Downloaded 10 times















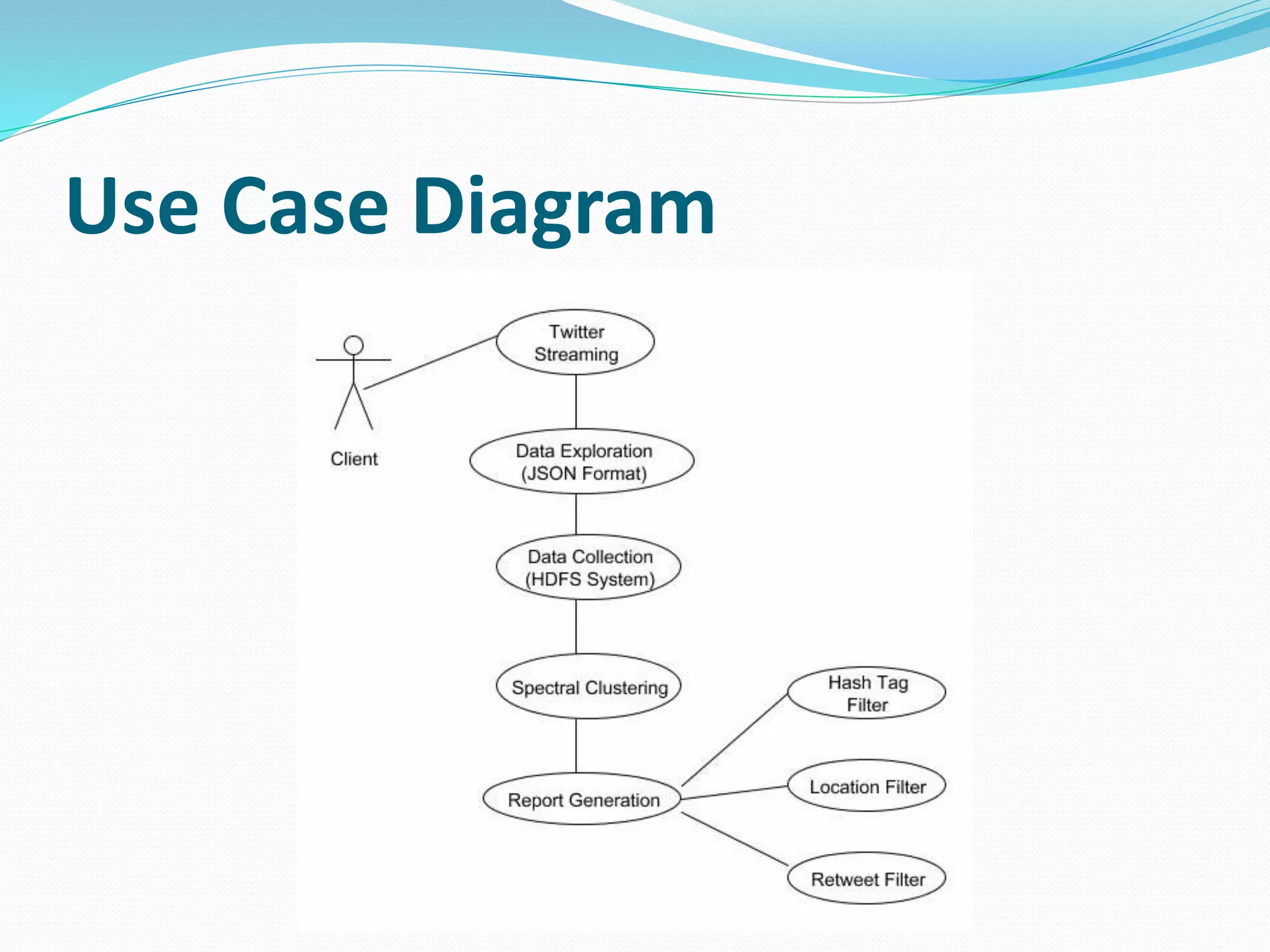
