Download as PDF, PPTX



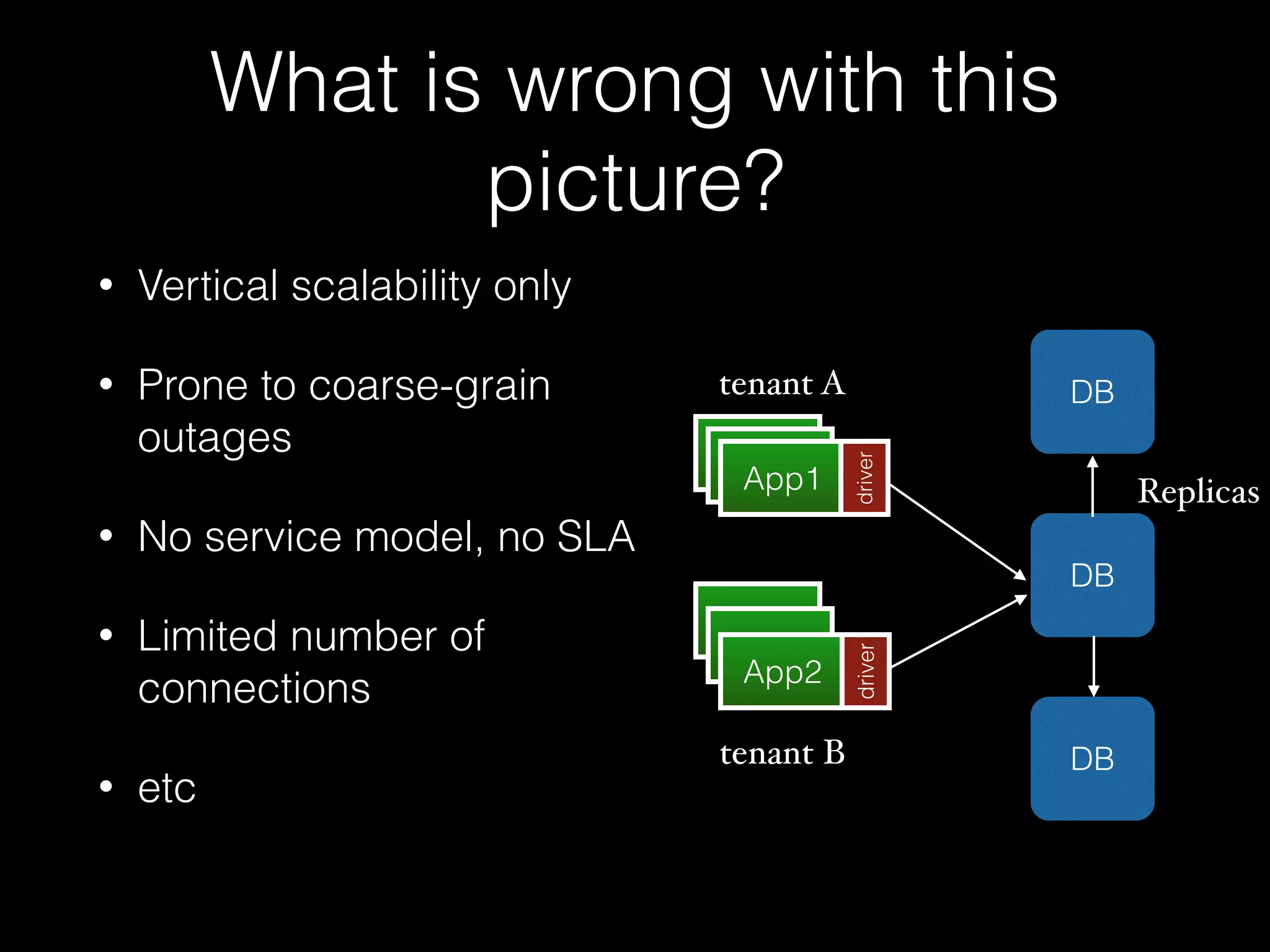
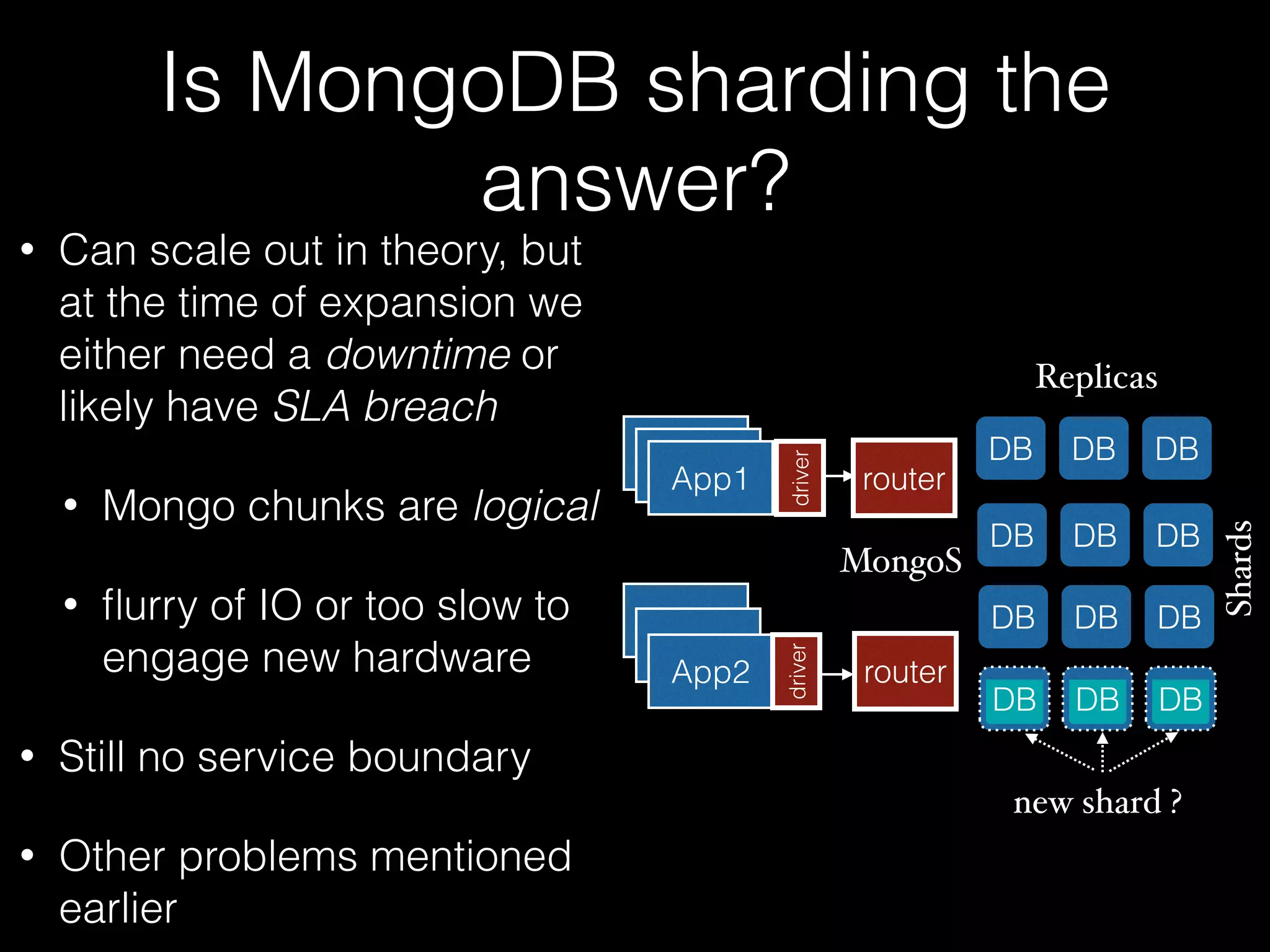
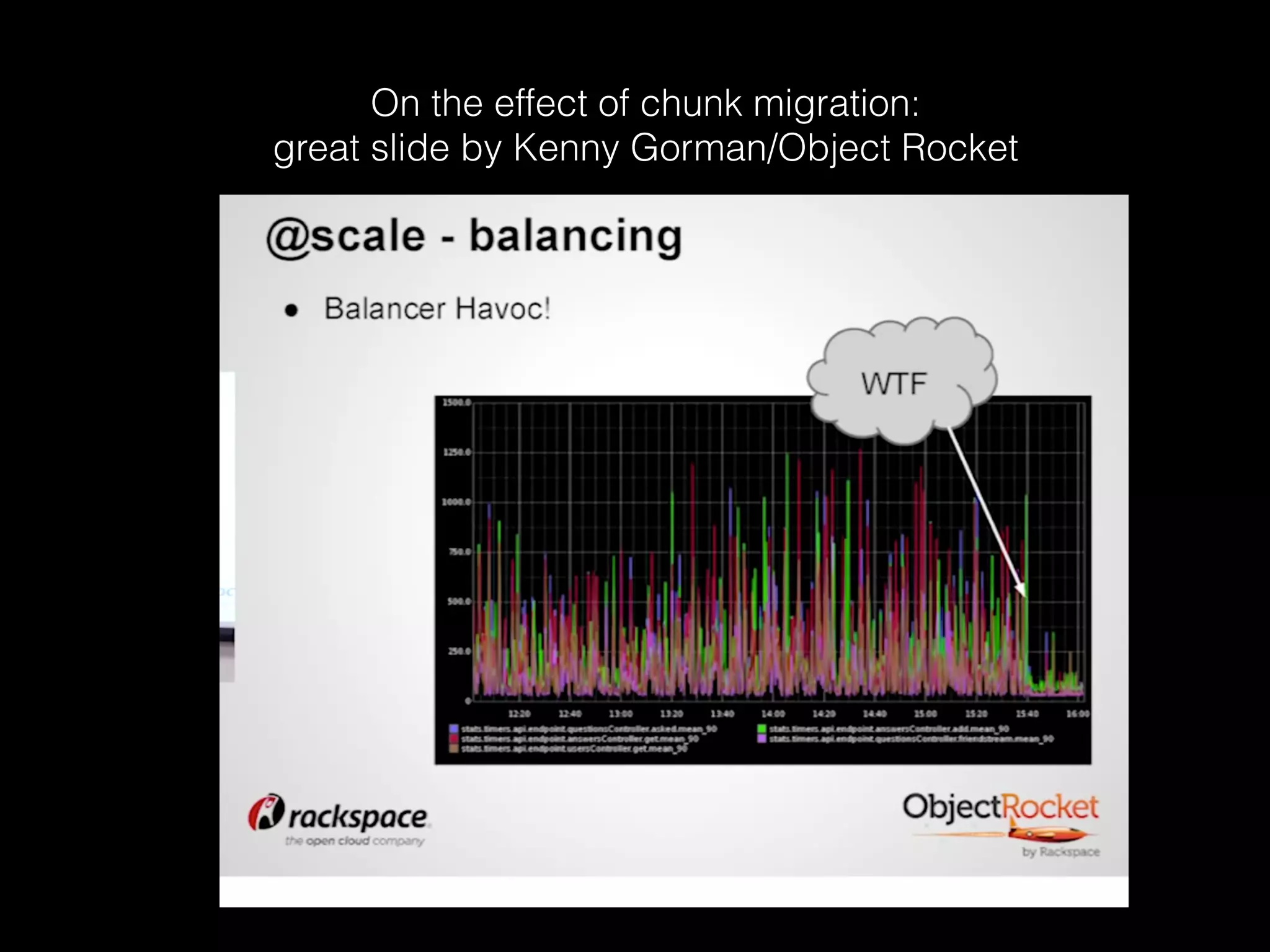


