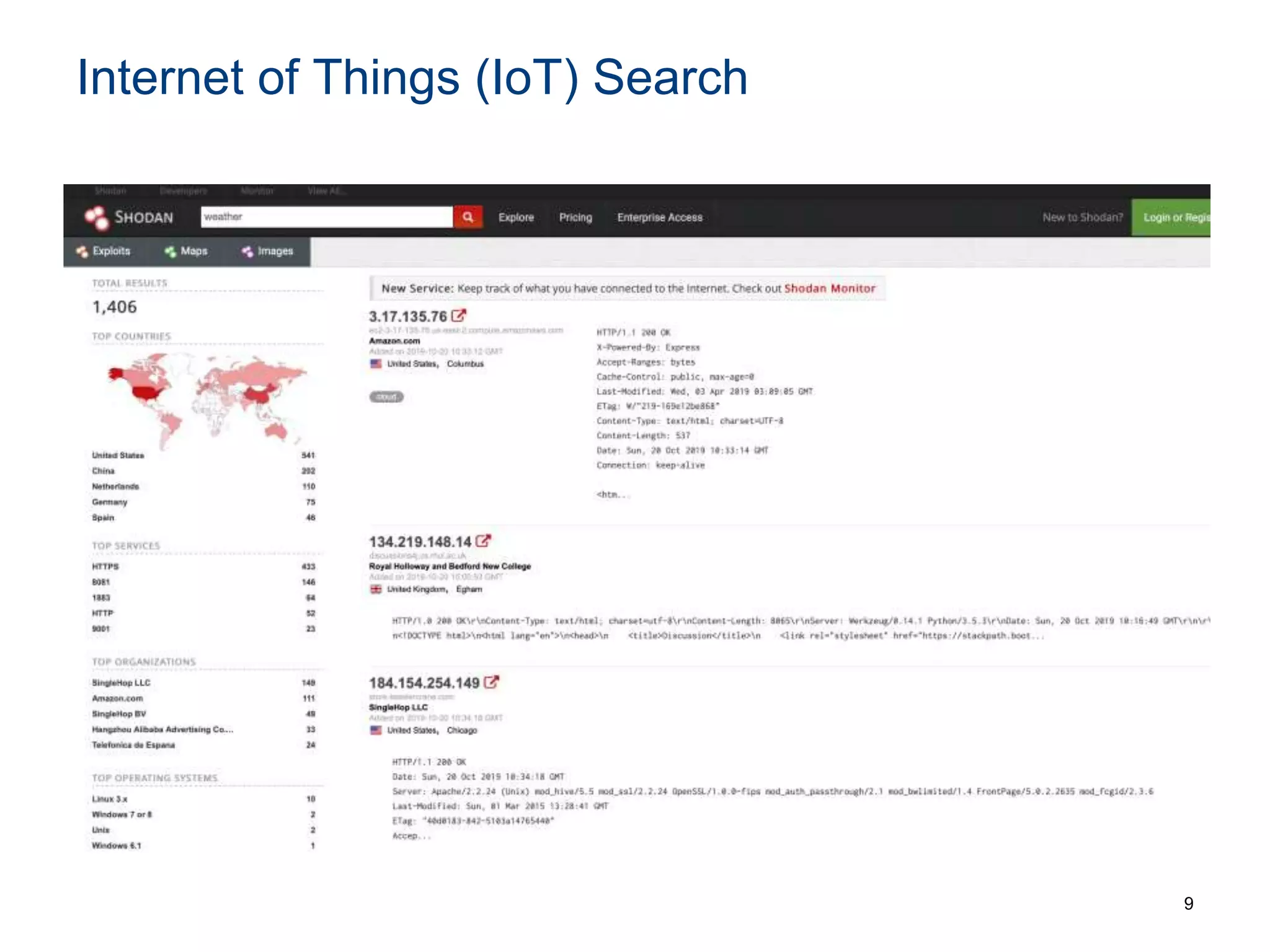
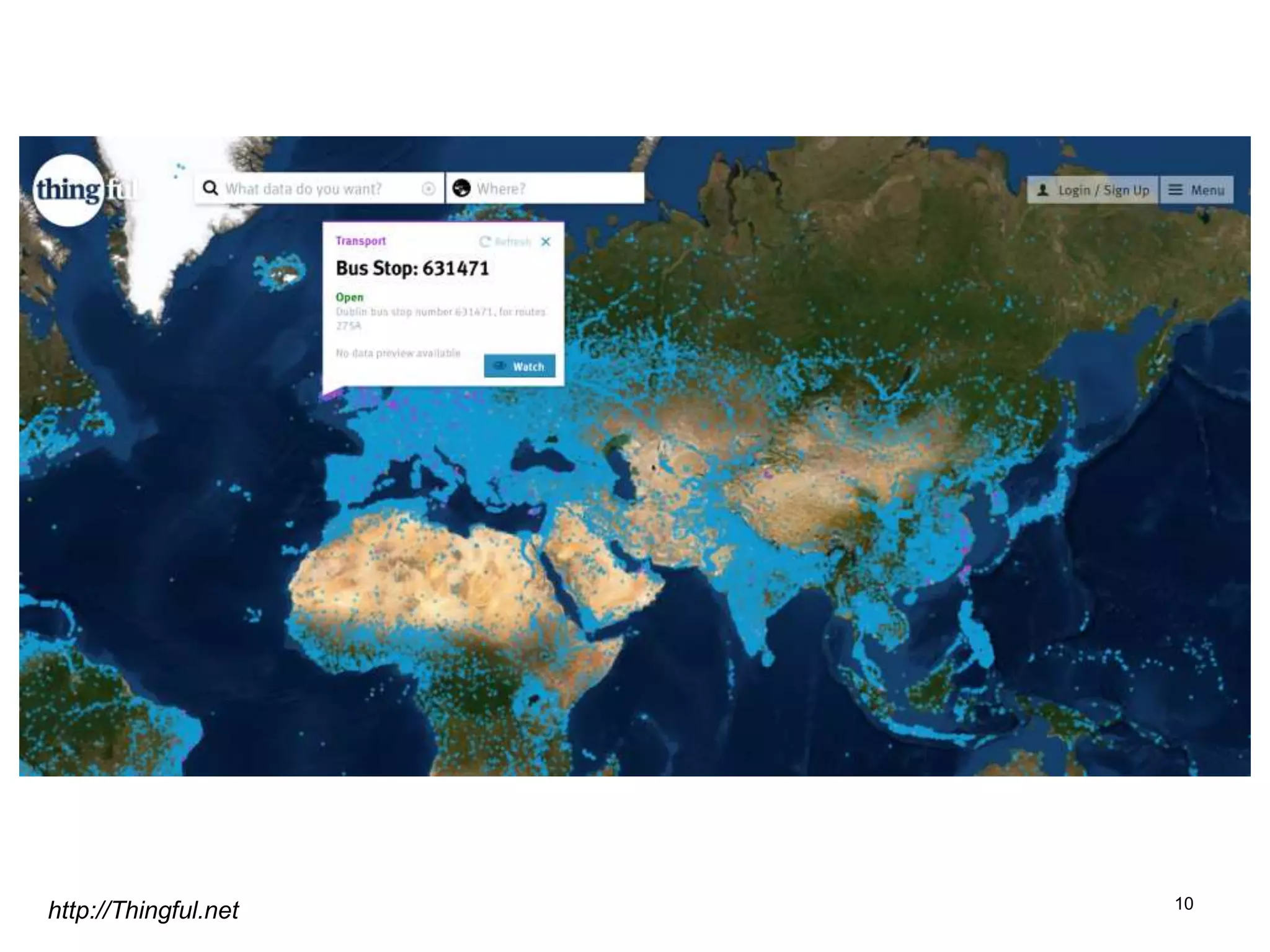
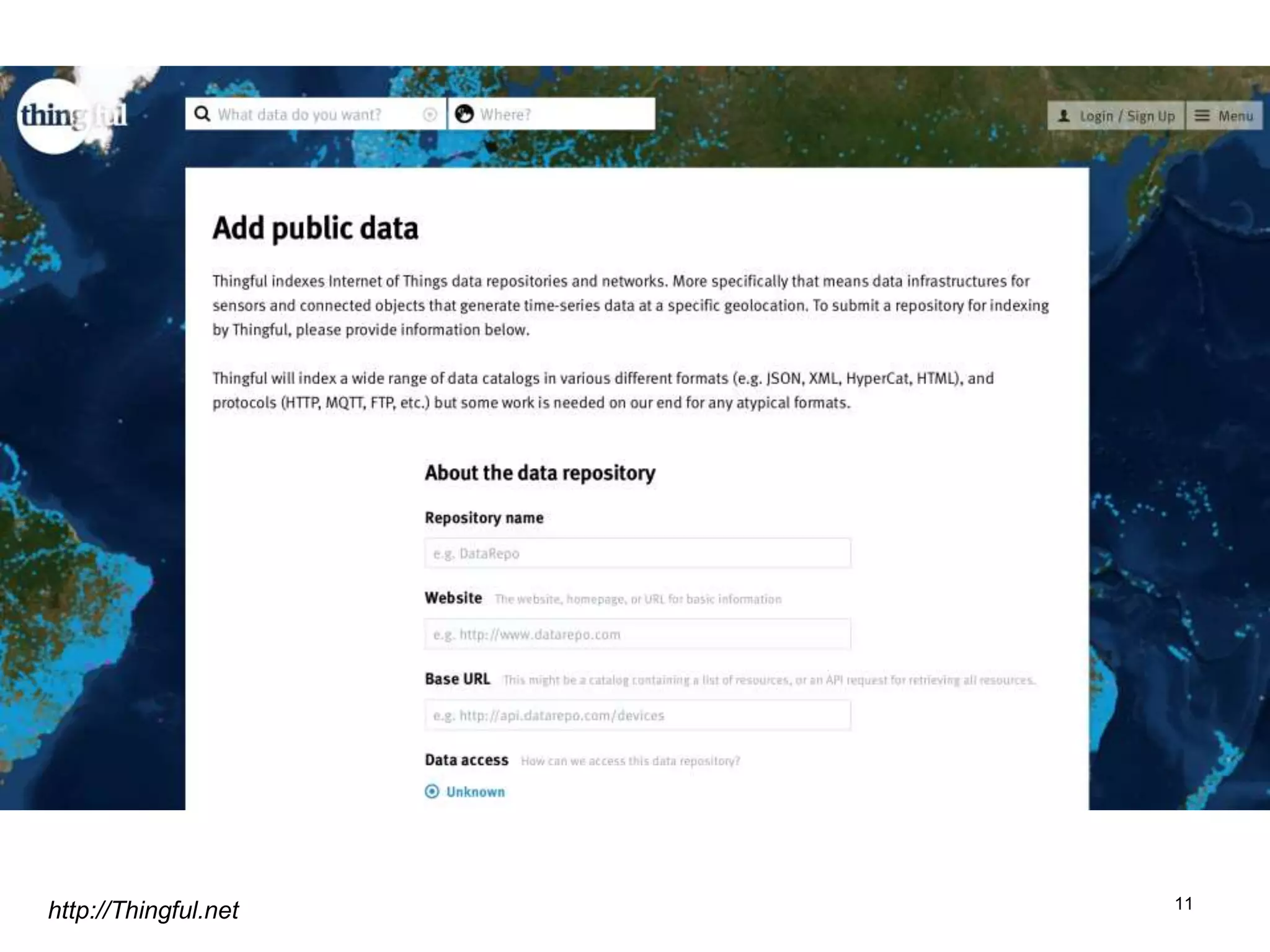
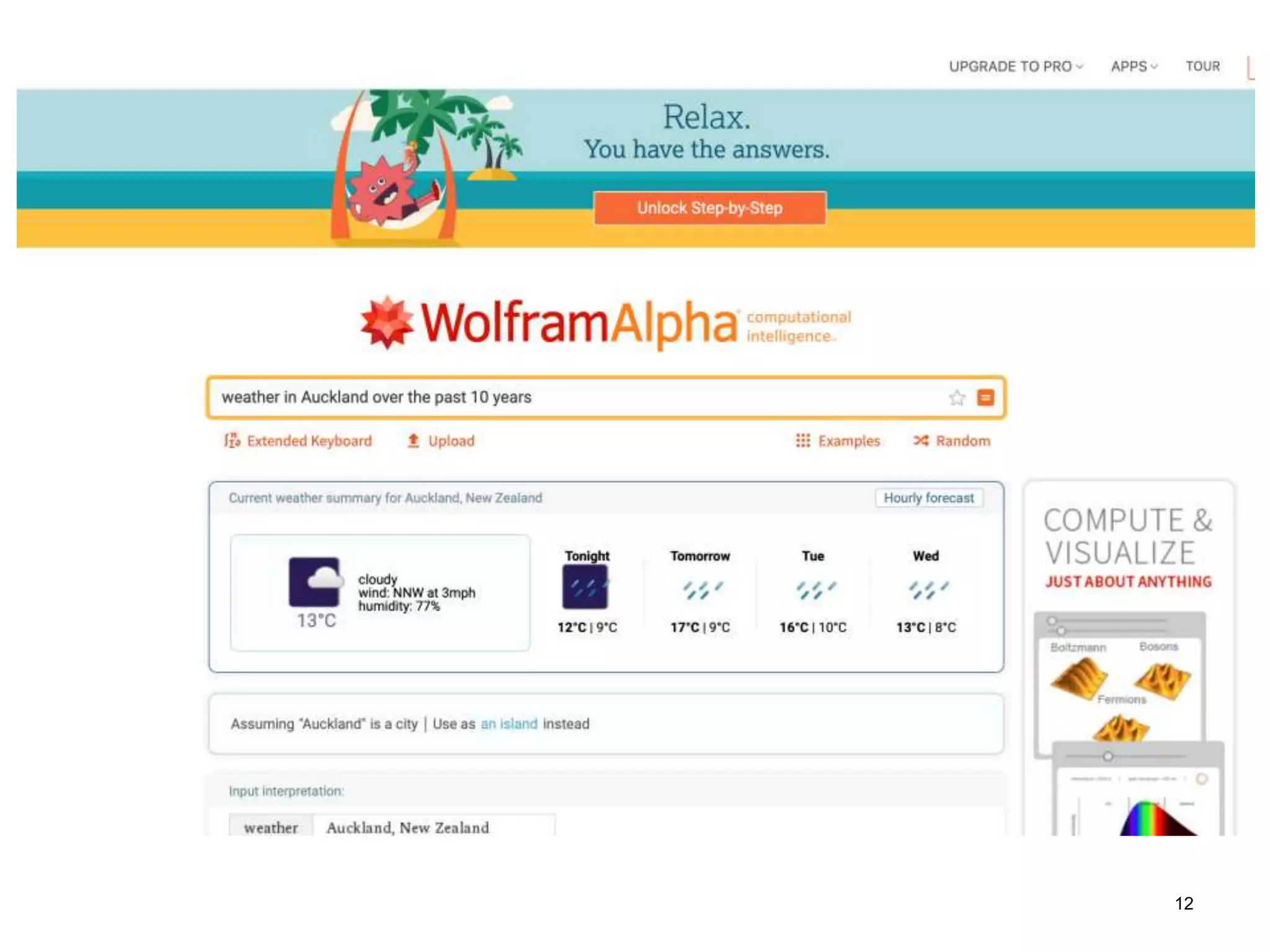
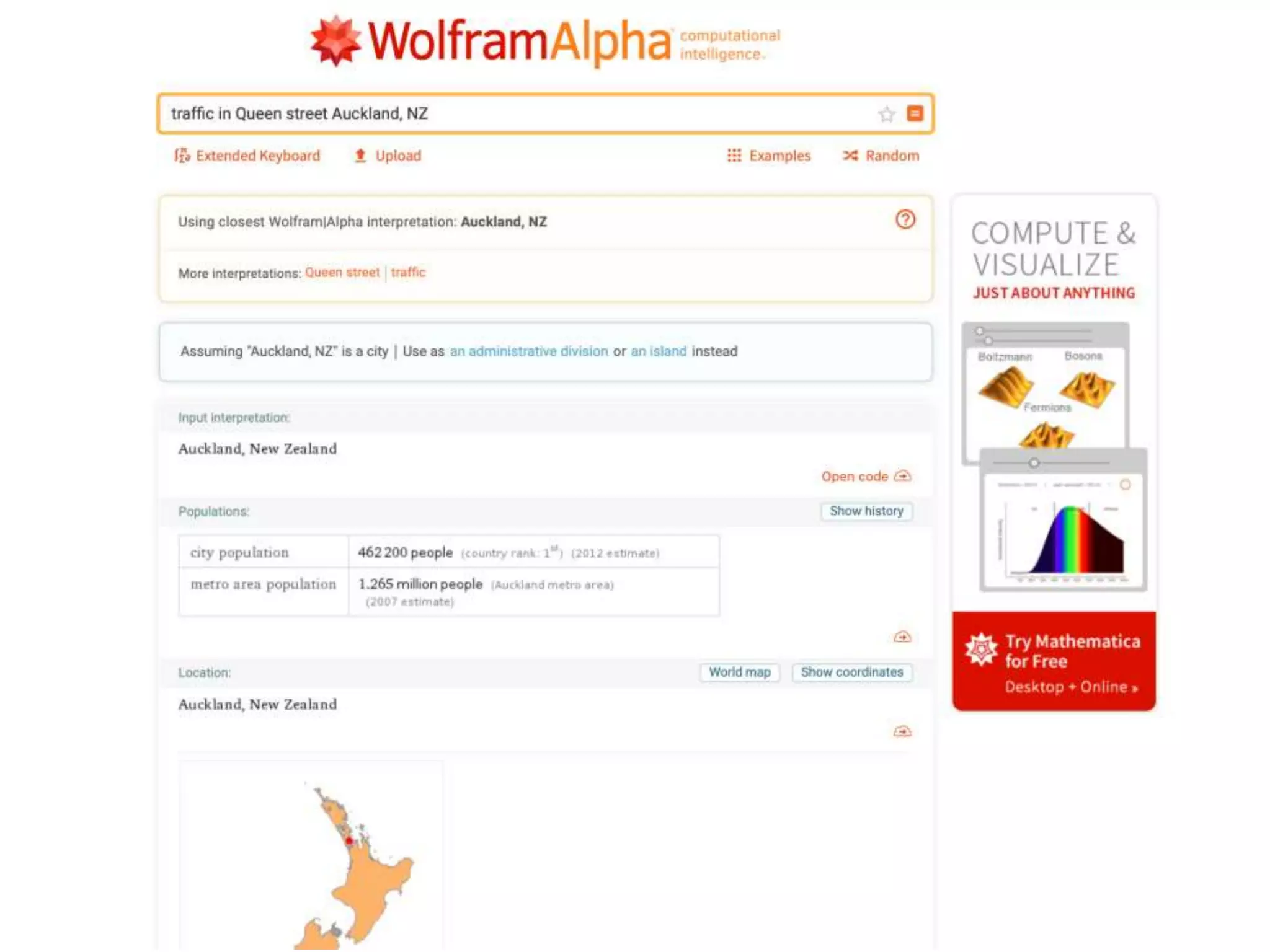