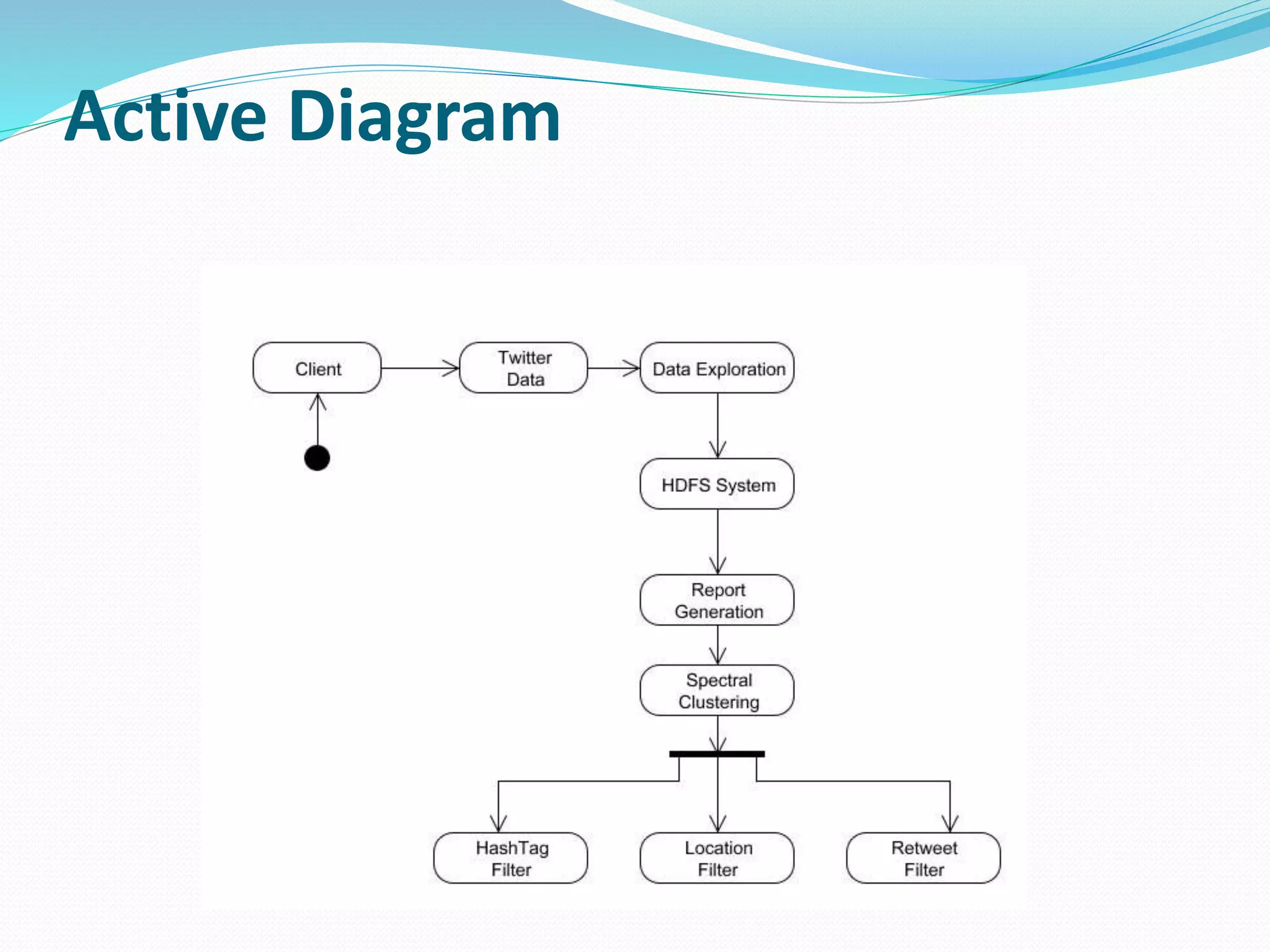
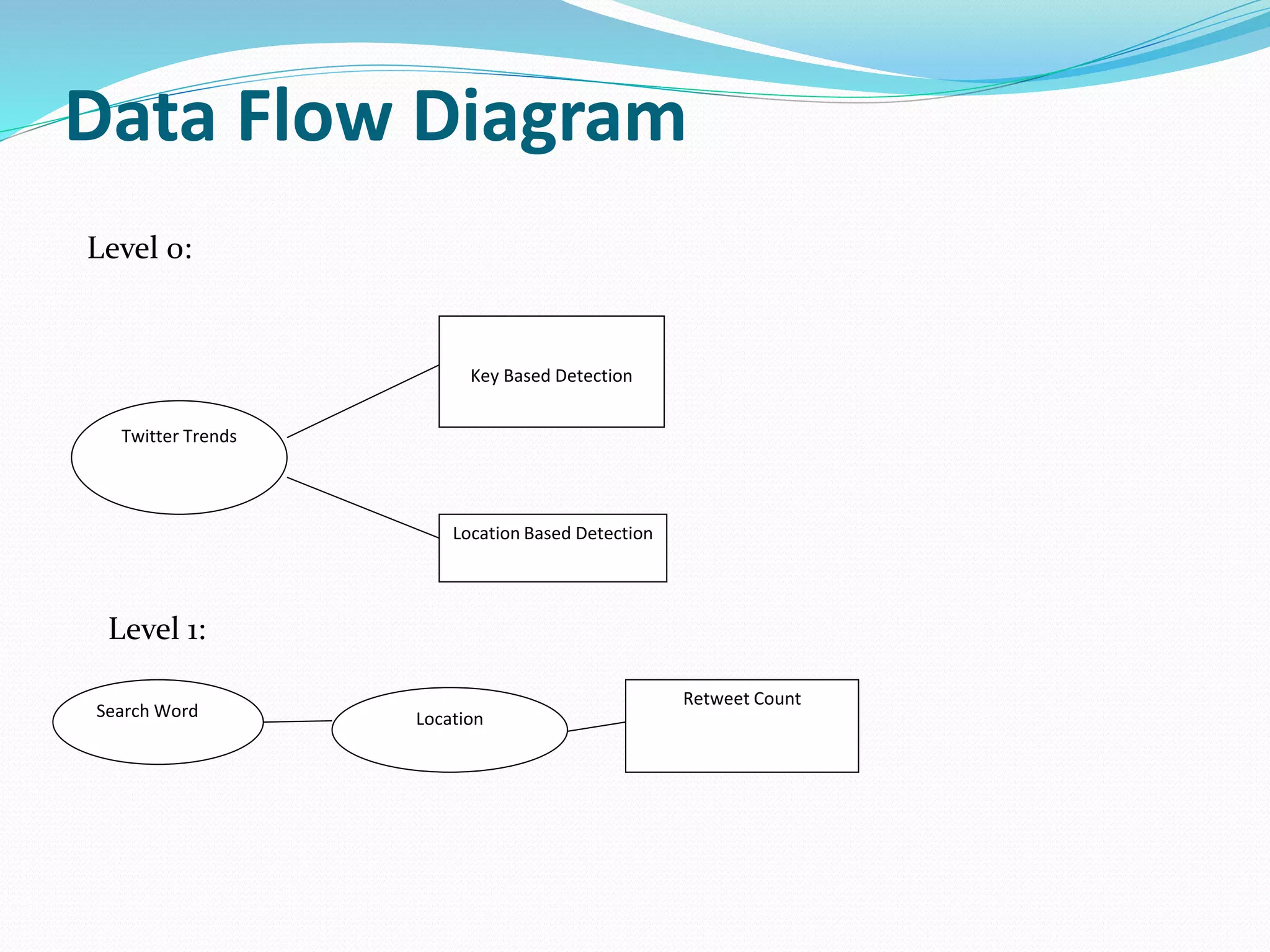