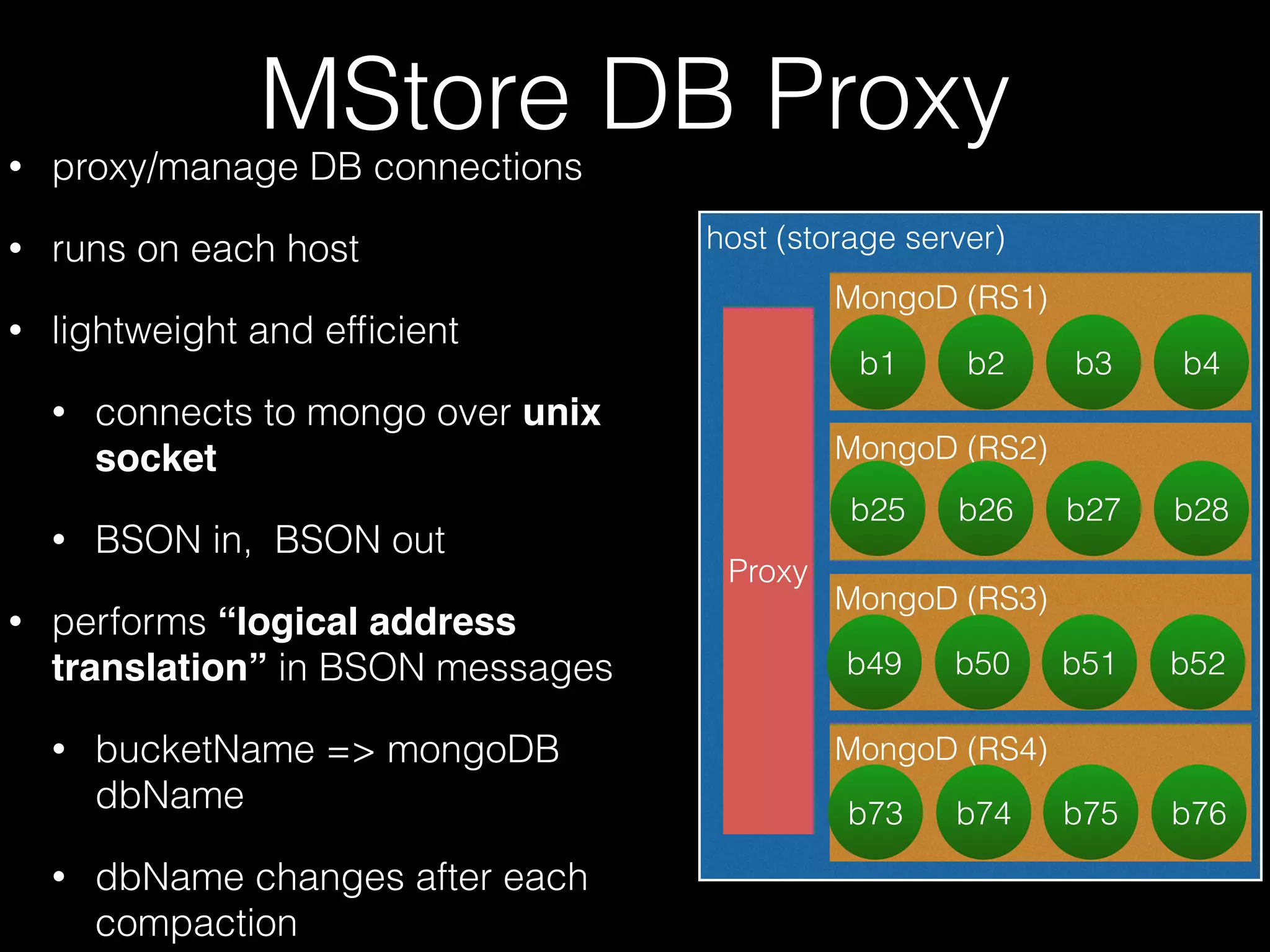
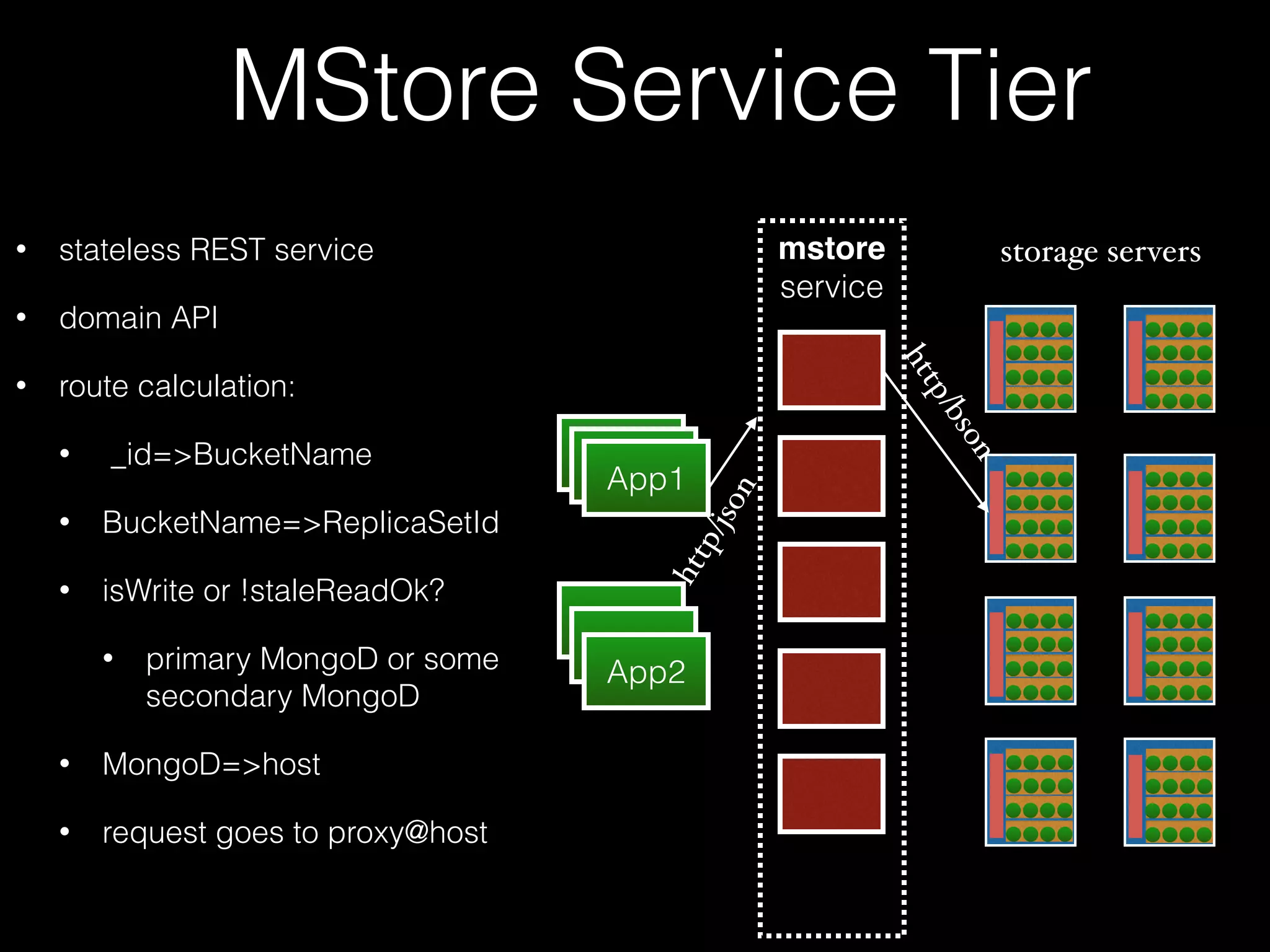
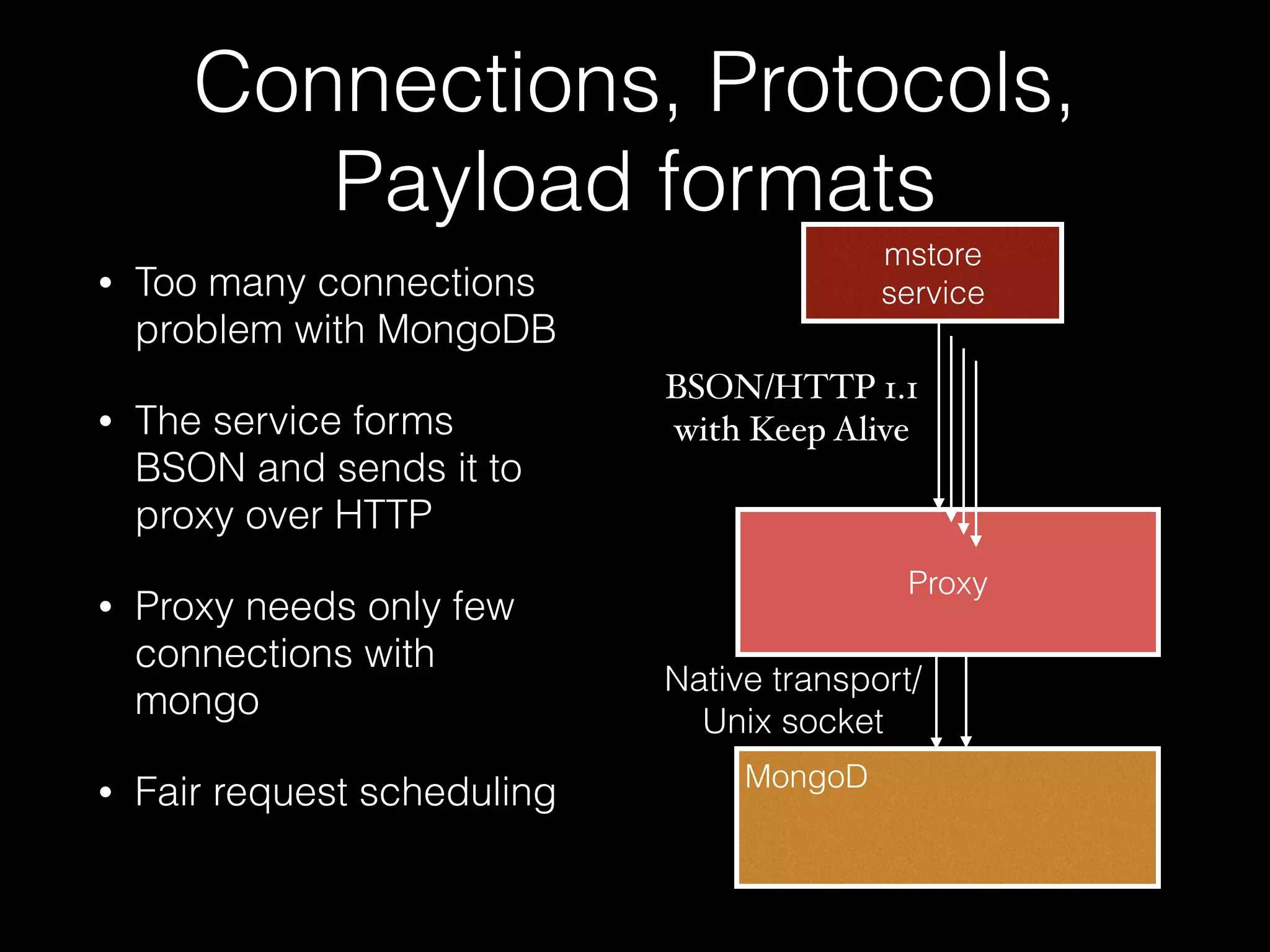