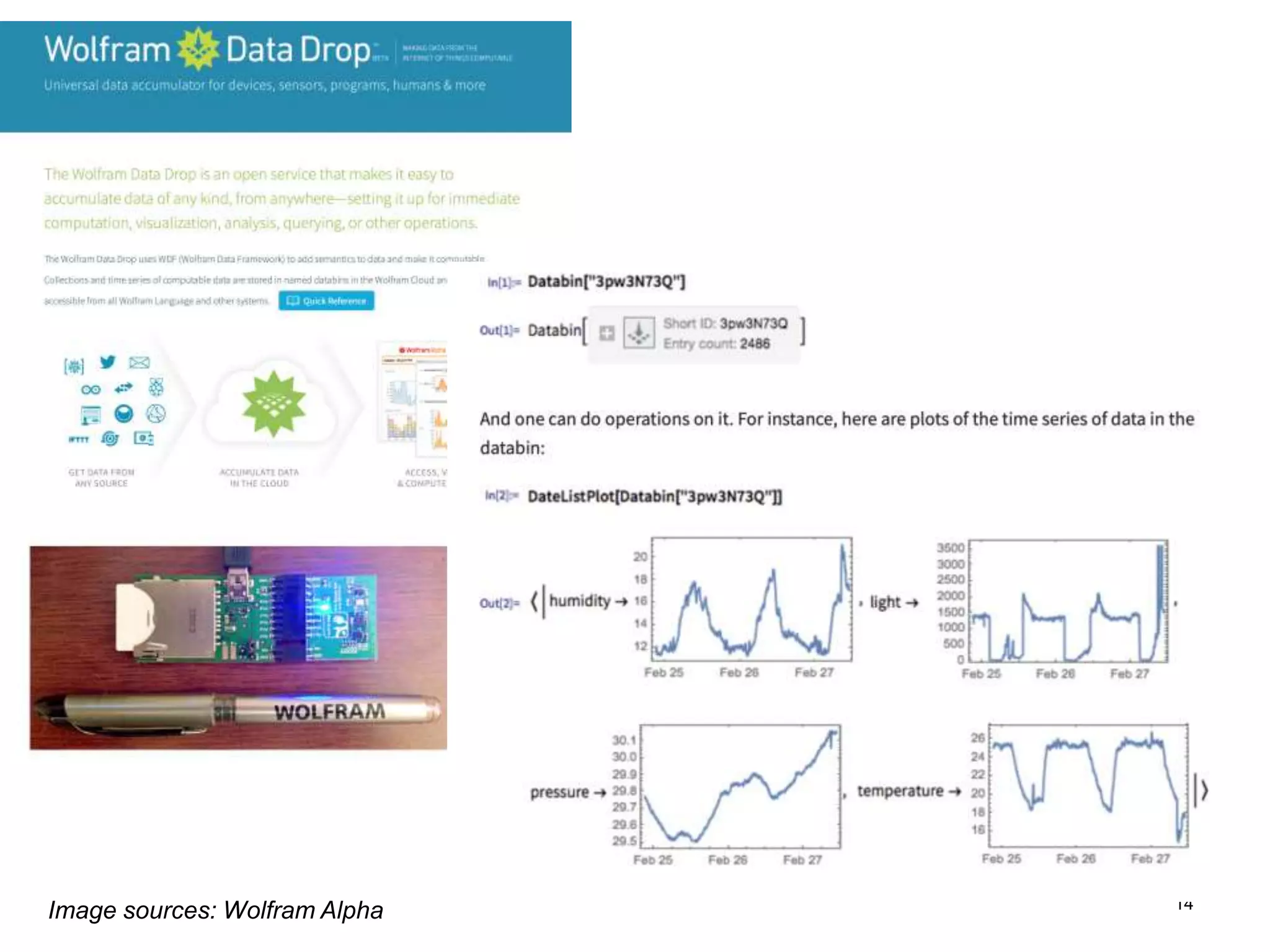
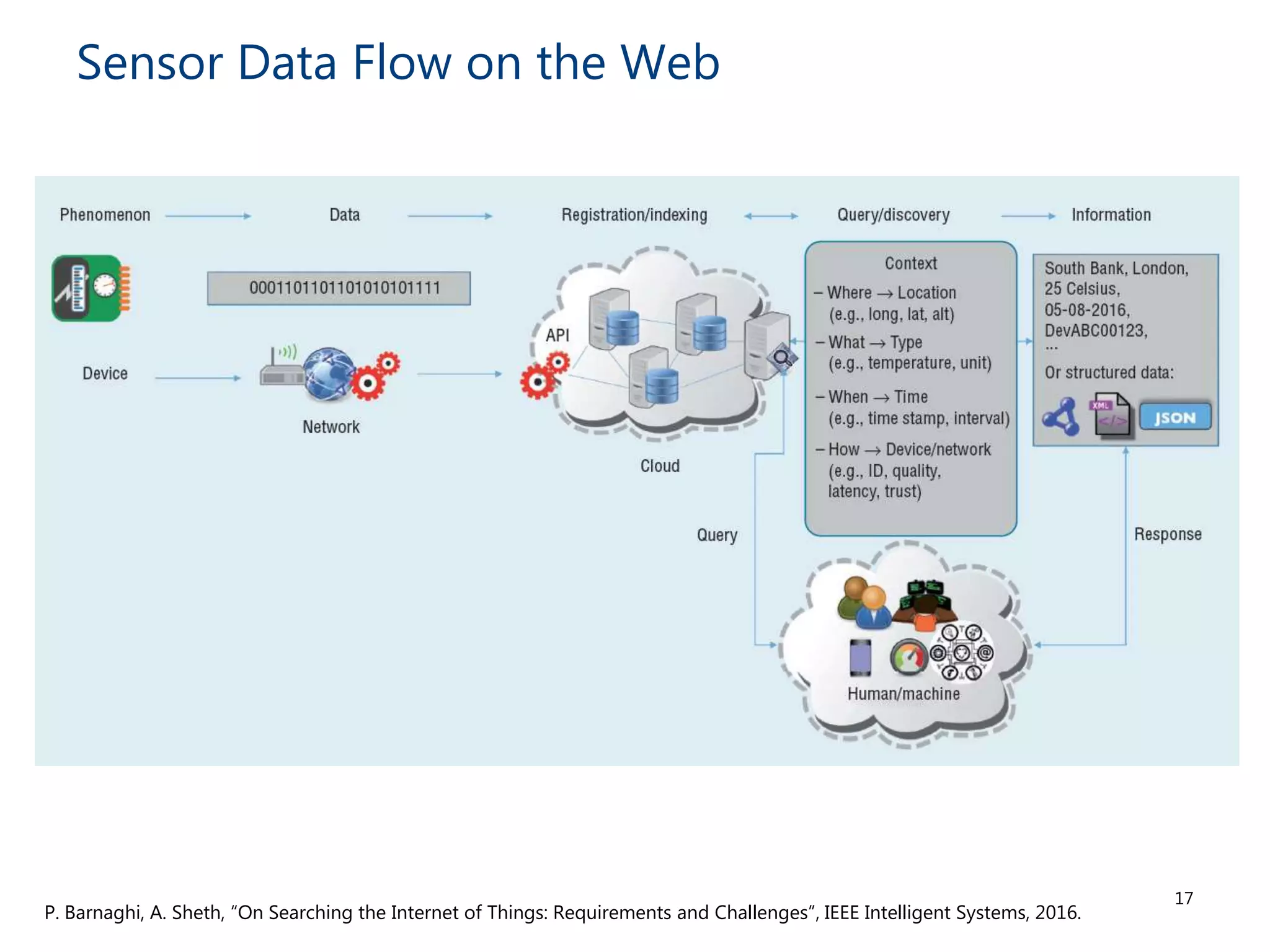
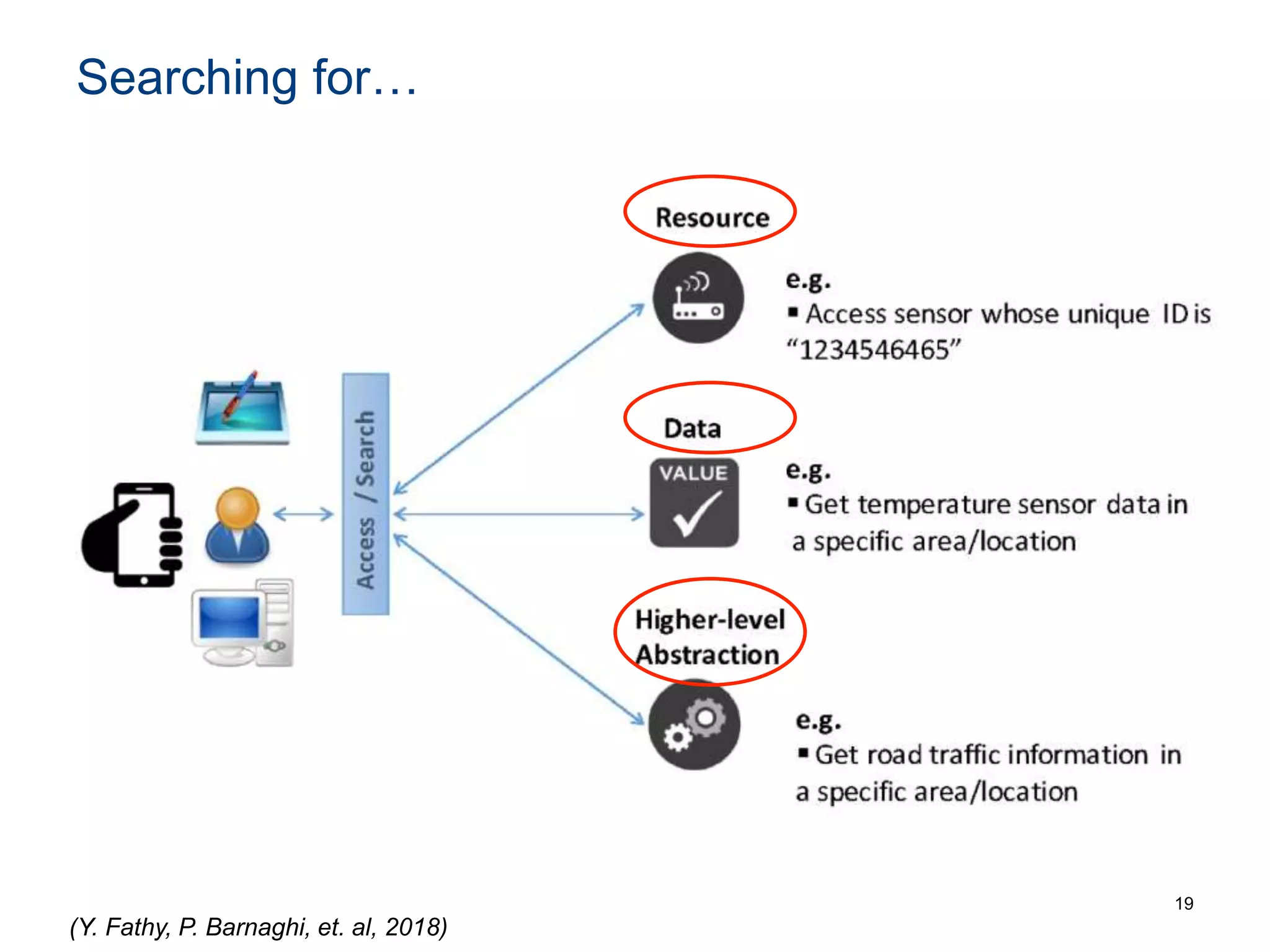


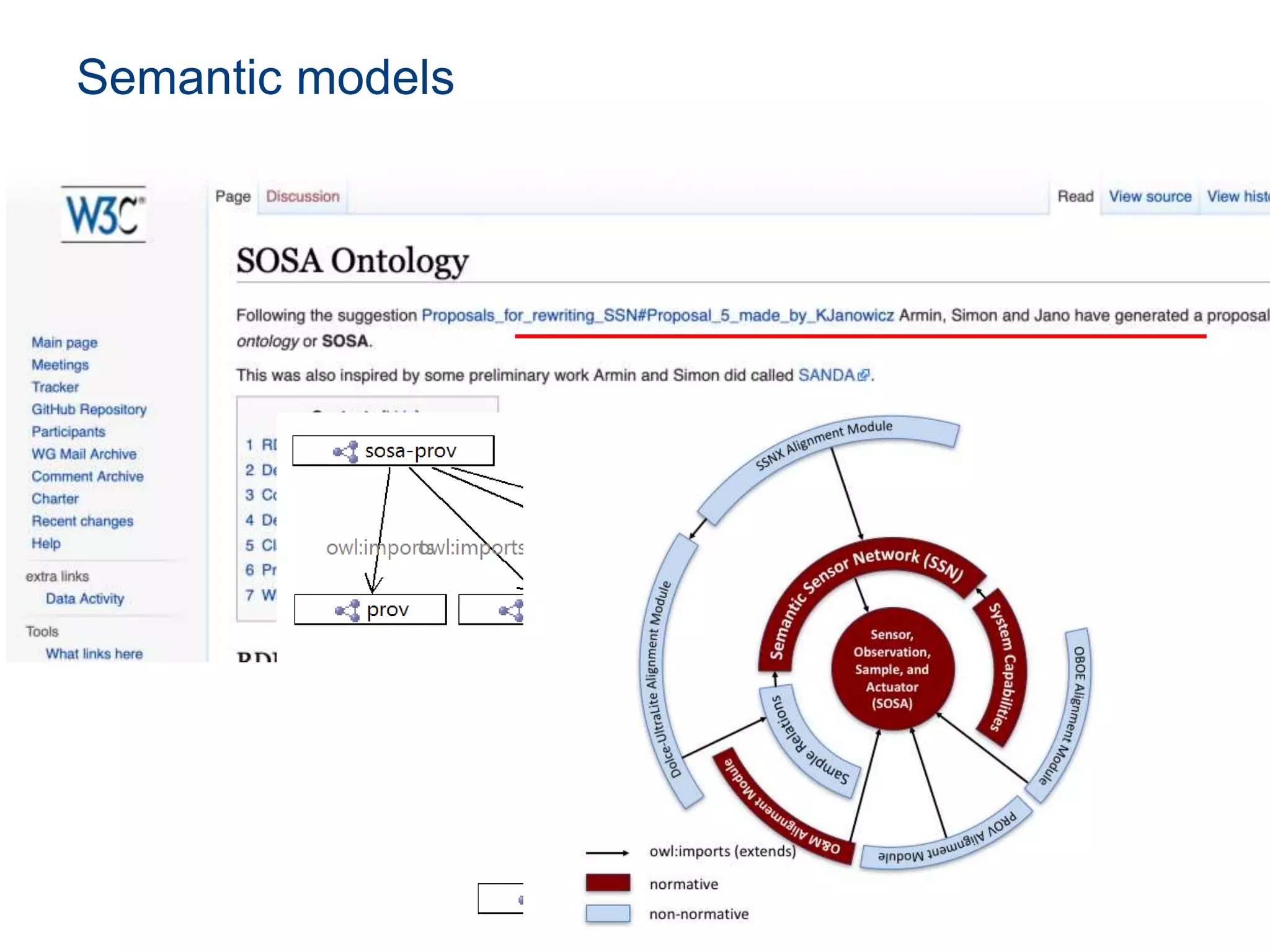