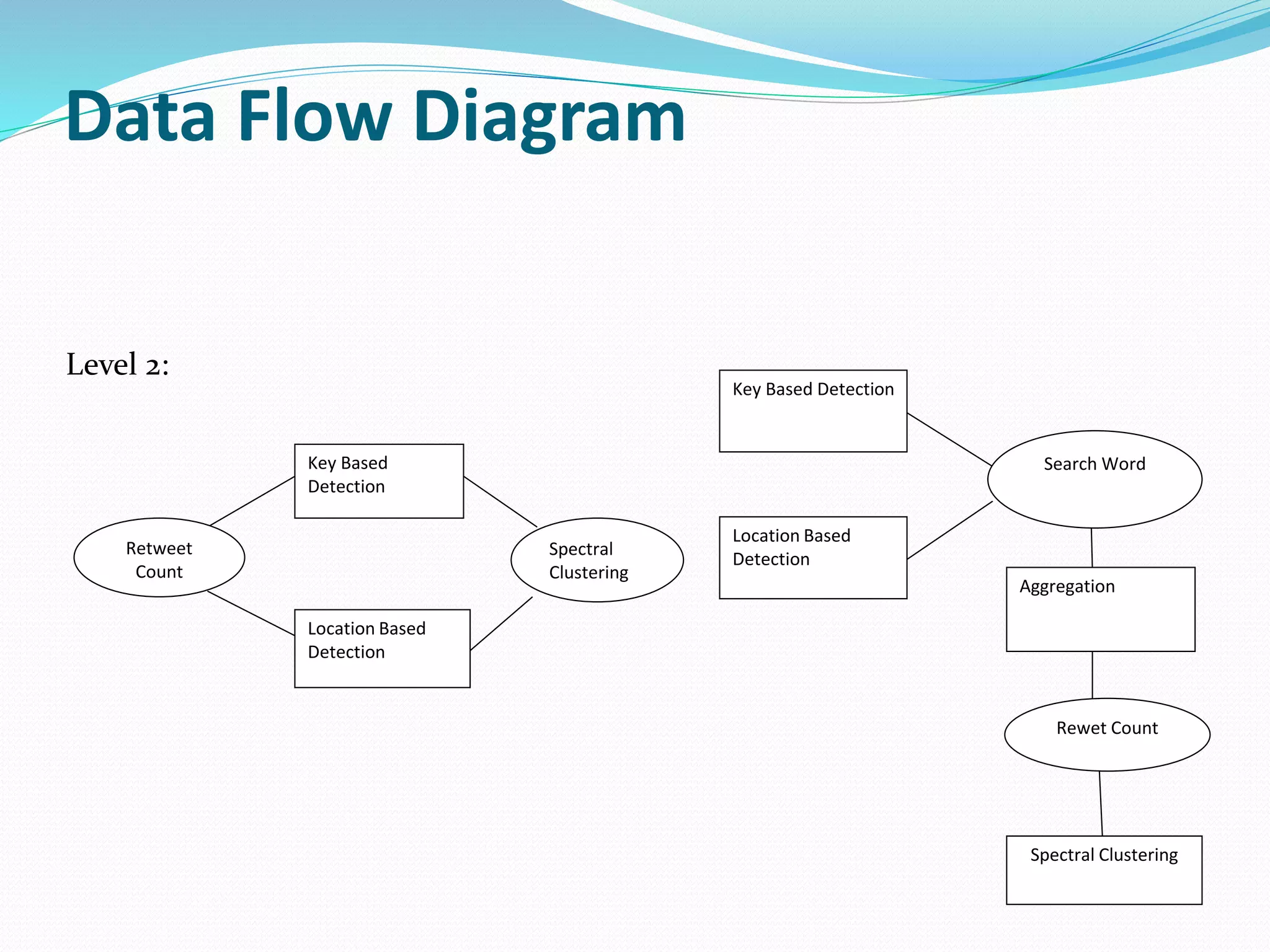