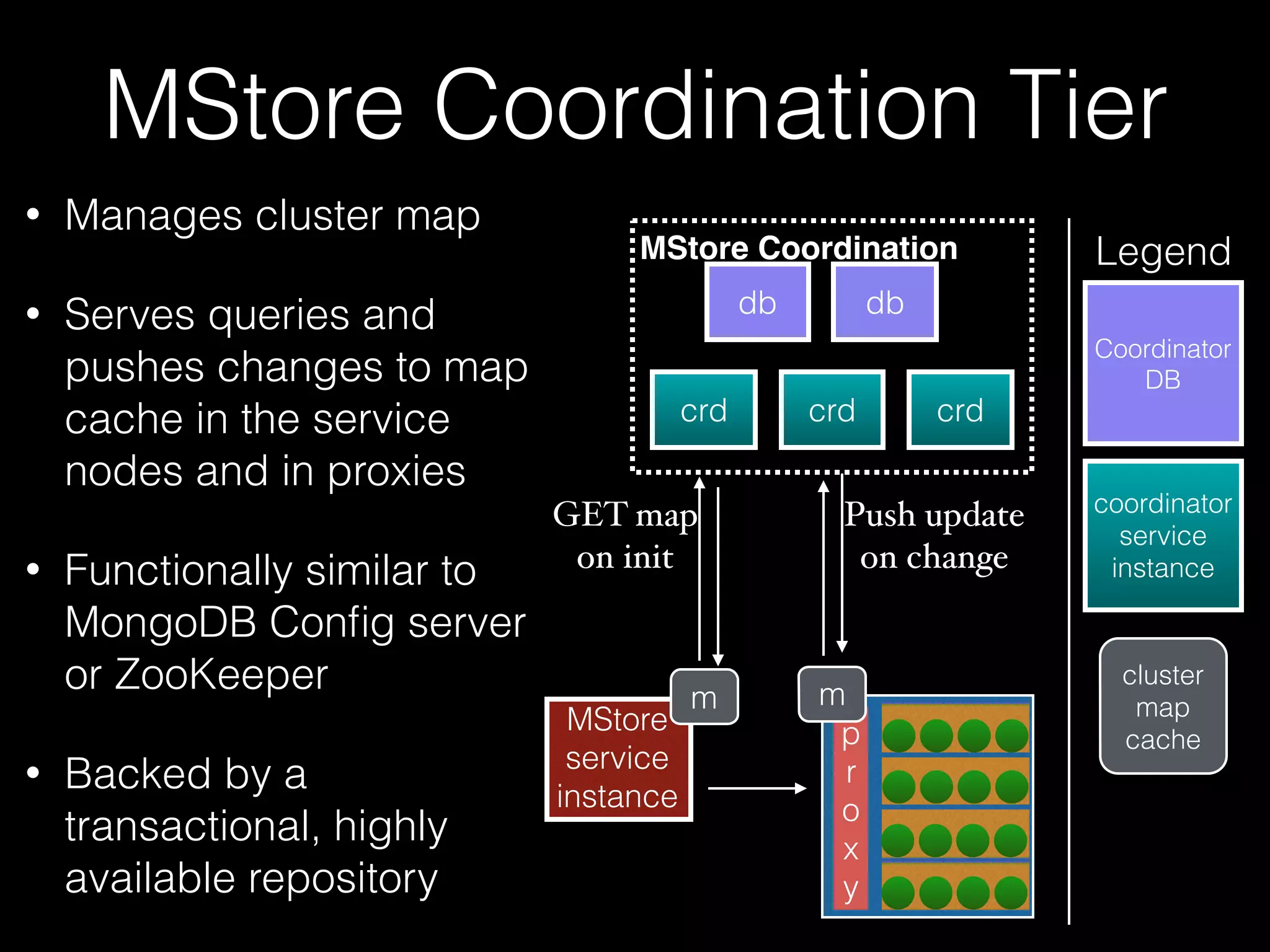
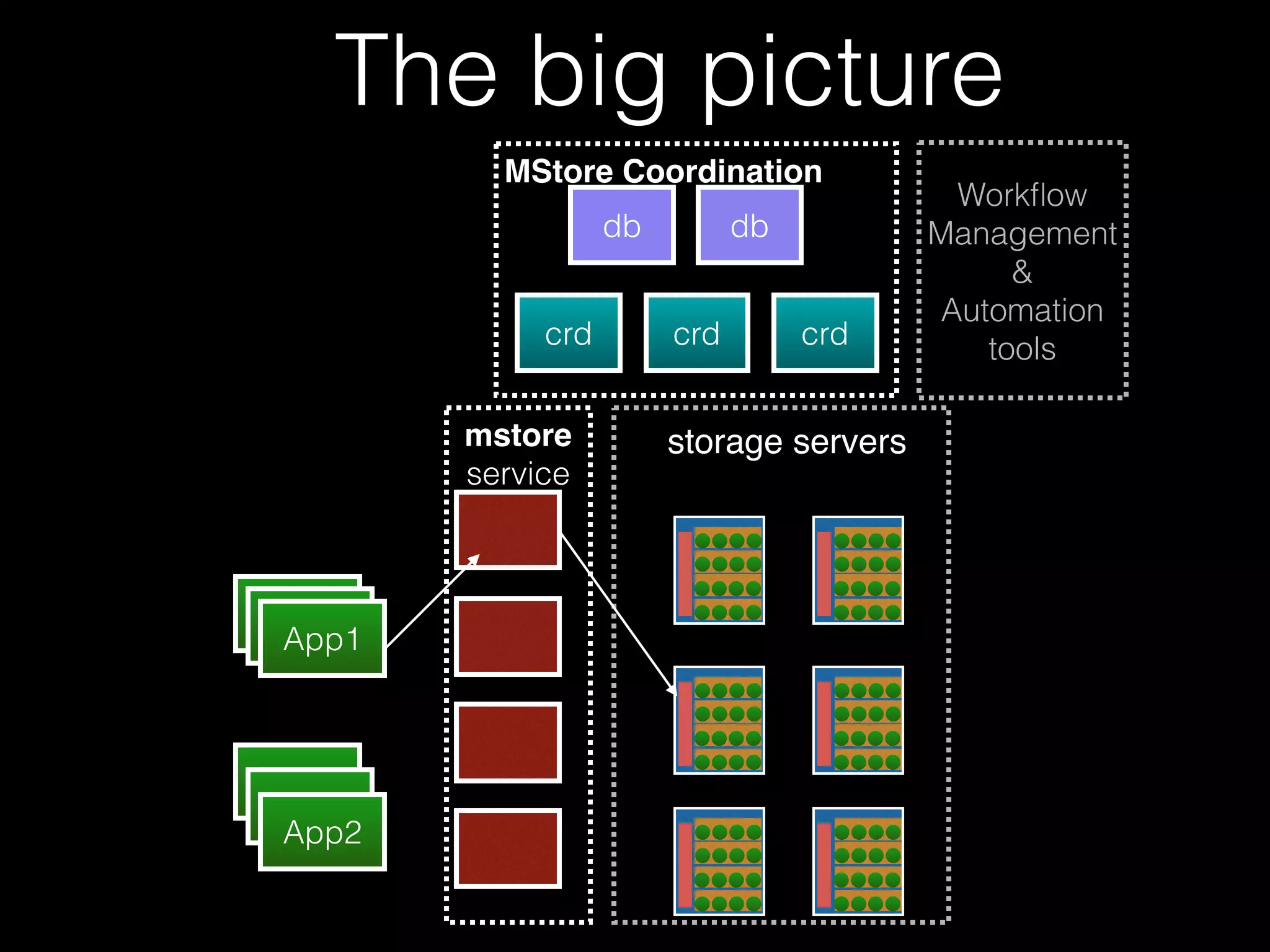
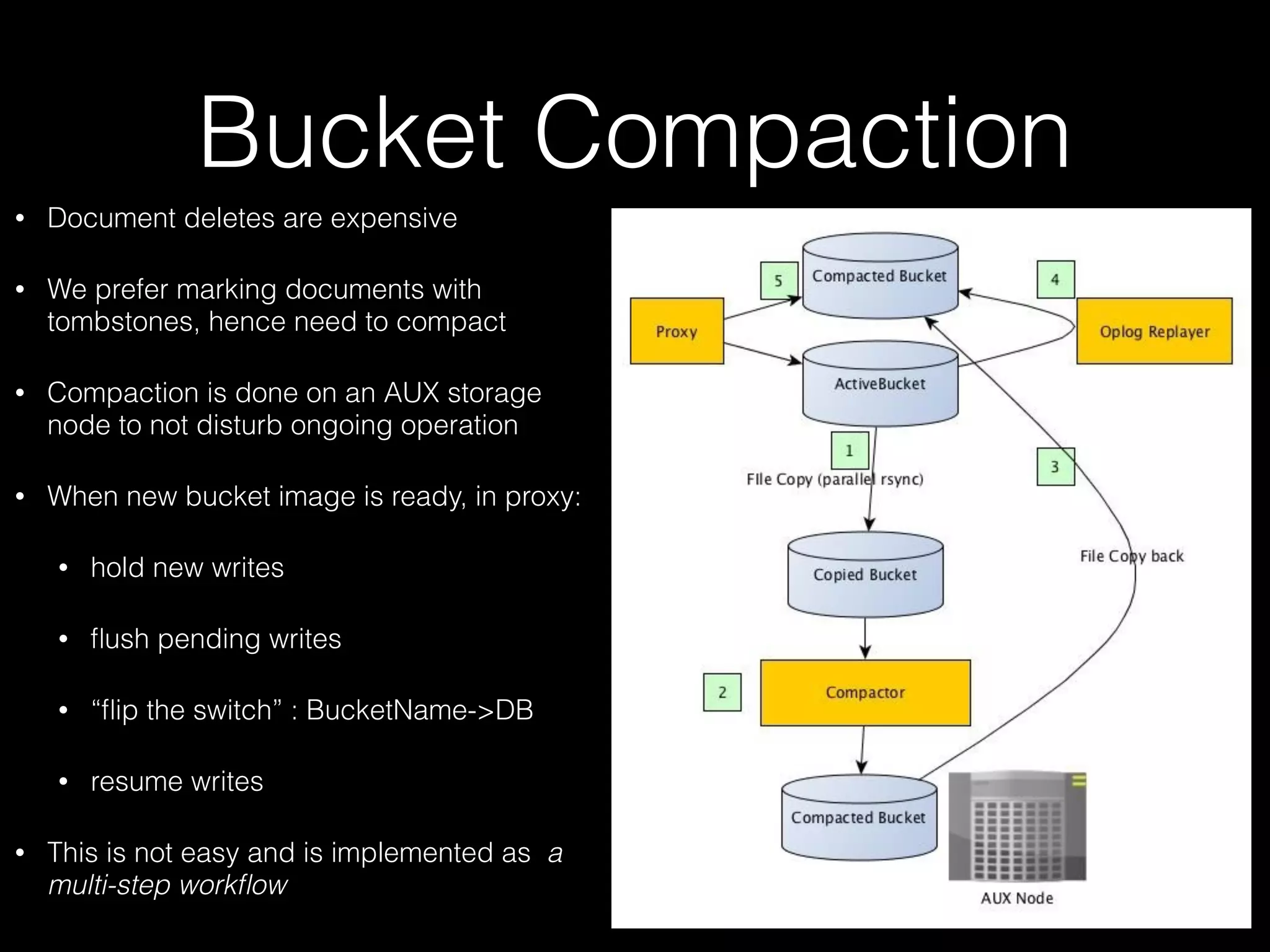






The document outlines the design of an elastic metadata store for eBay's media platform, detailing the necessity of a data service layered on top of MongoDB to manage a predominantly read-driven workload with minimal downtime. It introduces a bucket-based architecture to enhance scalability, data lifecycle management, and efficiency during operations such as compaction and data migration. The approach includes a service tier that manages connections and workflow automation for bucket operations, aiming for seamless operation and robustness in managing data across multiple tenants.

































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)

















![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
