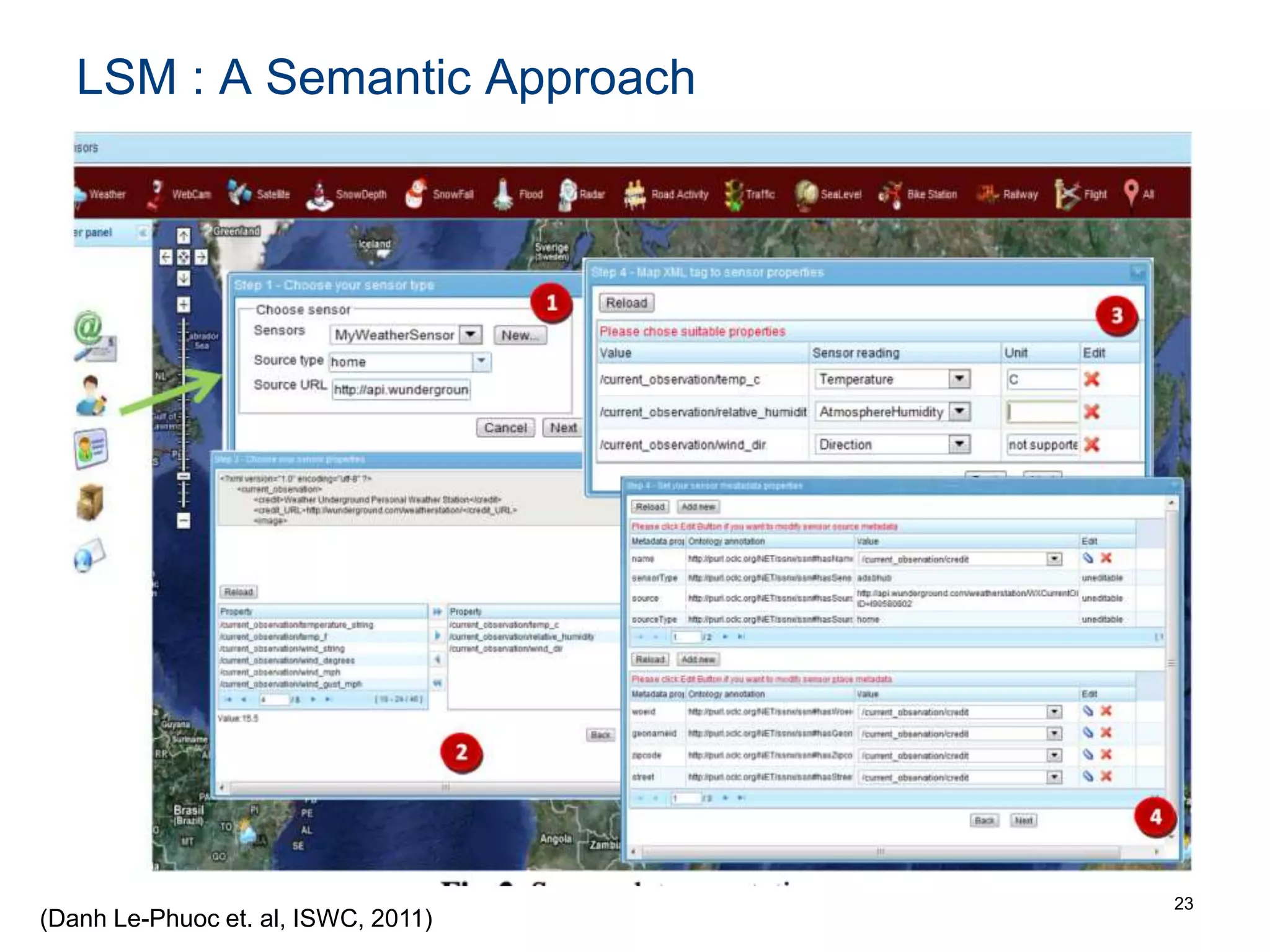
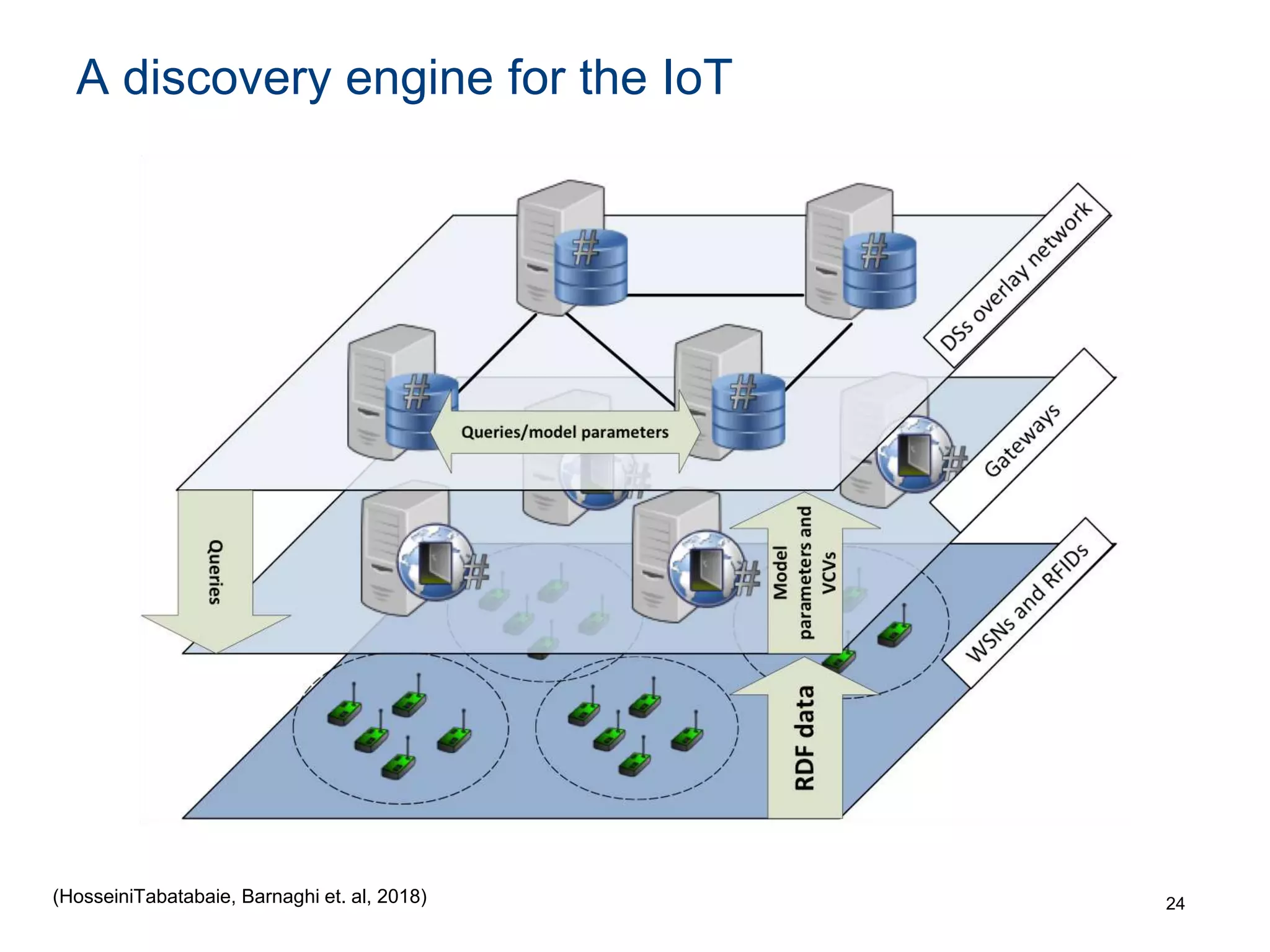
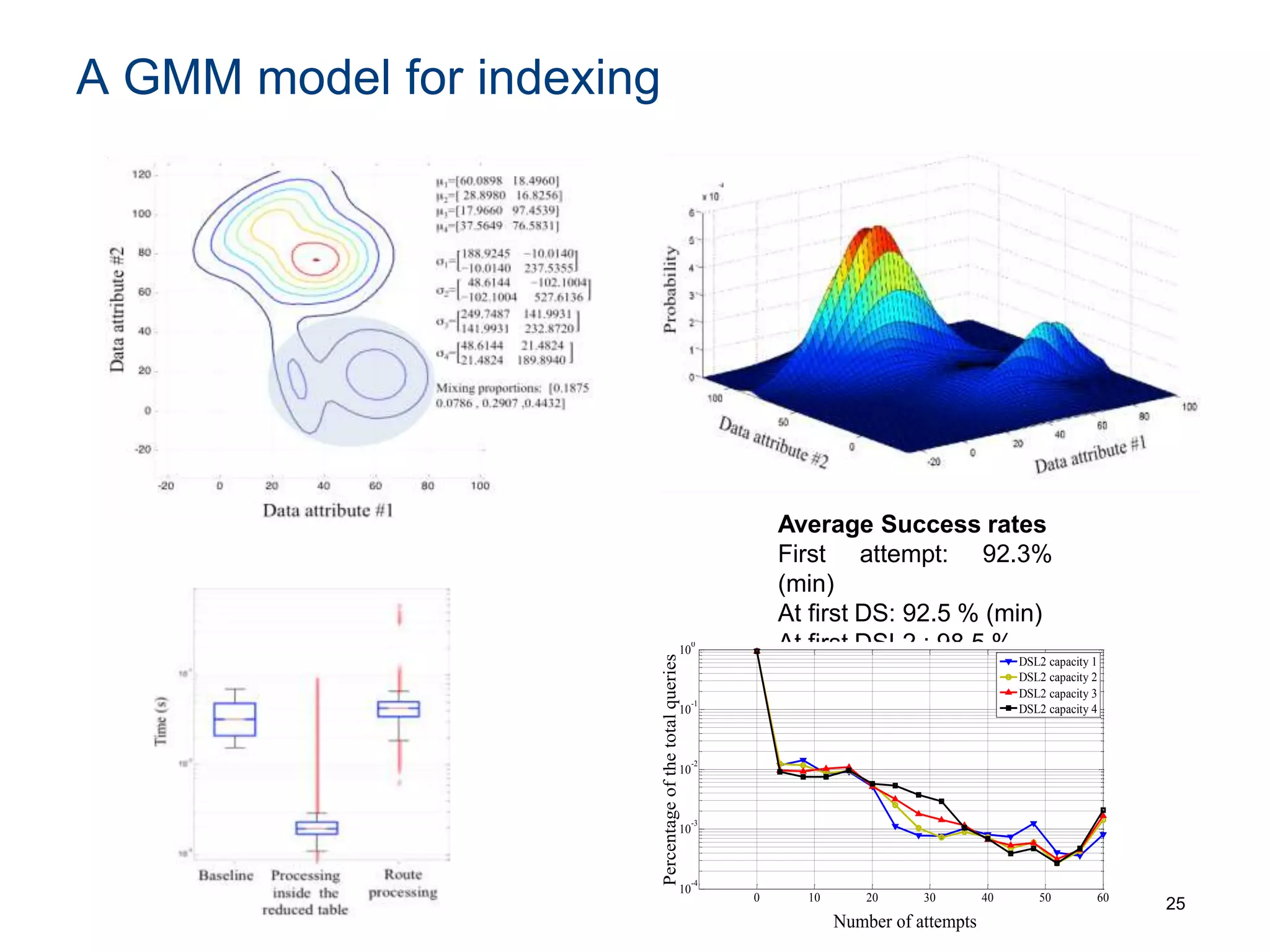
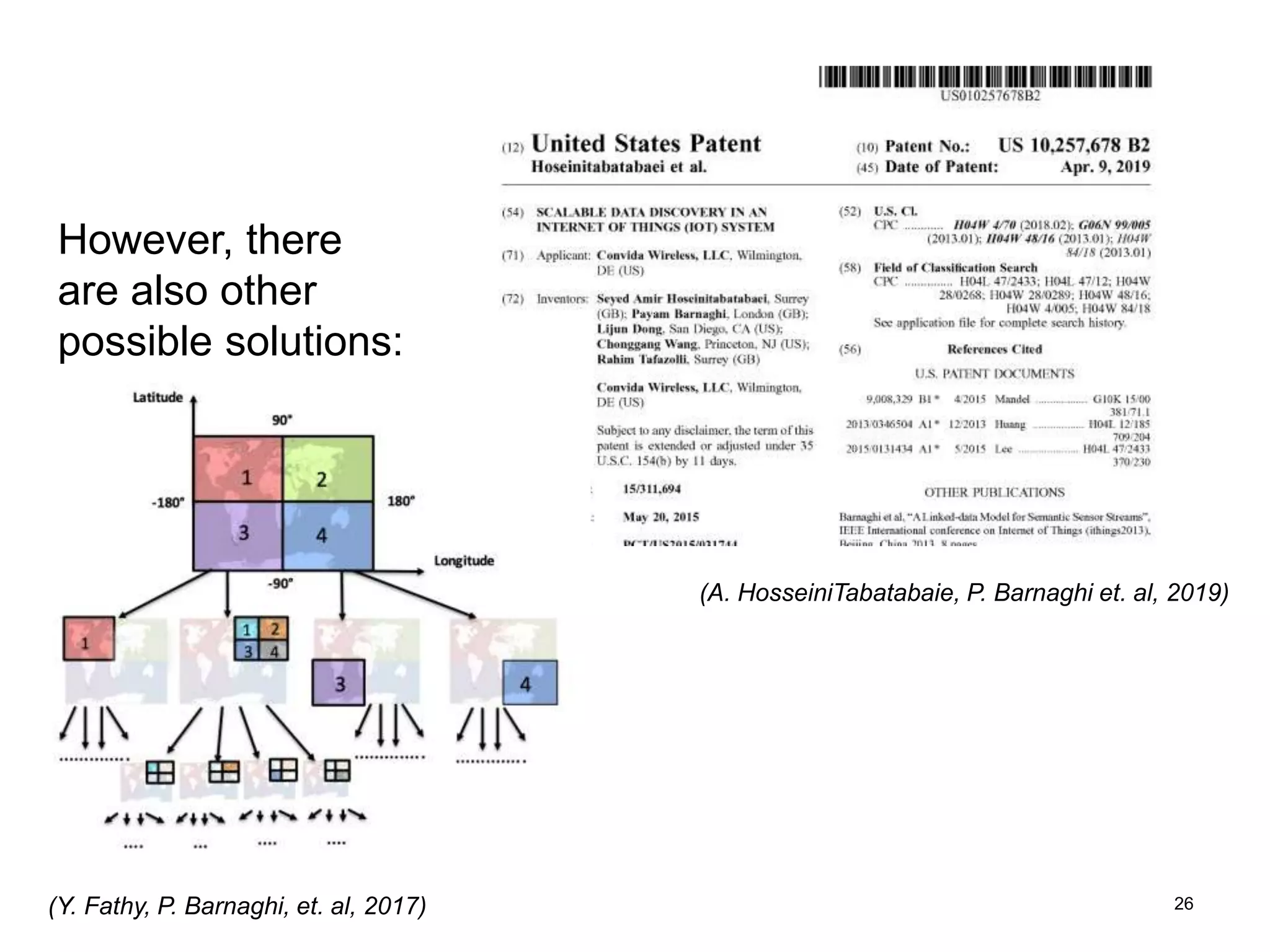





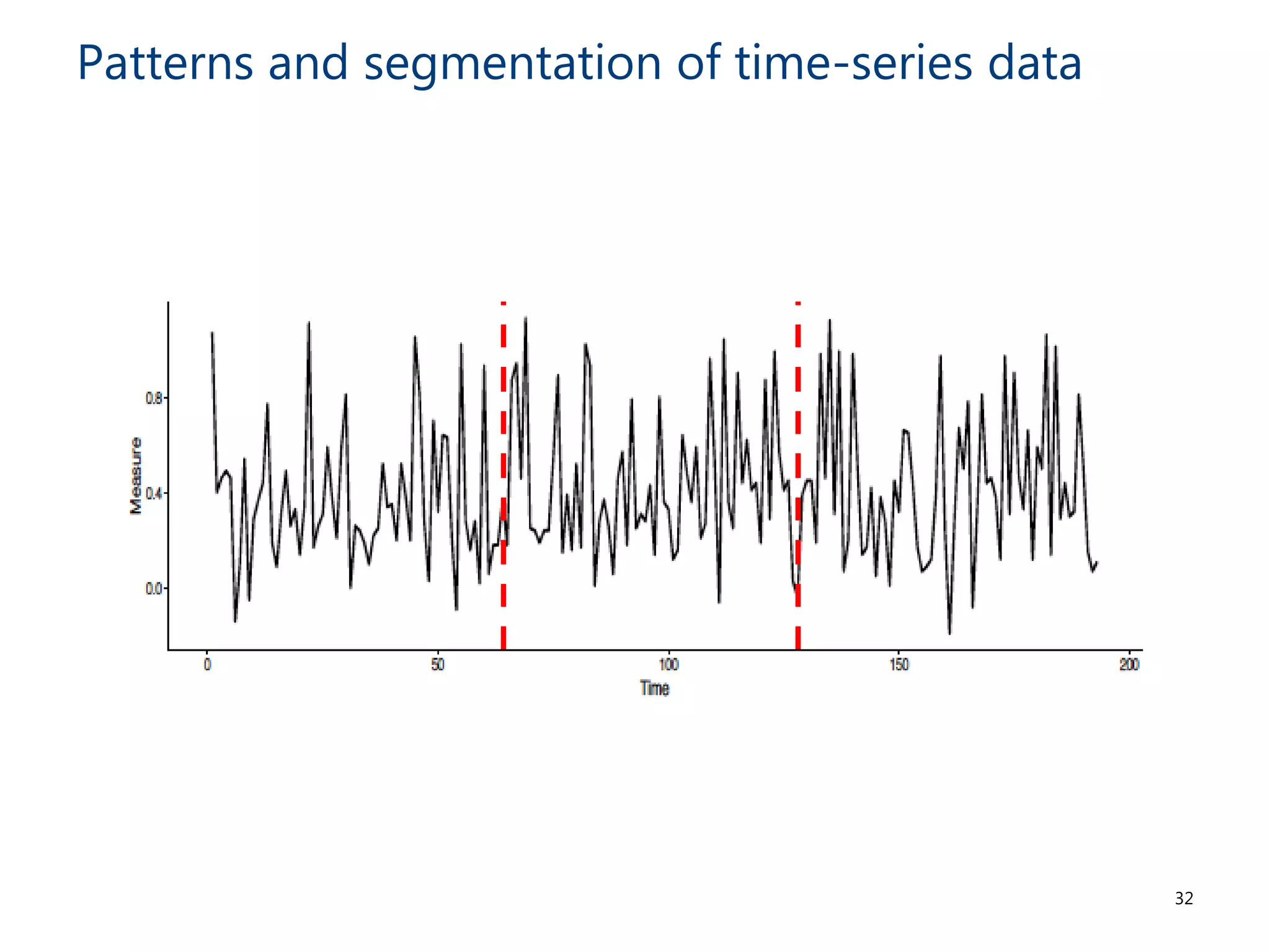
