Download as PDF, PPTX


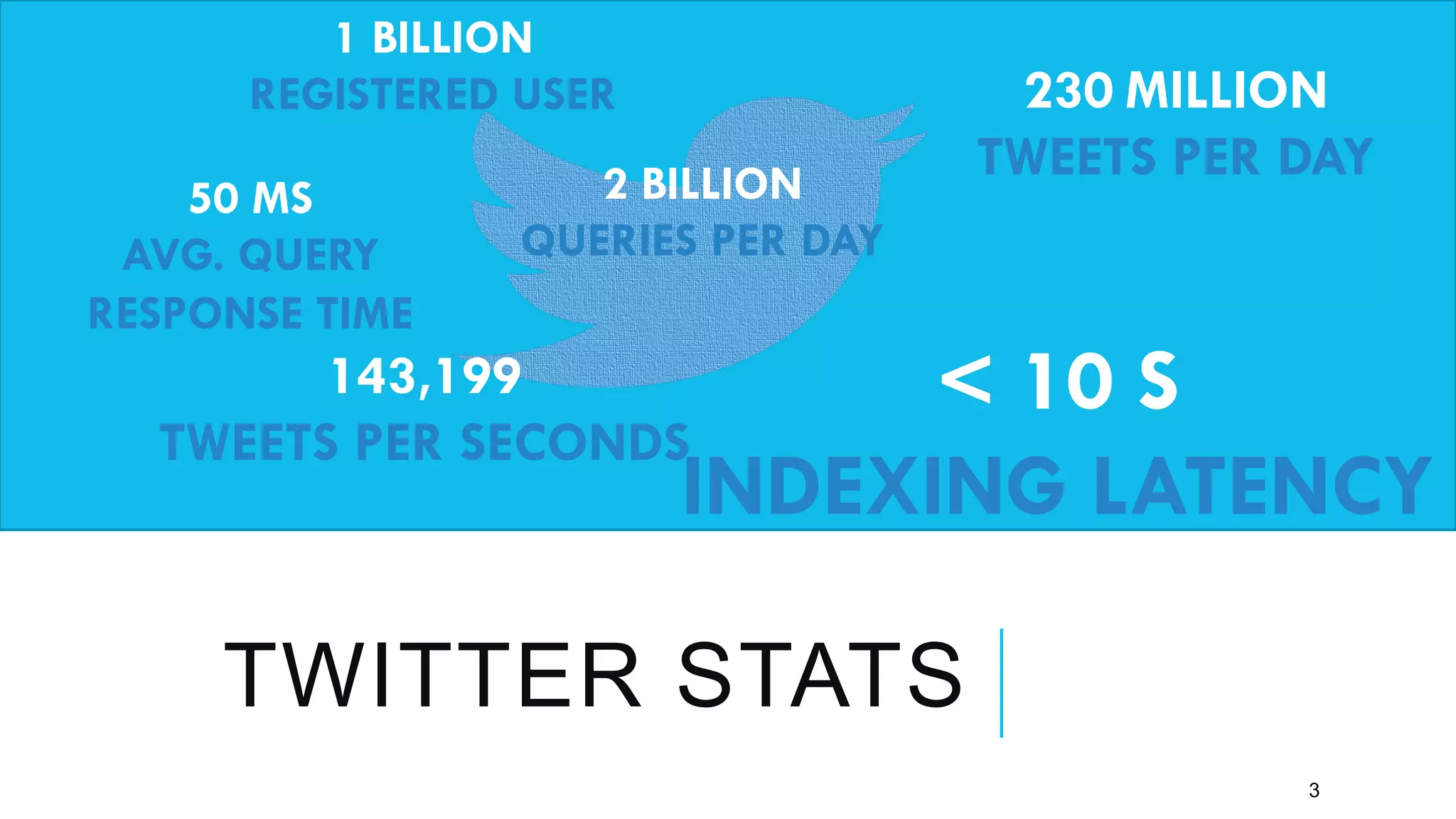


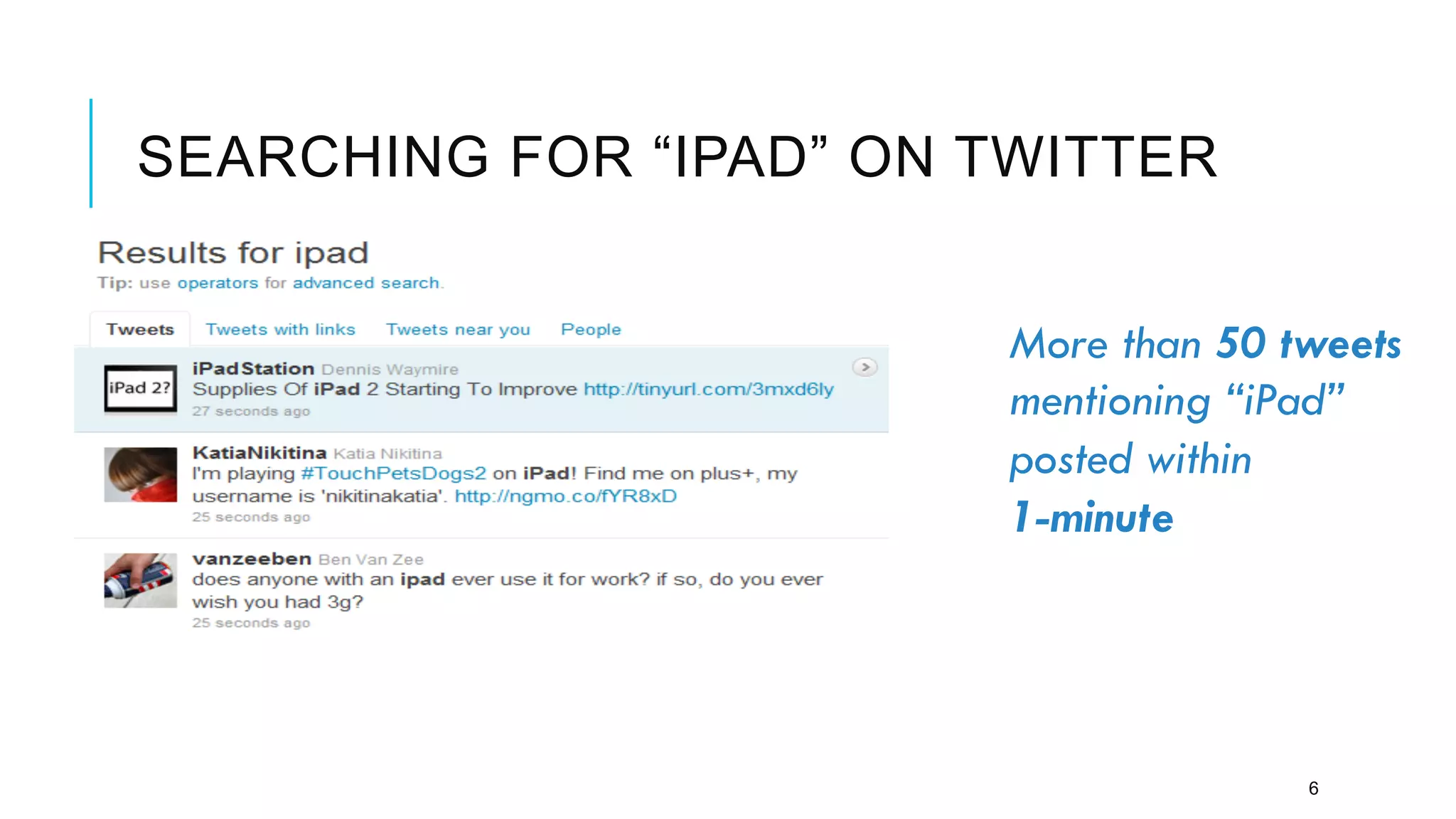

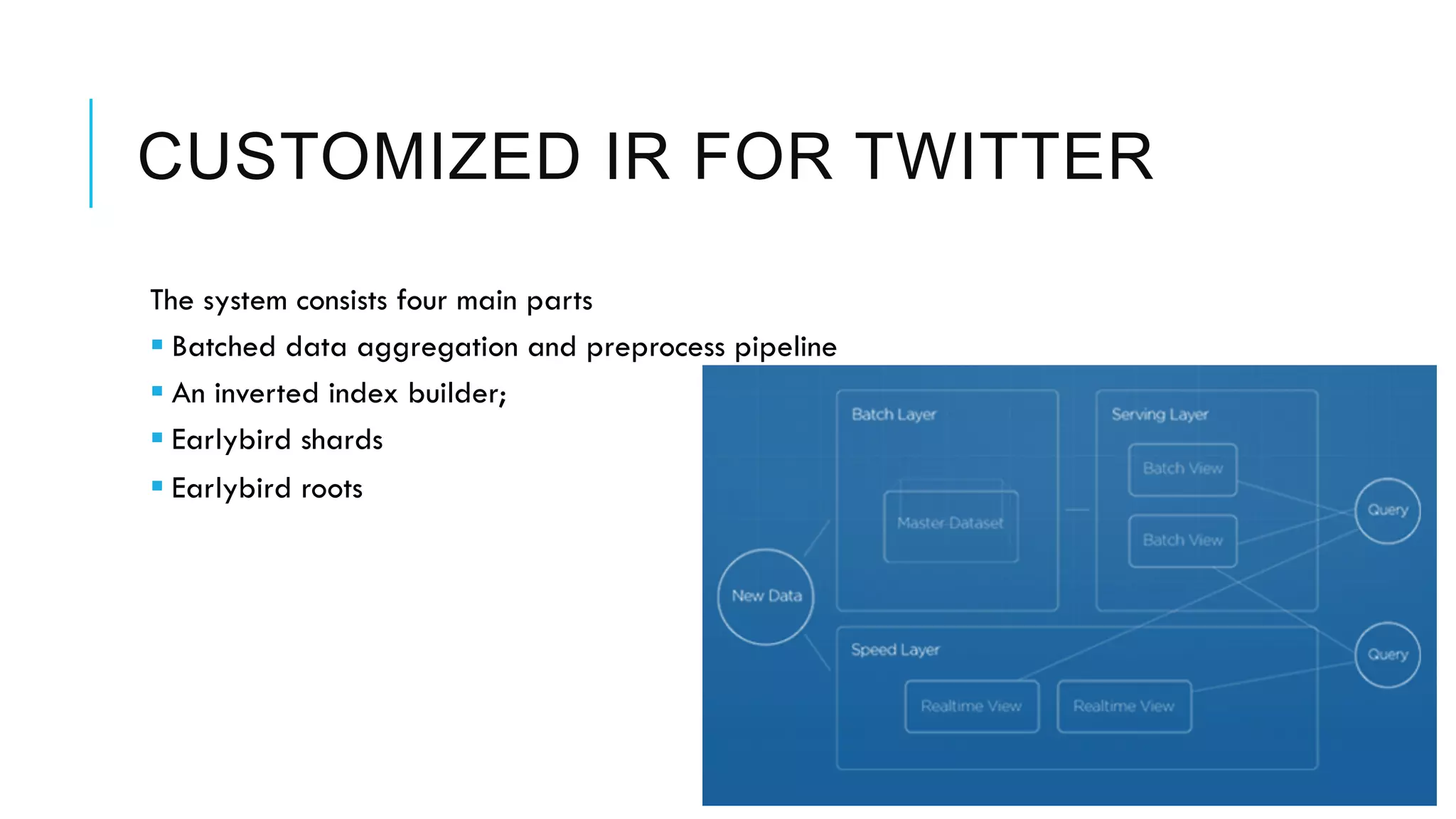



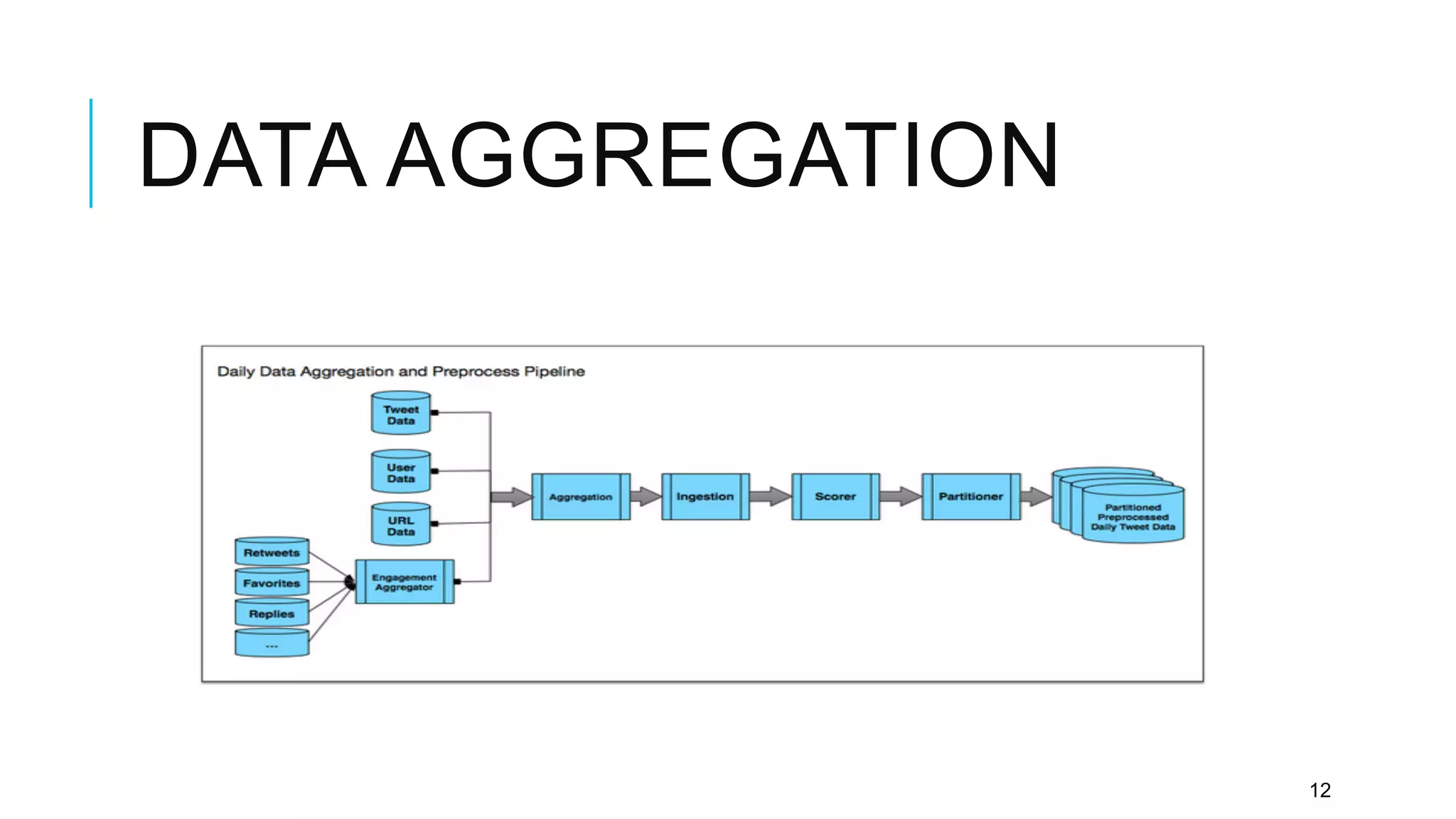

