Download as PDF, PPTX



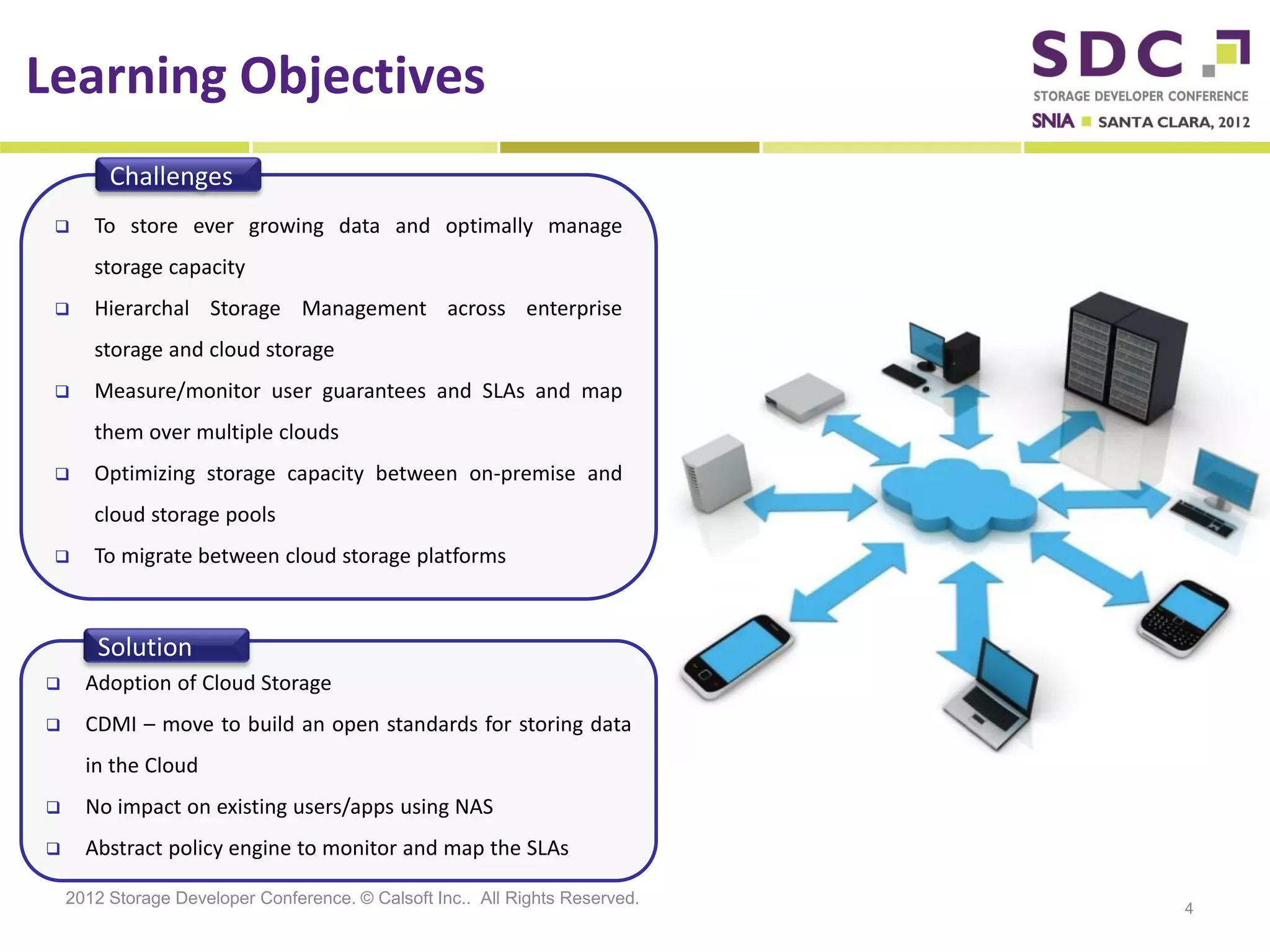
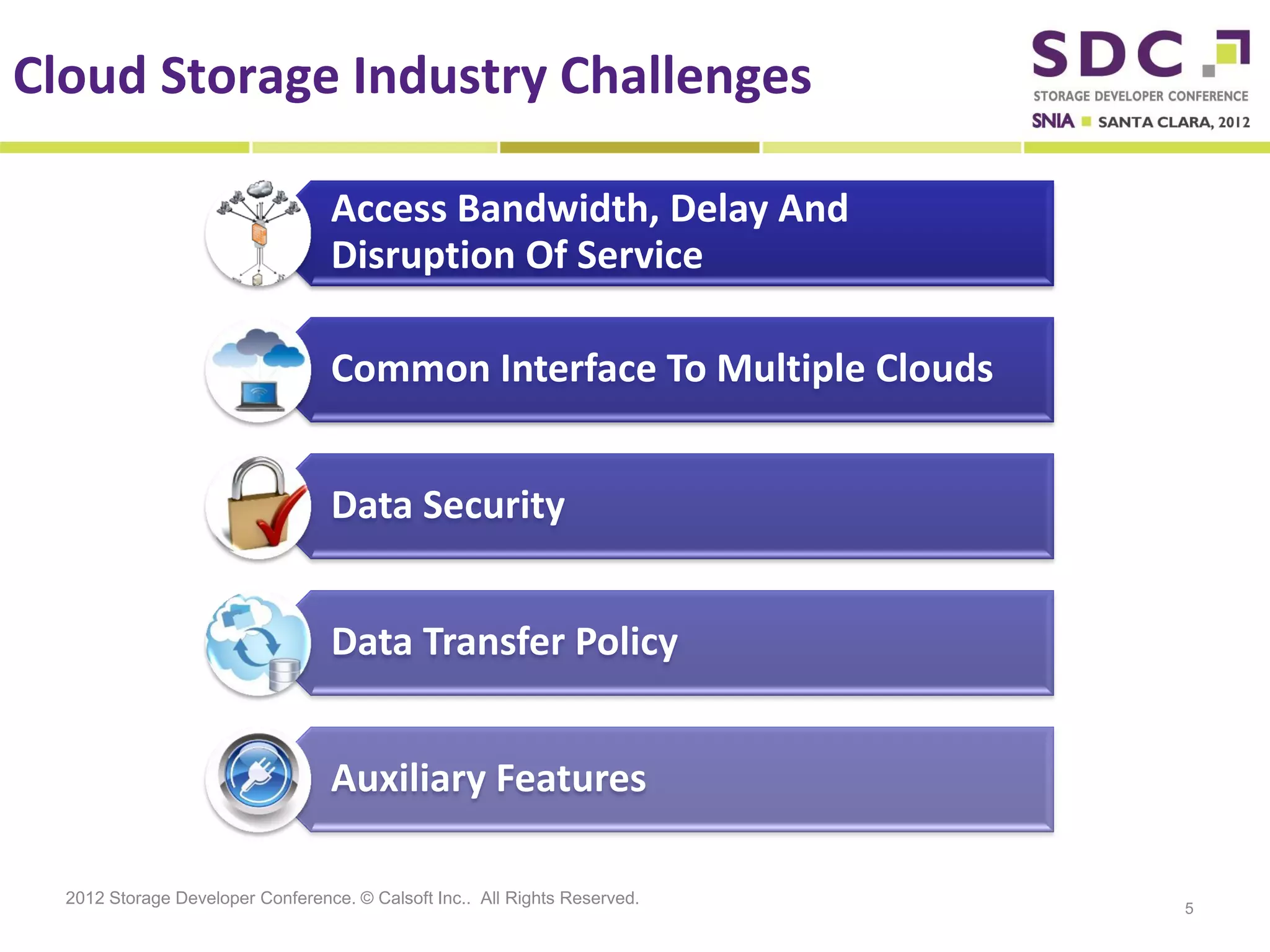