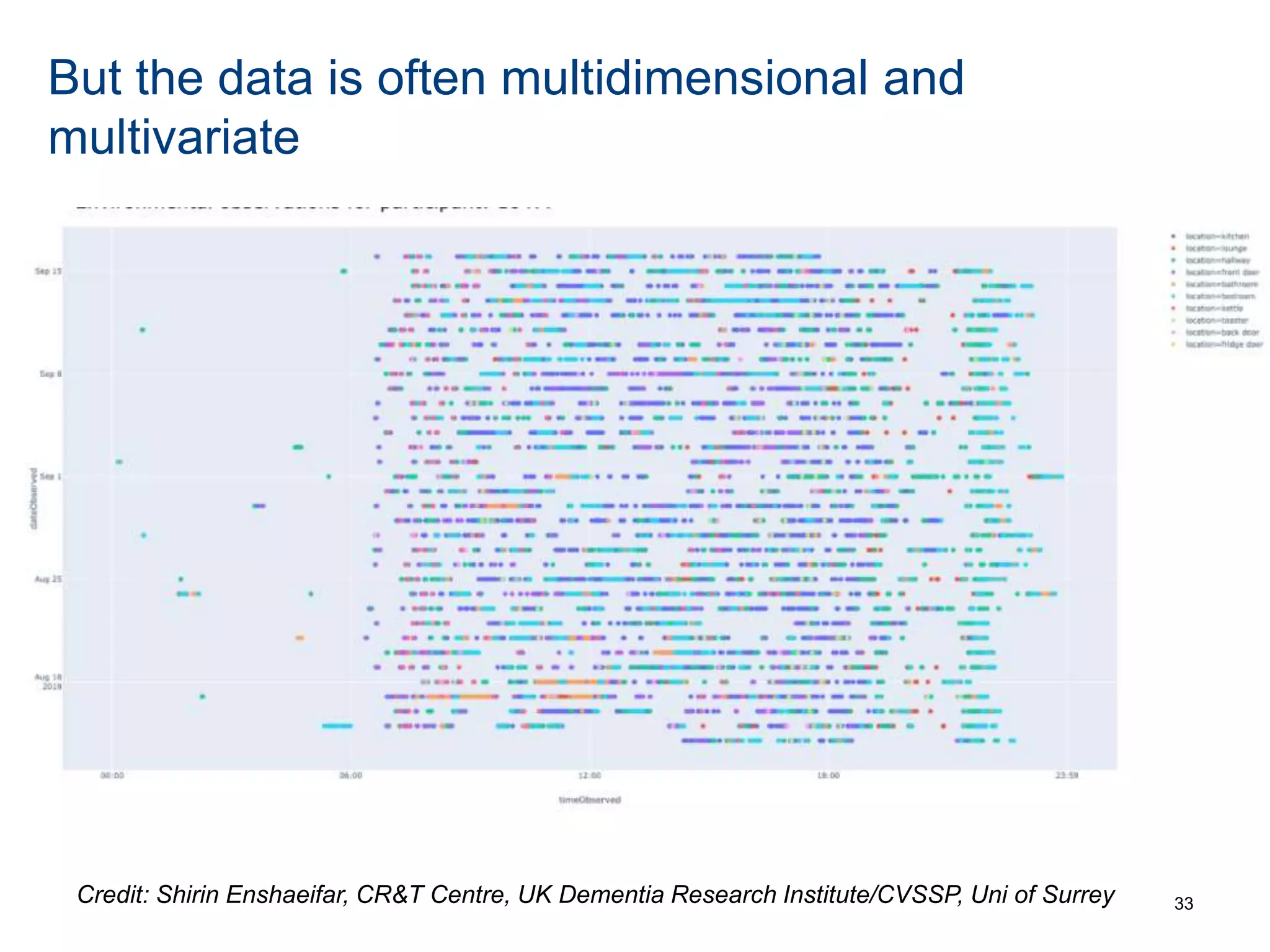
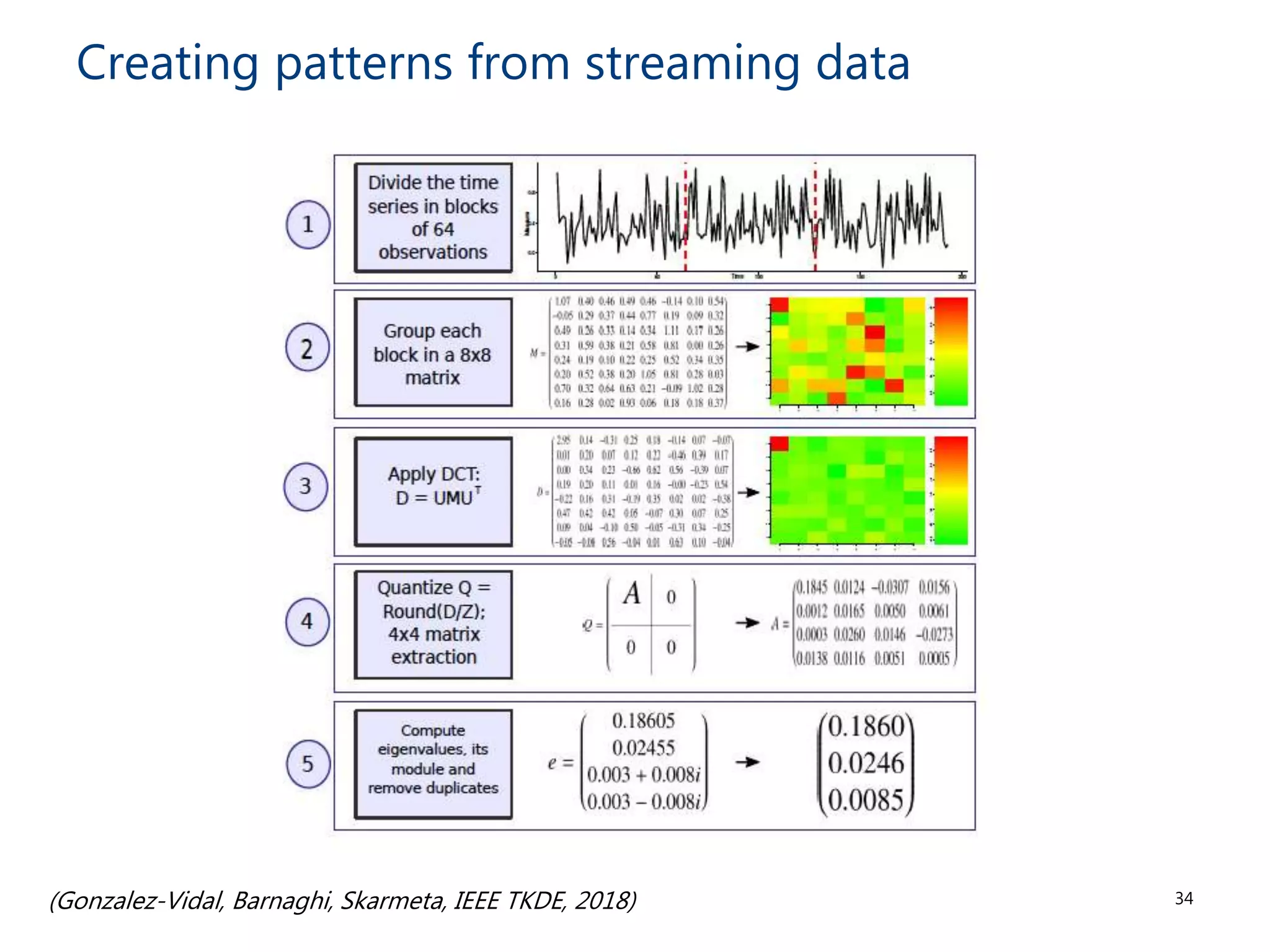
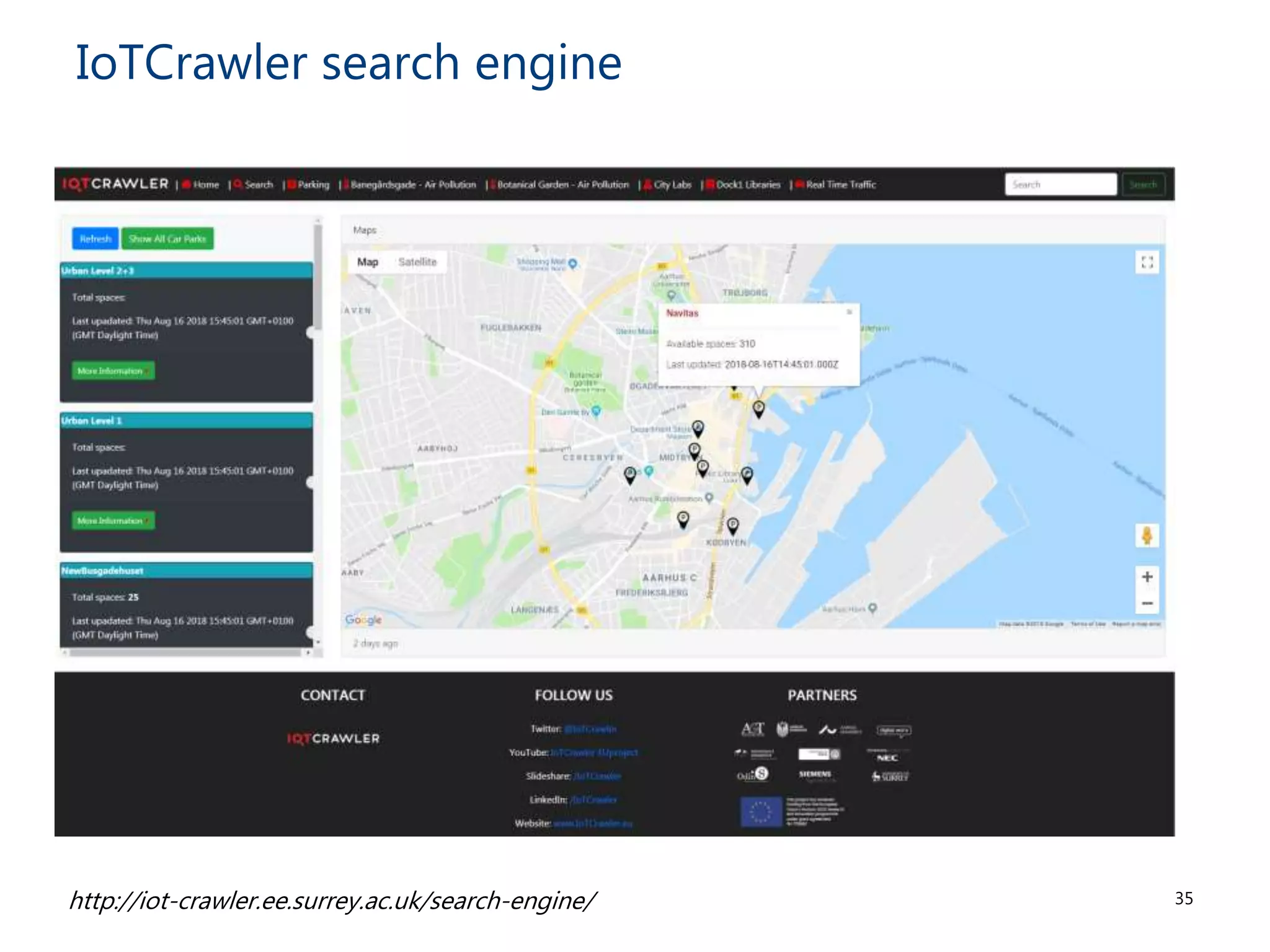
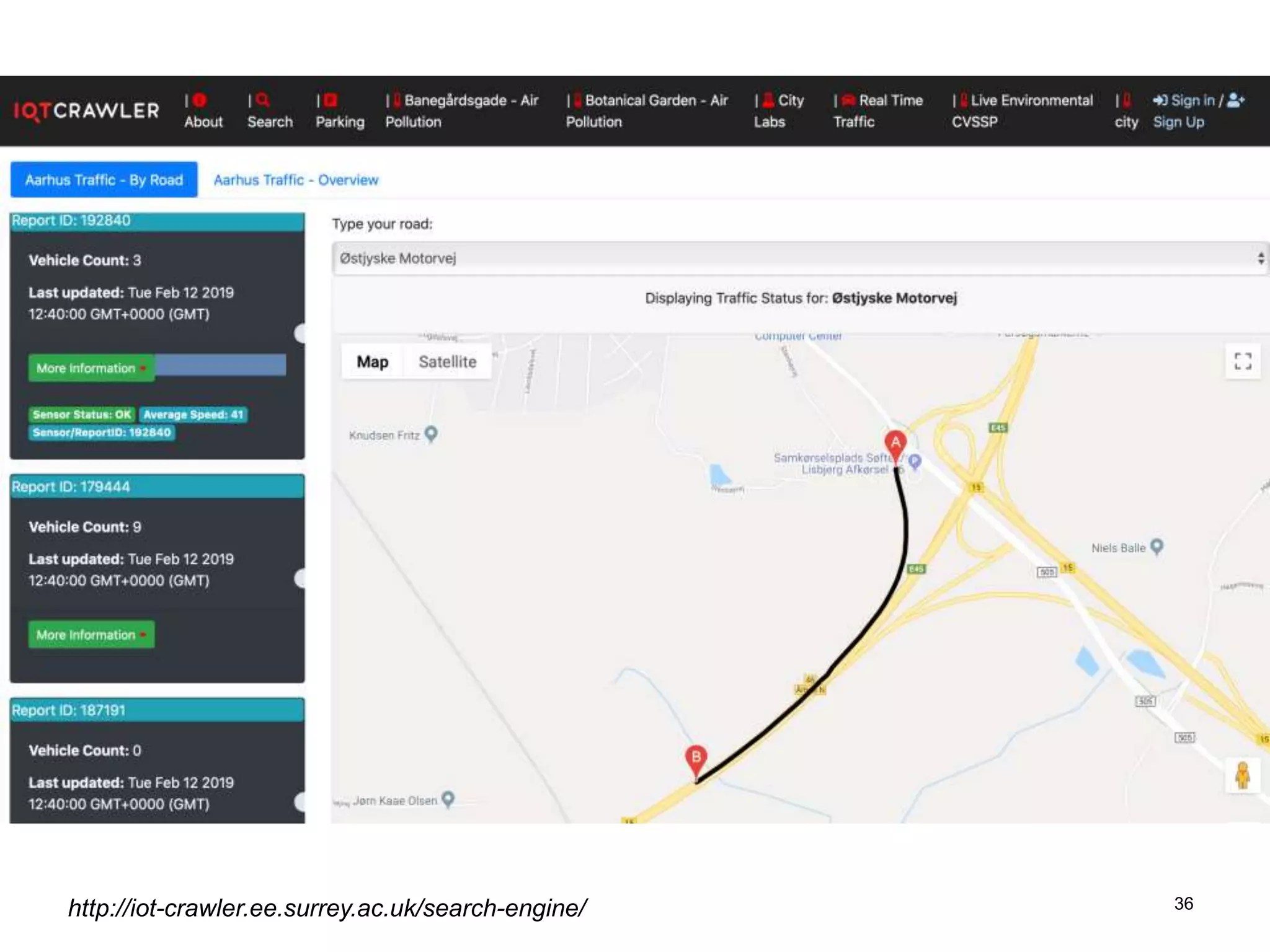
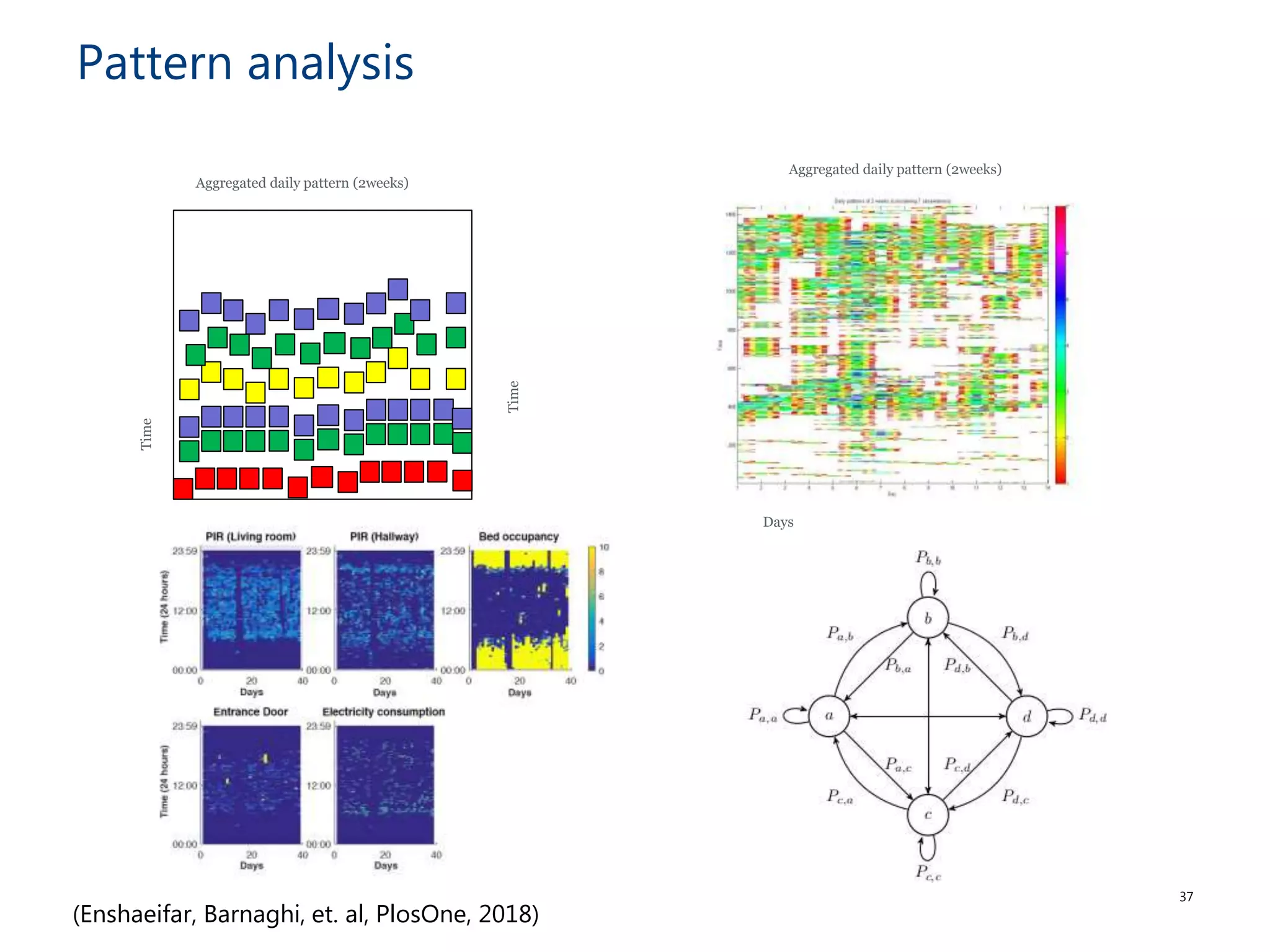
