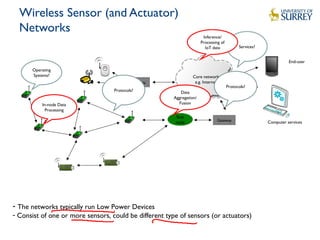
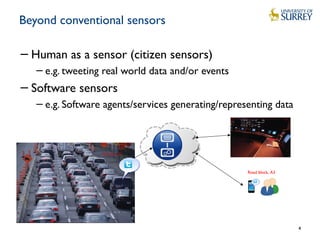
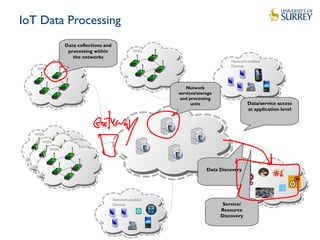
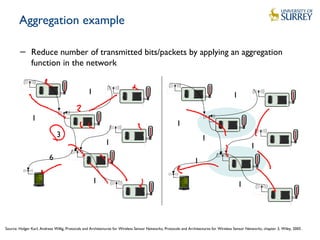
Downloaded 53 times




![6
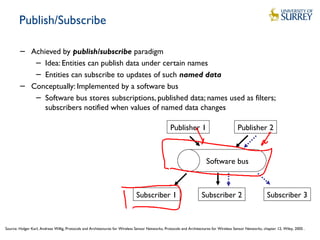
IoT Data Access
− Publish/Subscribe (long-term/short-term)
− Ad-hoc query
− The typical types of data request for sensory data:
− Query based on
− ID (resource/service) – for known resources; eg. data from device ABC001?
− Location e.g. traffic data from junction ABC01
− Type e.g. all the temperature readings
− Time – requests for fresh or historical data; e.g. all the collected data at 9:00am
− One of the above + a range [+ unit of measurement]
− Type/Location/Time + A combination of Quality of Information attributes
− An entity of interest (a feature of an entity on interest)- e.g. temperature of a room;
quality of air in an area;
− Complex DataTypes (e.g. pollution data could be a combination of different types)](https://image.slidesharecdn.com/lecture6dataprocessing-notes-181128143028/85/Lecture-6-IoT-Data-Processing-6-320.jpg)































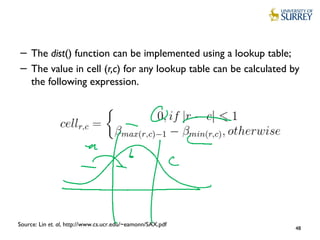

![Distance function – Sample MATLAB code
50
% source: J. Lin et. al, https://cs.gmu.edu/~jessica/sax.htm
function dist_matrix = build_dist_table(alphabet_size)
switch alphabet_size
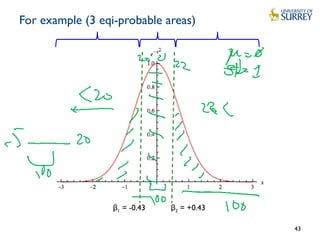
case 2, cutlines = [0];
case 3, cutlines = [-0.43 0.43];
case 4, cutlines = [-0.67 0 0.67];
case 5, cutlines = [-0.84 -0.25 0.25 0.84];
case 6, cutlines = [-0.97 -0.43 0 0.43 0.97];
case 7, cutlines = [-1.07 -0.57 -0.18 0.18 0.57 1.07];
case 8, cutlines = [-1.15 -0.67 -0.32 0 0.32 0.67 1.15];
case 9, cutlines = [-1.22 -0.76 -0.43 -0.14 0.14 0.43 0.76 1.22];
case 10, cutlines = [-1.28 -0.84 -0.52 -0.25 0. 0.25 0.52 0.84 1.28];
otherwise, disp('WARNING:: Alphabet size too big');
end;
dist_matrix=zeros(alphabet_size,alphabet_size);
for i = 1 : alphabet_size
% the min_dist for adjacent symbols are 0, so we start with i+2
for j = i+2 : alphabet_size
% square the distance now for future use
dist_matrix(i,j)=(cutlines(i)-cutlines(j-1))^2;
% the distance matrix is symmetric
dist_matrix(j,i) = dist_matrix(i,j);
end;
end;](https://image.slidesharecdn.com/lecture6dataprocessing-notes-181128143028/85/Lecture-6-IoT-Data-Processing-50-320.jpg)

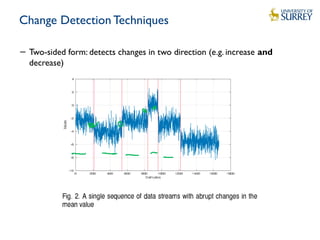
![Change Detection Techniques
− A key technique is Page’s Cumulative Sum (CUSUM) [1] [2]
− Cumulative differences between successive values.
− One-sided form: detects changes in one direction (e.g. increase or
decrease)
[1] Page, E. S. (1954). Continuous inspection schemes. Biometrika, 41(1/2), 100-115.
[2] Granjon, P. (2013).The CuSum algorithm-a small review.](https://image.slidesharecdn.com/lecture6dataprocessing-notes-181128143028/85/Lecture-6-IoT-Data-Processing-53-320.jpg)






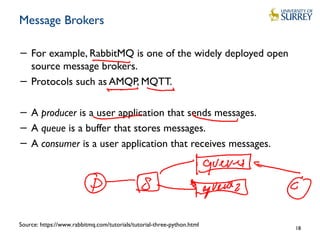
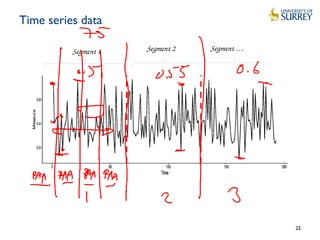
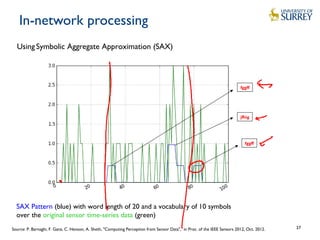
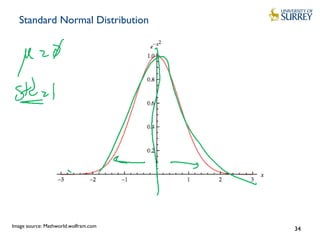
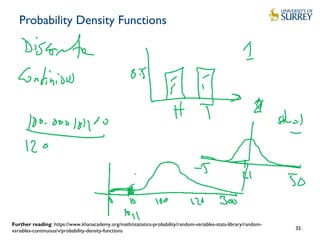
This document discusses IoT data processing. It begins by describing wireless sensor networks and key characteristics of IoT devices. It then discusses topics like in-network processing using techniques like data aggregation and Symbolic Aggregate Approximation (SAX). Publish/subscribe protocols like MQTT are also covered. The document emphasizes the need for efficient and scalable solutions to process the large volumes of data generated by IoT devices with limited resources.




![[PPT] _ Unit 2 _ Complete PPT.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/pptunit2completeppt-220516115836-332a1107-thumbnail.jpg?width=640&height=640&fit=bounds)


















































