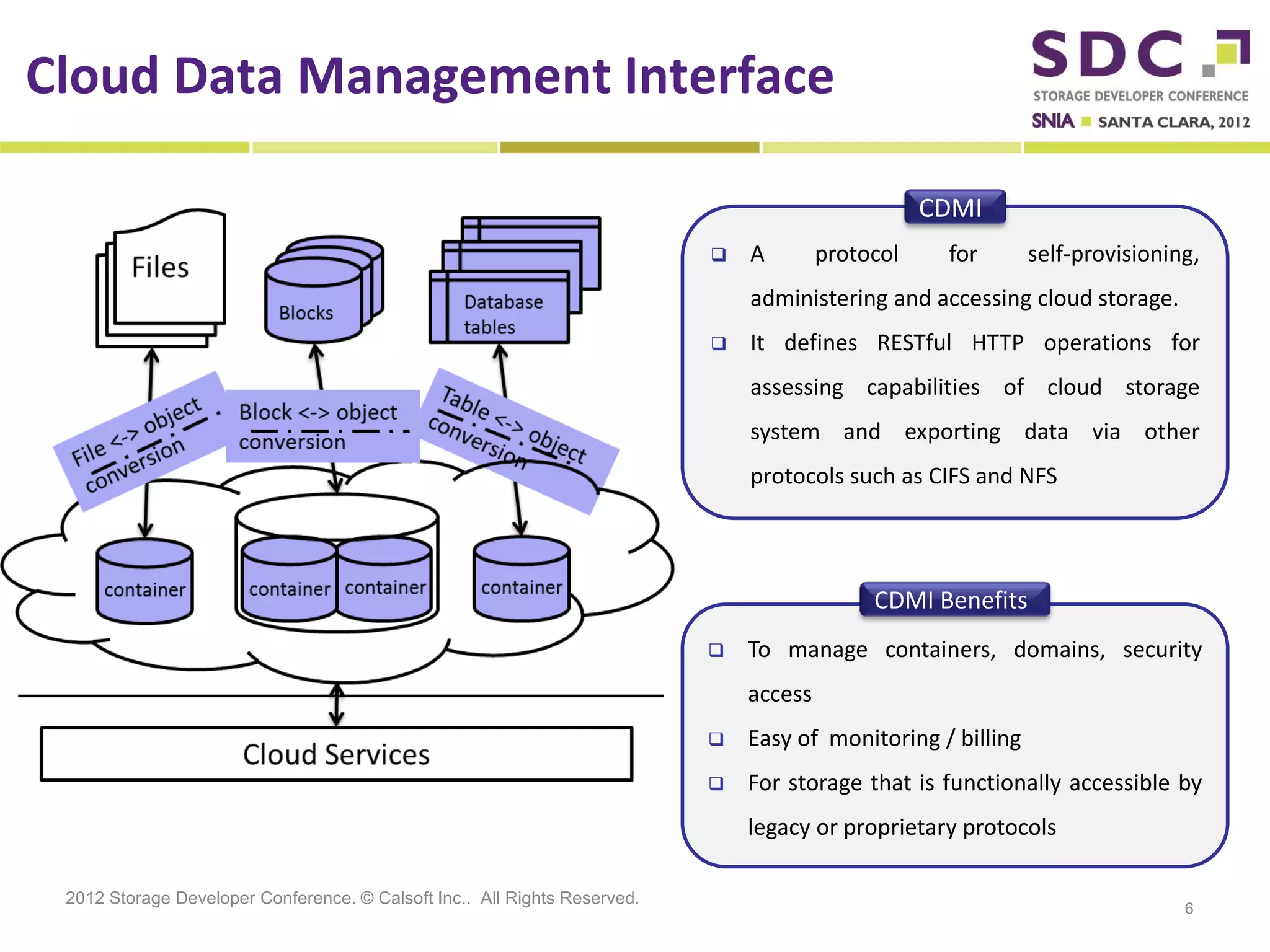
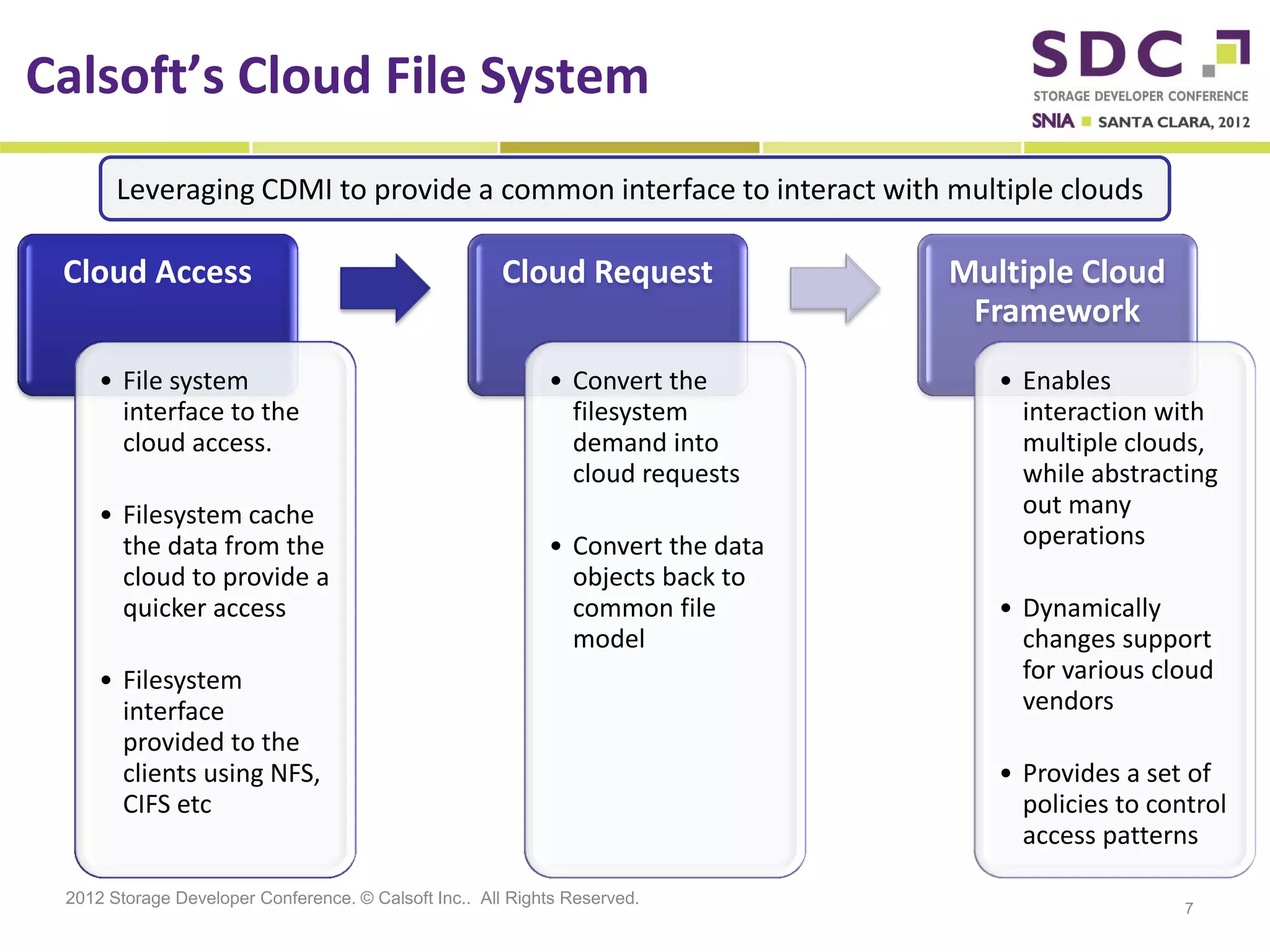
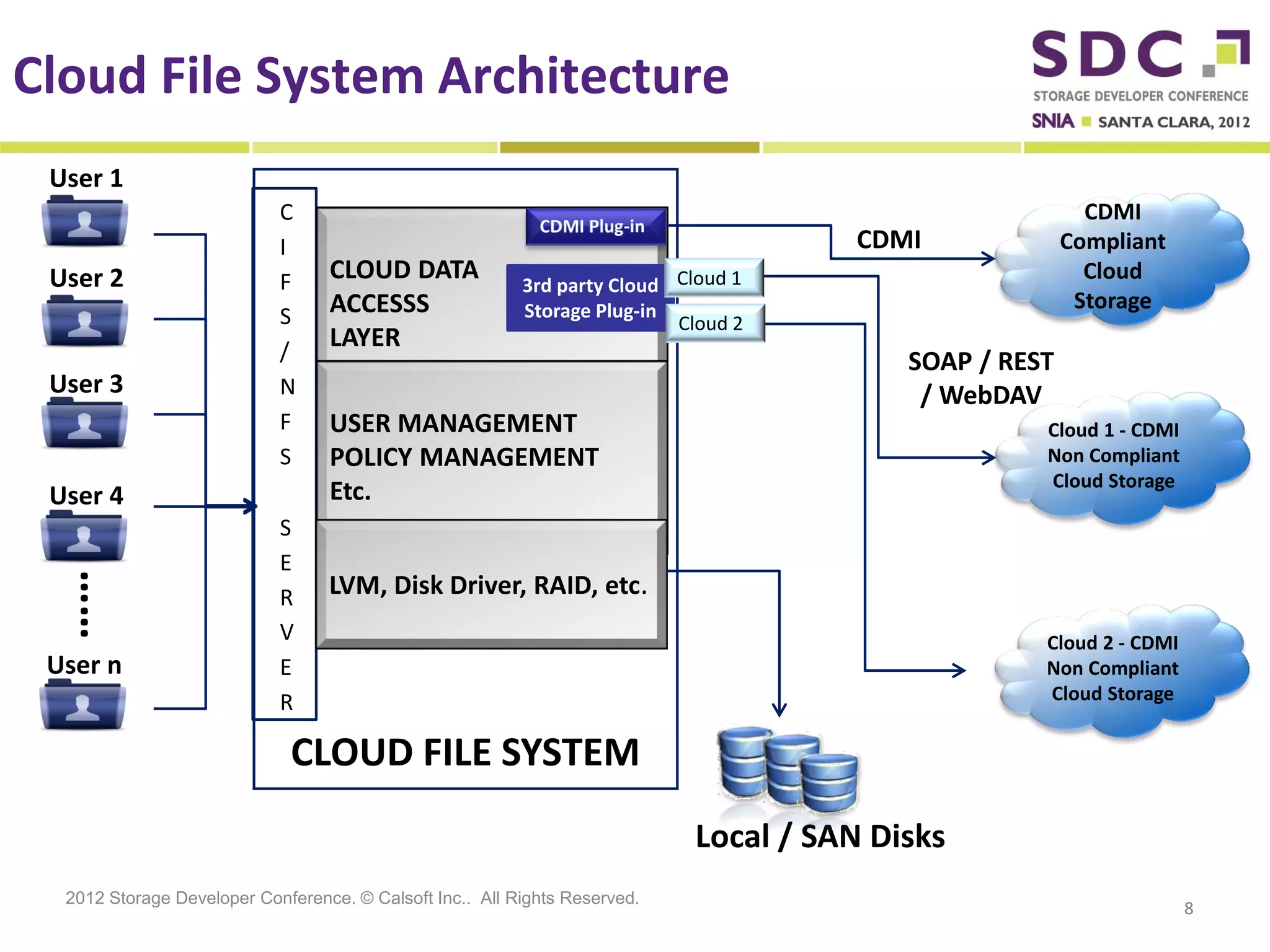
