Downloaded 11 times









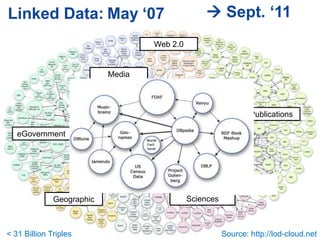

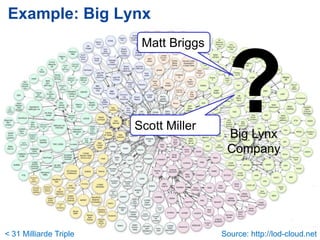

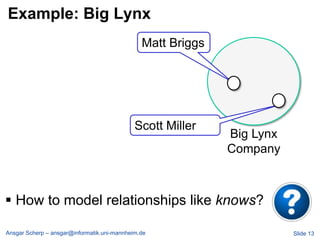


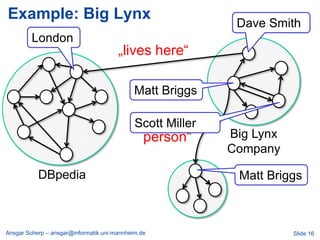





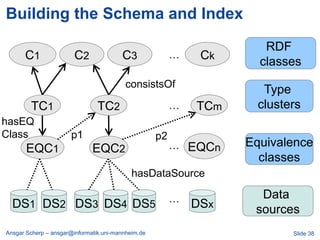
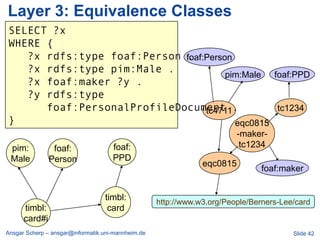
![Billion Triple Challenge 2008
[JWS 2009]
Ansgar Scherp – ansgar@informatik.uni-mannheim.de Slide 30](https://image.slidesharecdn.com/linkedopendata-howtojugglewithmorethanabilliontriples-121017041912-phpapp02/85/Linked-open-data-how-to-juggle-with-more-than-a-billion-triples-30-320.jpg)



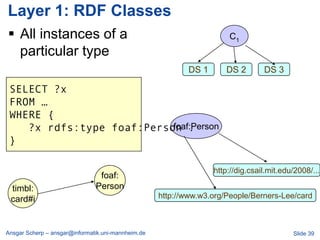
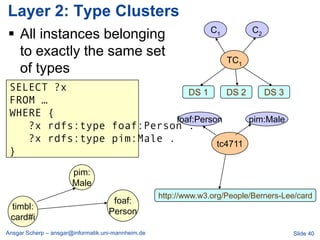
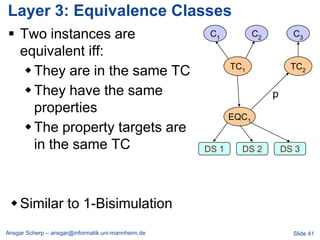


![Billion Triple Challenge 2011
…
[JWS 2012]
Ansgar Scherp – ansgar@informatik.uni-mannheim.de Slide 46](https://image.slidesharecdn.com/linkedopendata-howtojugglewithmorethanabilliontriples-121017041912-phpapp02/85/Linked-open-data-how-to-juggle-with-more-than-a-billion-triples-46-320.jpg)



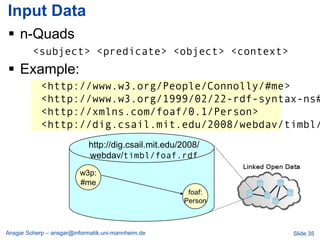
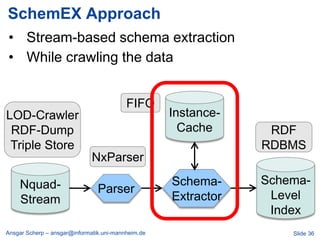
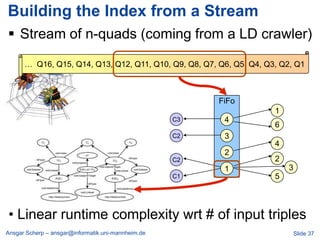
Ansgar Scherp discusses the challenges and methodologies associated with managing over a billion triples in linked data, highlighting the difficulties of data integration and interoperability in public transport scenarios. He emphasizes the significance of properly identifying, interlinking, and describing resources using URIs and RDF. The presentation also outlines various approaches, such as the semaplorer method and schemex, for scalable and efficient data management.









































