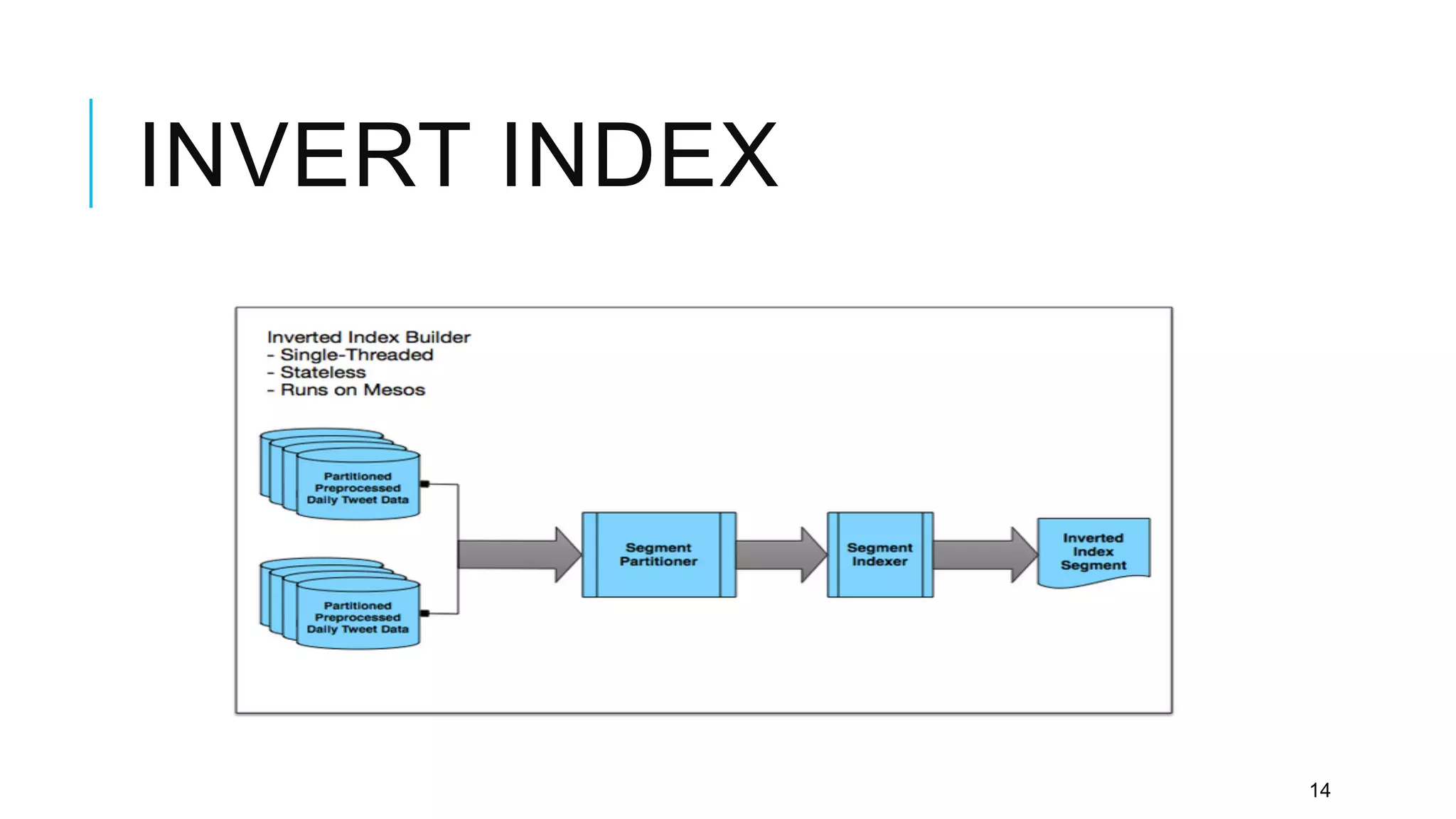

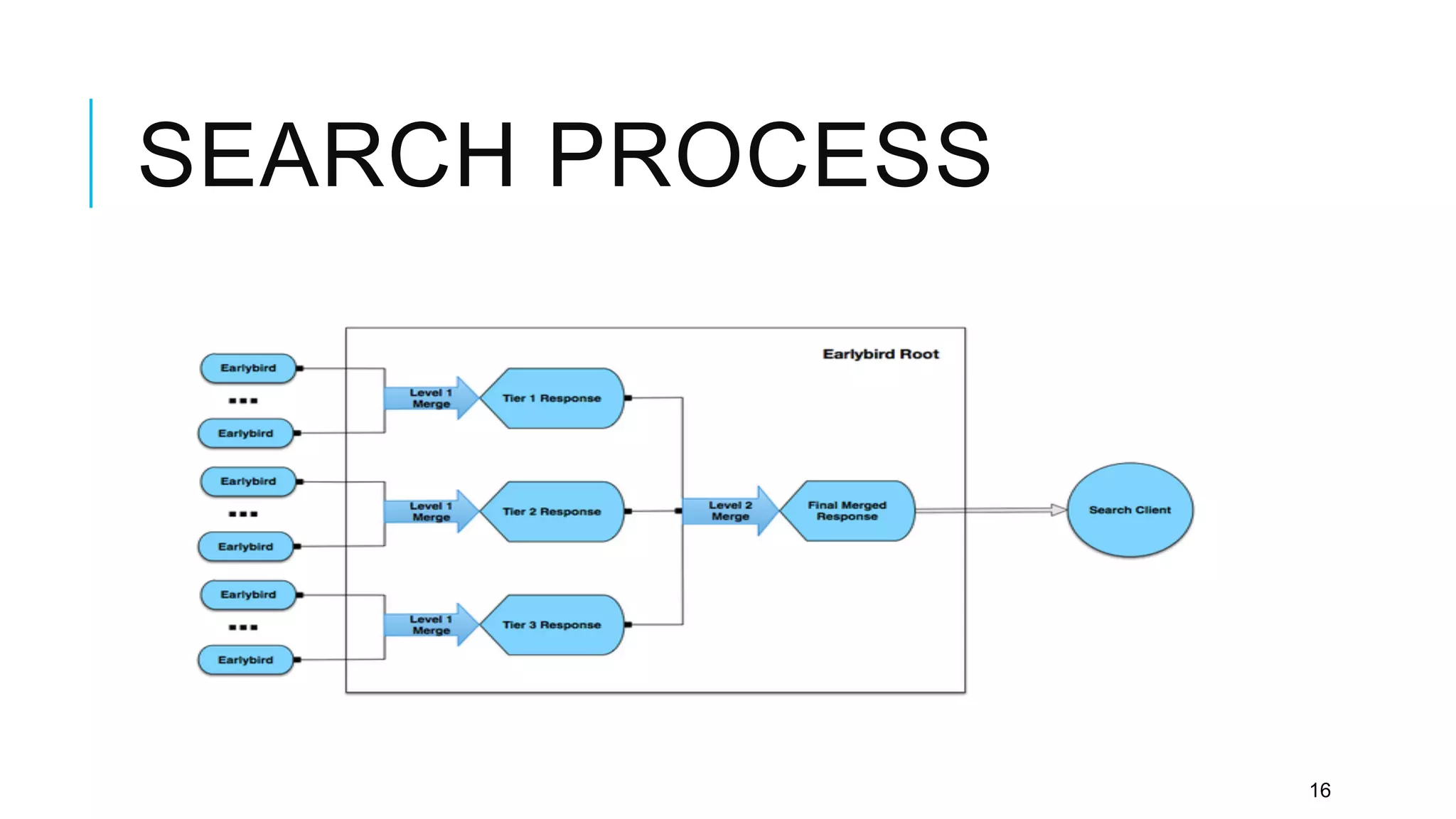
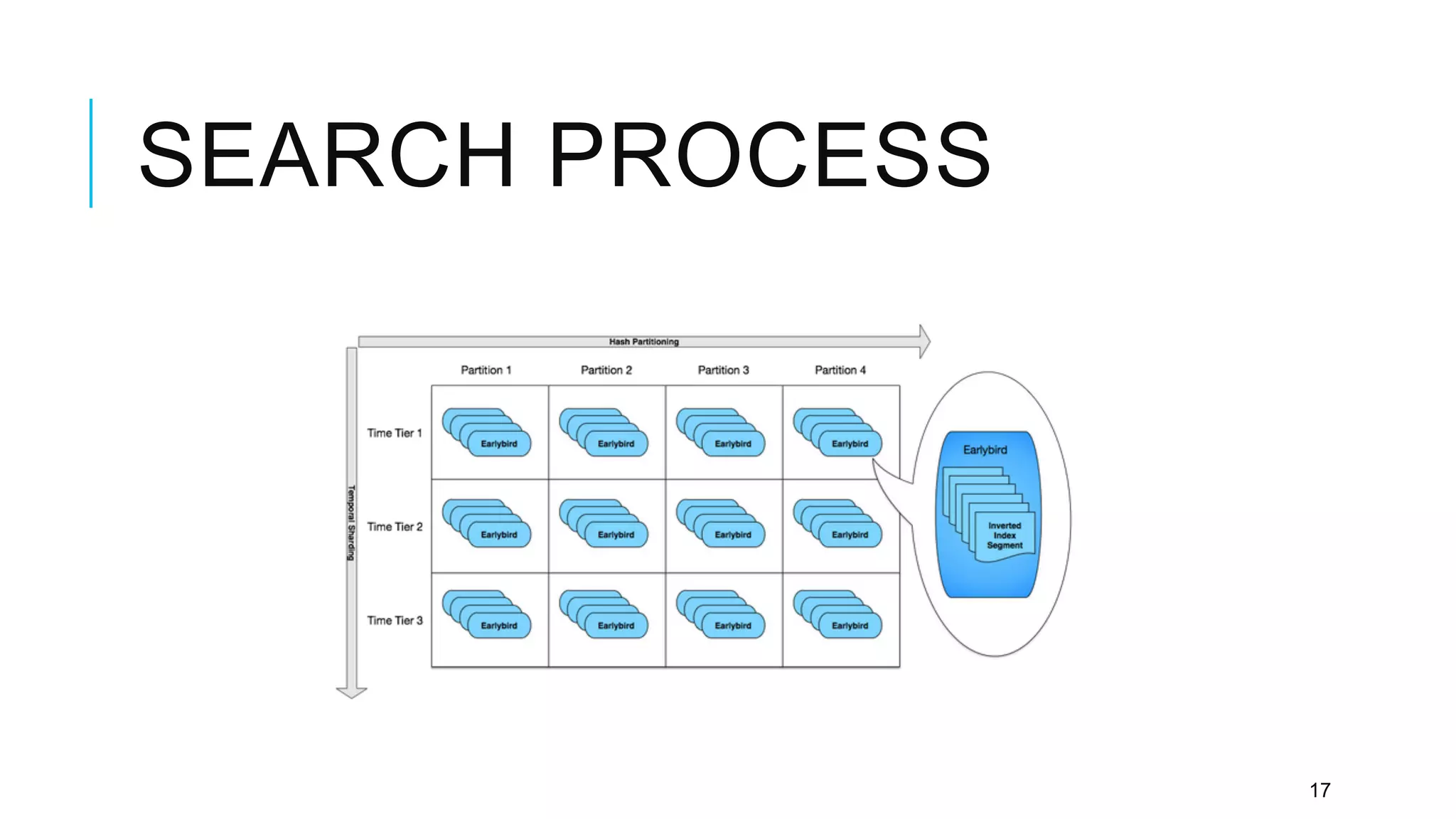

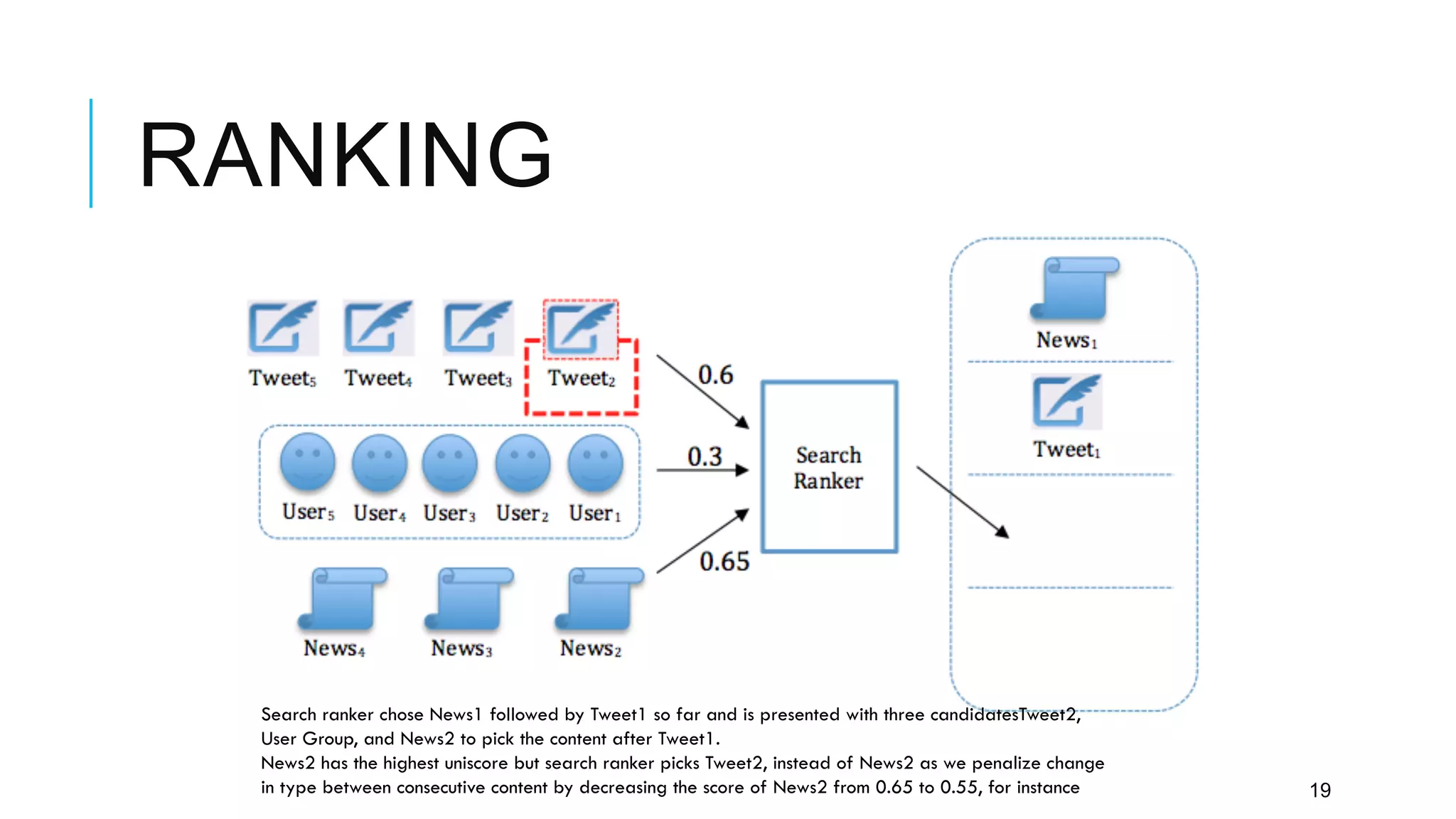