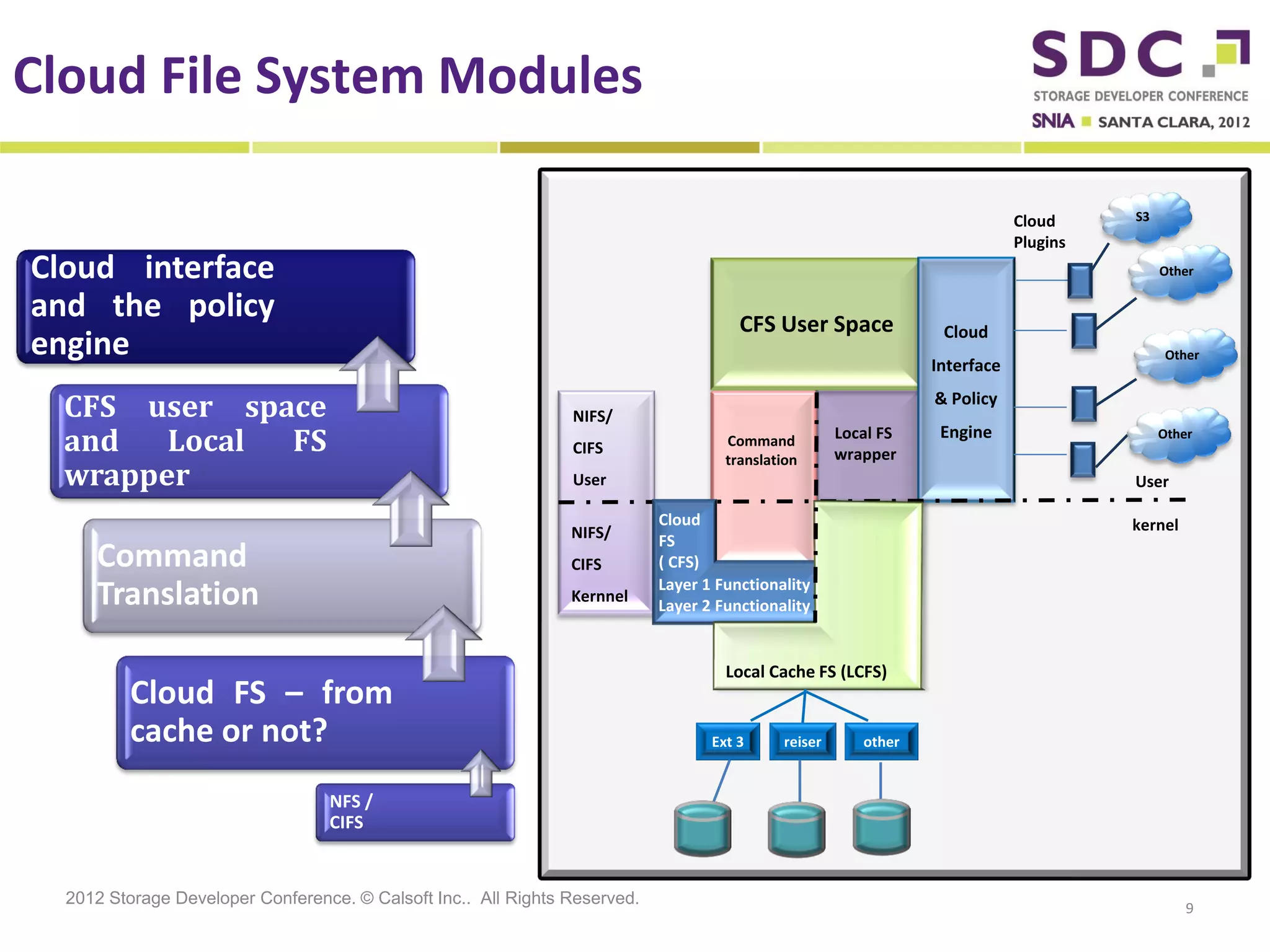
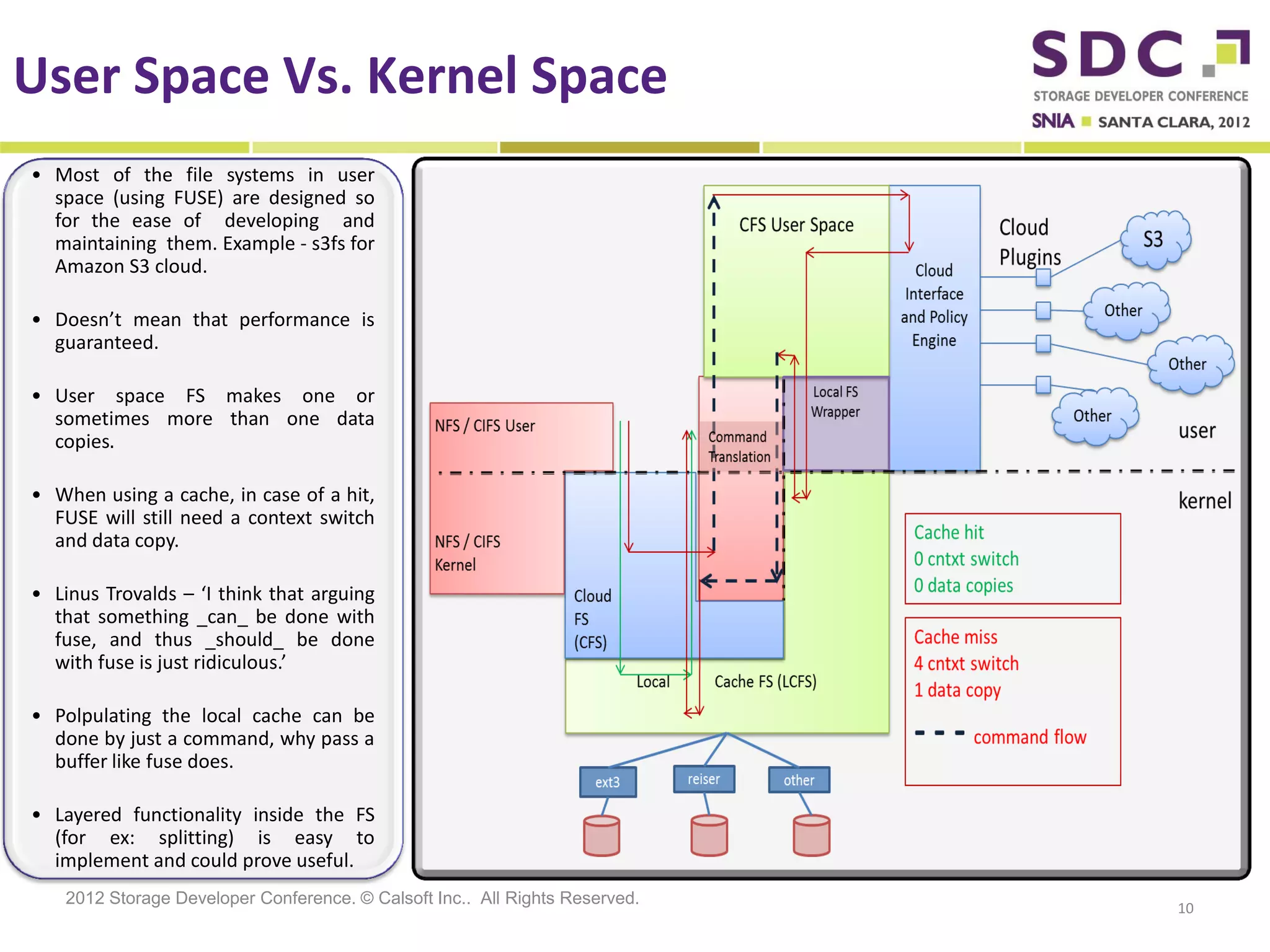

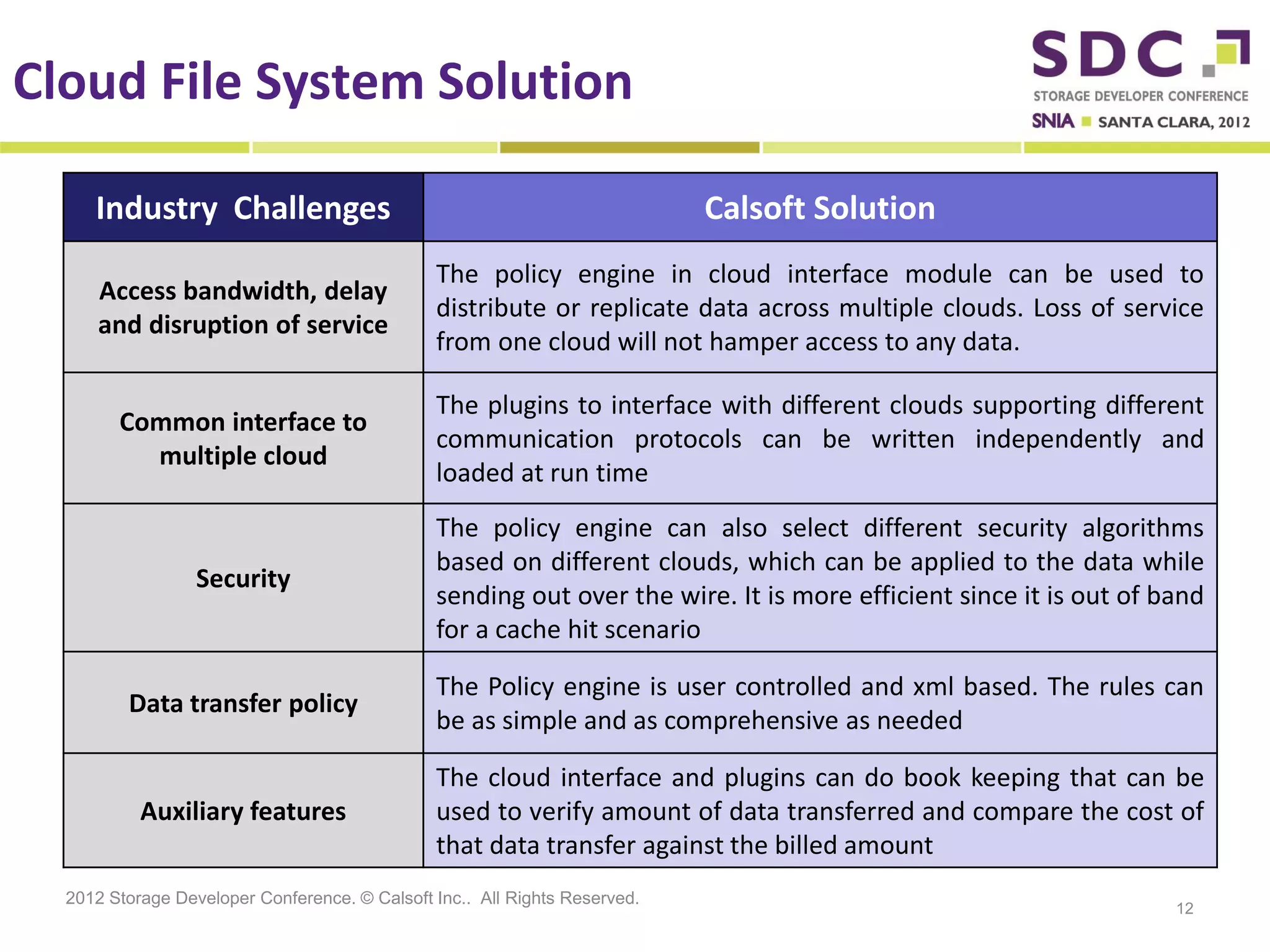





The document discusses the integration of cloud storage with network-attached storage (NAS) using the Cloud Data Management Interface (CDMI) to enhance data management and access. Calsoft's Cloud File System enables seamless interaction between multiple cloud providers, facilitating efficient storage solutions and policy management for enterprises. It addresses industry challenges while promoting an efficient approach to managing large-scale data storage across compliant and non-compliant clouds.




















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


