Downloaded 114 times
![How SourceForge is Using MongoDB Rick Copeland @rick446 [email_address]](https://image.slidesharecdn.com/mongoatl-110208143555-phpapp02/85/MongoATL-How-Sourceforge-is-Using-MongoDB-1-320.jpg)













![Rick Copeland @rick446 [email_address]](https://image.slidesharecdn.com/mongoatl-110208143555-phpapp02/85/MongoATL-How-Sourceforge-is-Using-MongoDB-17-320.jpg)

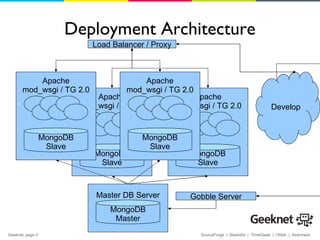
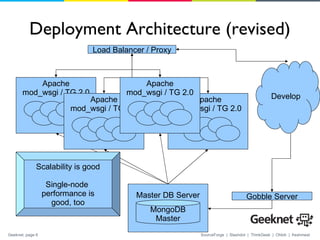
1. SourceForge is using MongoDB as the database for their website to improve performance and scalability over their previous CouchDB implementation. 2. They developed an object-document mapper called Ming to define schemas and perform migrations for the documents in MongoDB from their Python web application. 3. SourceForge's deployment uses load balancing with a master MongoDB database server and multiple web application servers to easily handle most of their traffic needs from a single database server.


























































