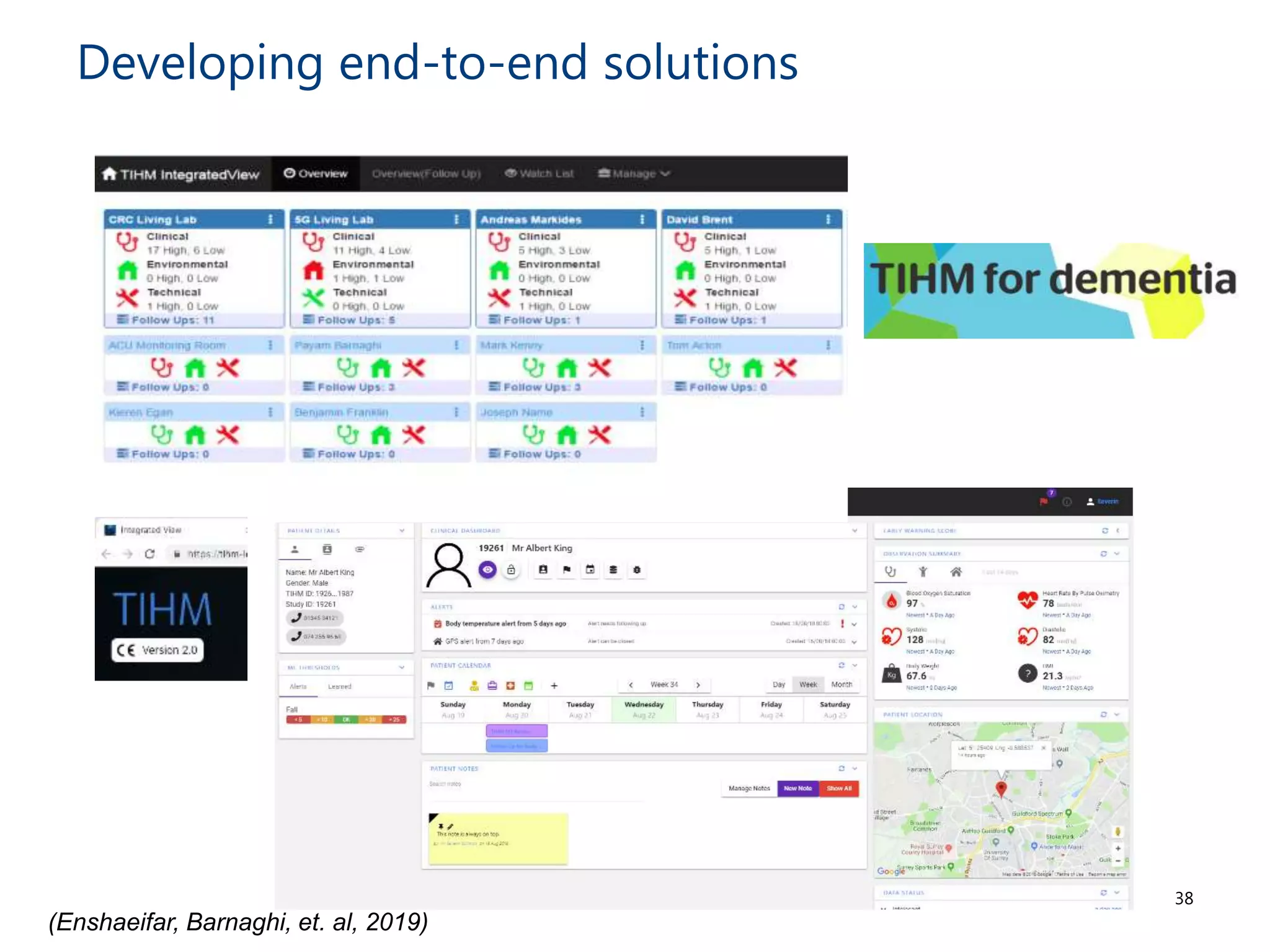


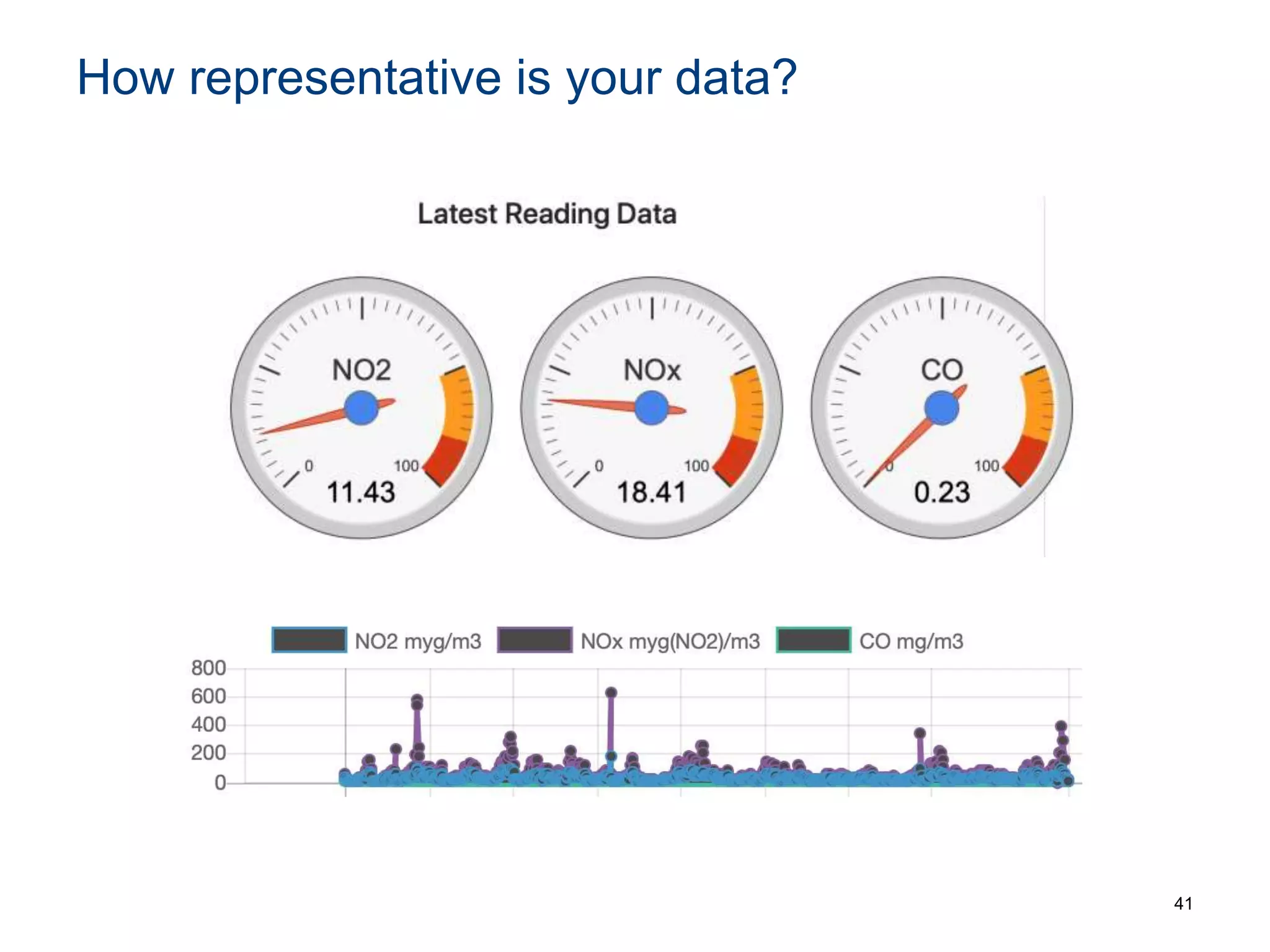

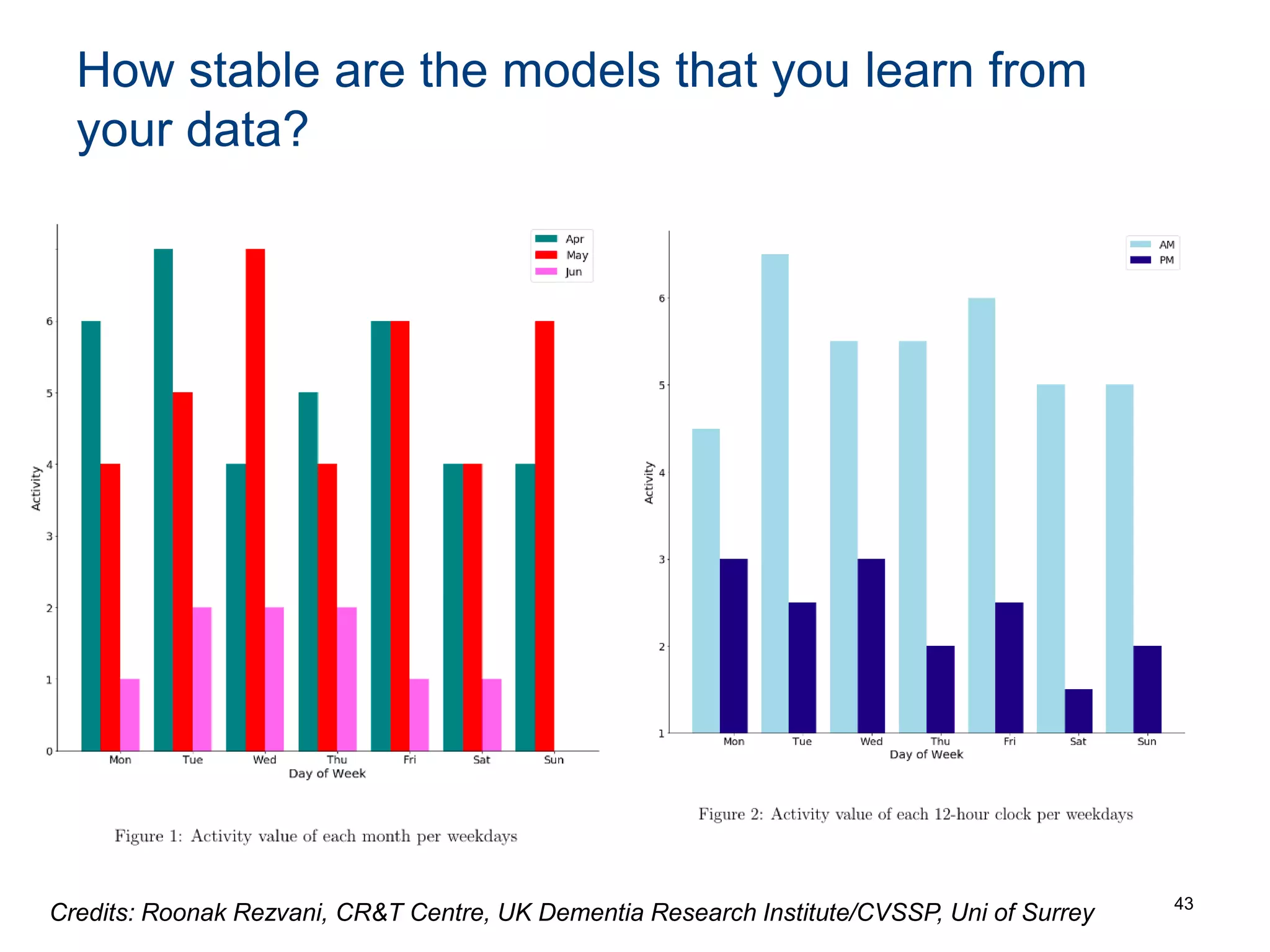
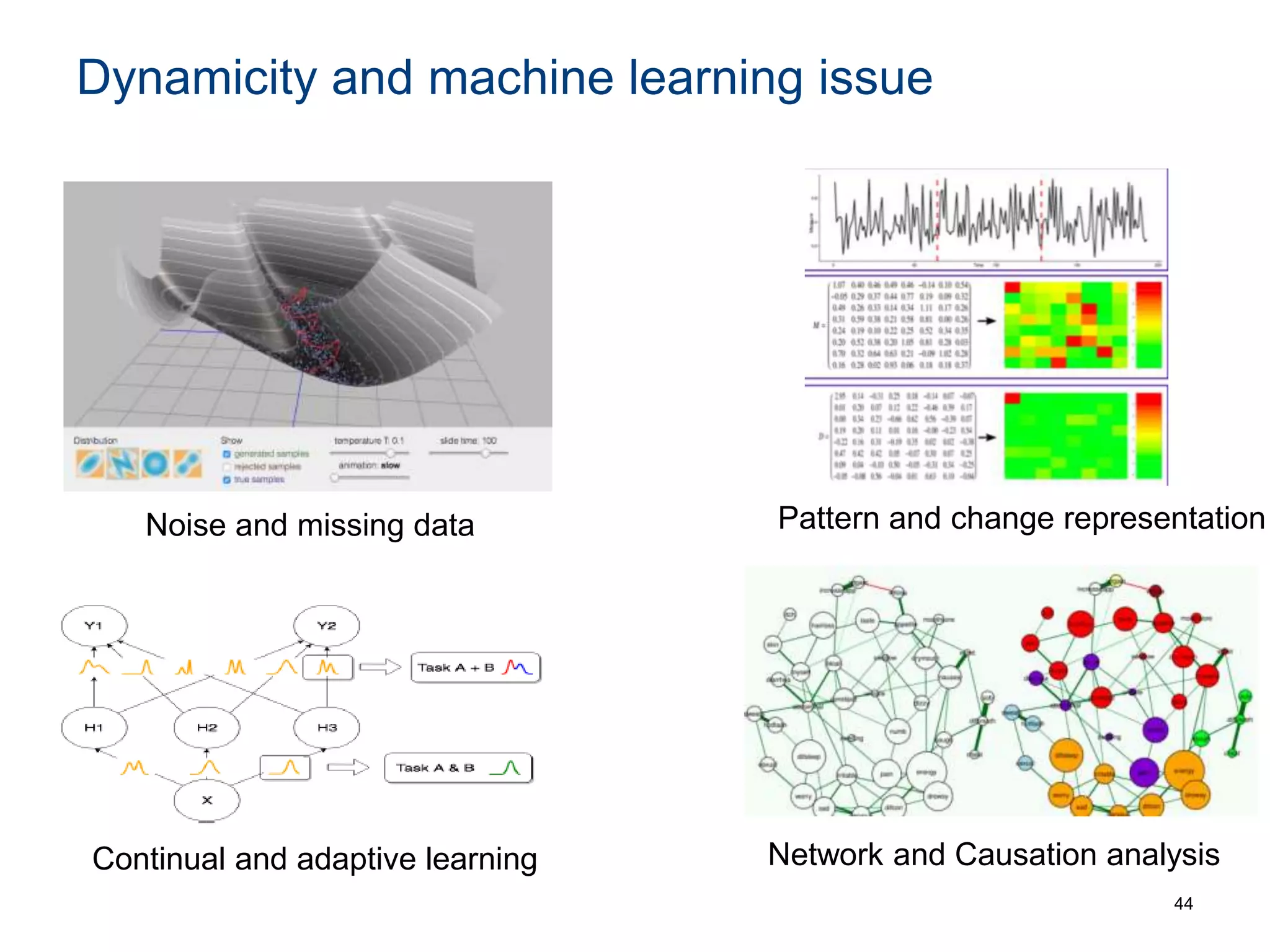






The document discusses the challenges and methodologies involved in searching, discovering, and analyzing sensory data streams from the Internet of Things (IoT). It highlights the evolution of web crawling techniques, specifically addressing issues related to data freshness and optimal crawling policies. The research outlines several key challenges including dealing with dynamic data, ensuring reliability, and developing effective algorithms for pattern recognition and data management.























































