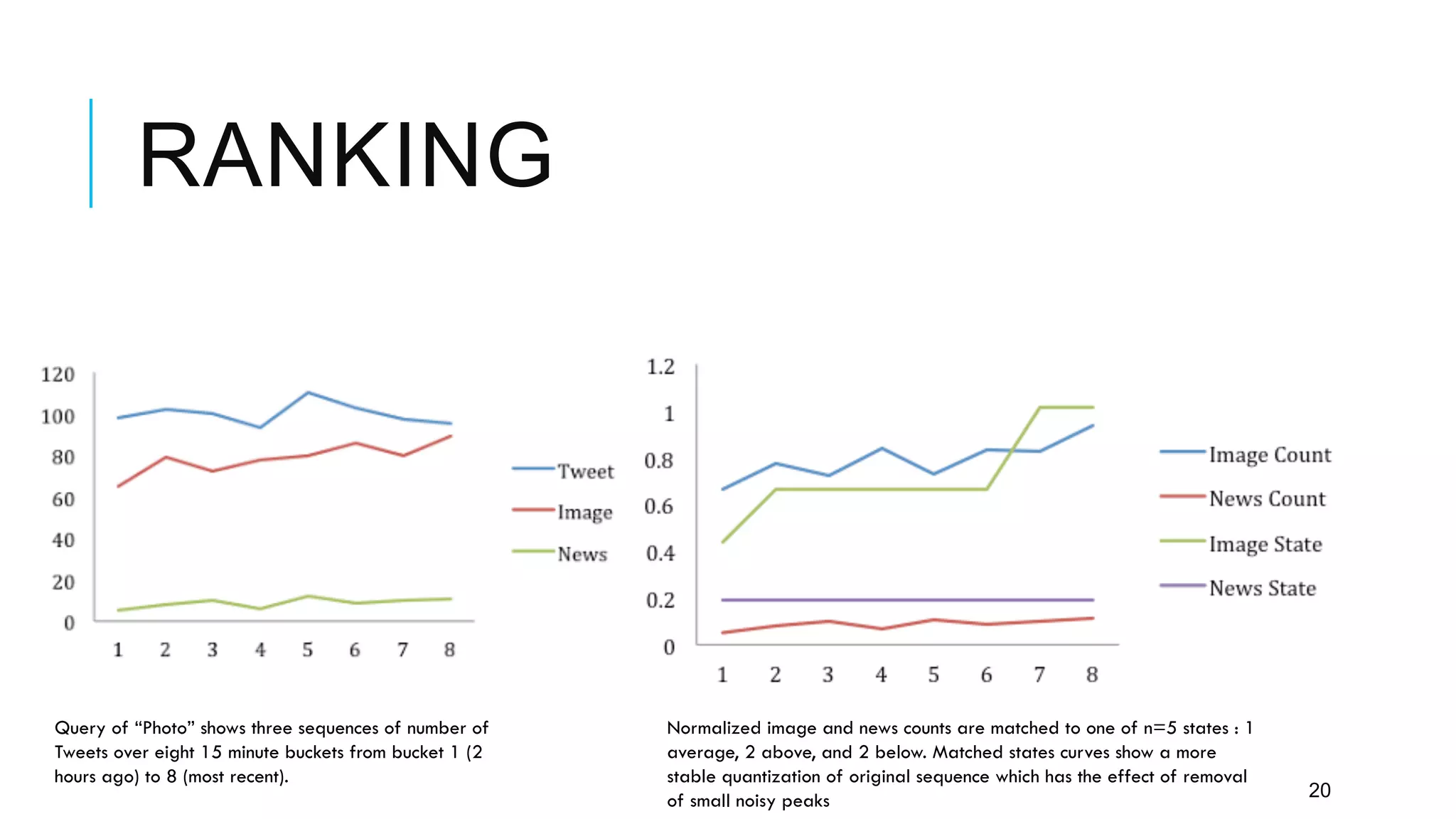



Twitter provides a platform for user-generated content in the form of short messages called tweets. It handles a massive volume of data, with over 230 million tweets and 2 billion search queries per day. Twitter has developed a customized search and indexing system to handle this scale. It uses a modular system that is scalable, cost-effective, and allows for incremental development. The system includes components for crawling Twitter data, preprocessing and aggregating tweets, building an inverted index, and distributing the index across server machines for low-latency search.















































![DirtyTooth: It´s only Rock'n Roll but I like it [Slides]](https://cdn.slidesharecdn.com/ss_thumbnails/dirtytoothslides-170309122009-thumbnail.jpg?width=640&height=640&fit=bounds)

















![Social media crawling and mining [exercises]](https://cdn.slidesharecdn.com/ss_thumbnails/socialmediacrawlingandminingexercises-140509030113-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)














![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)