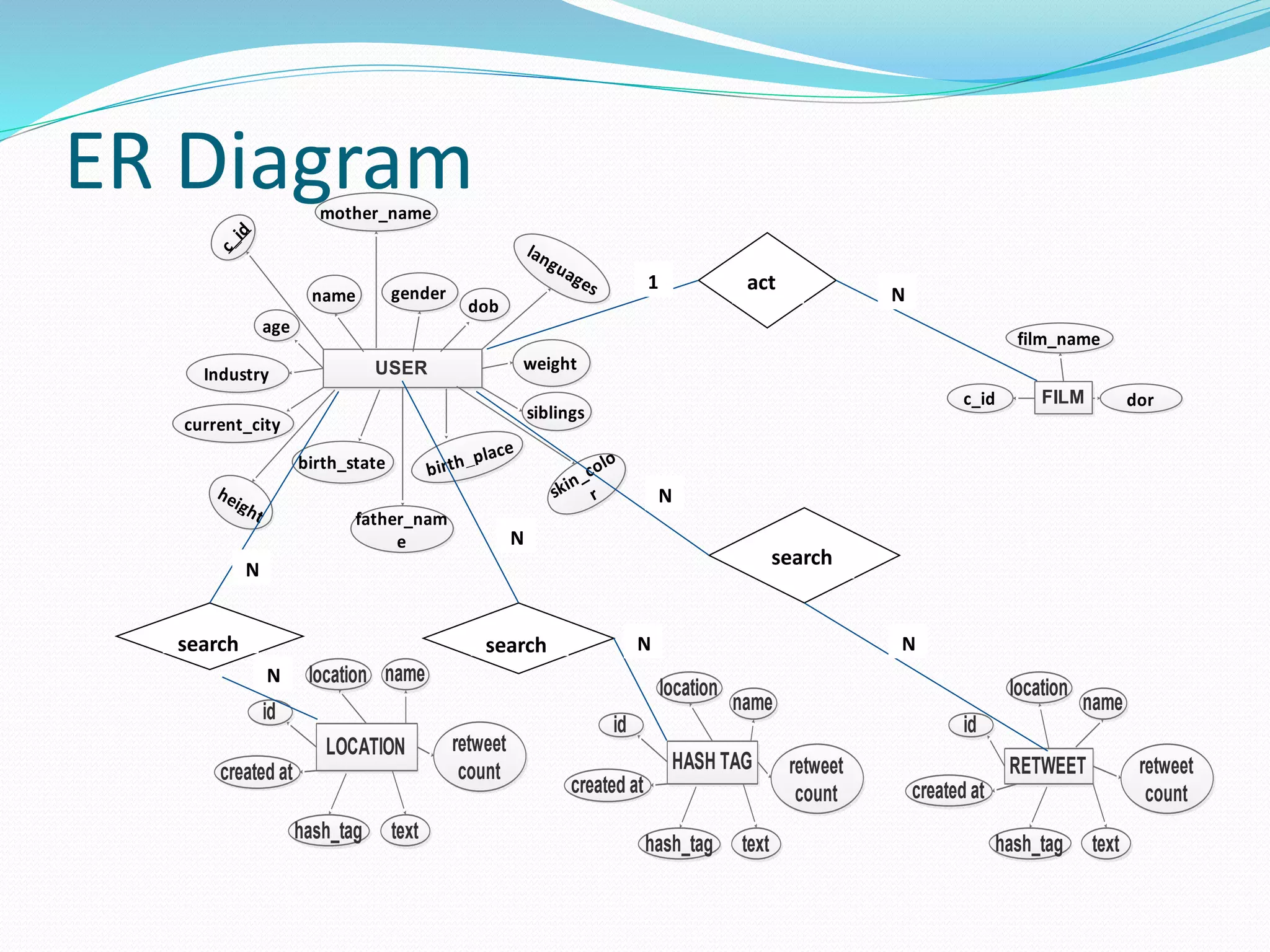
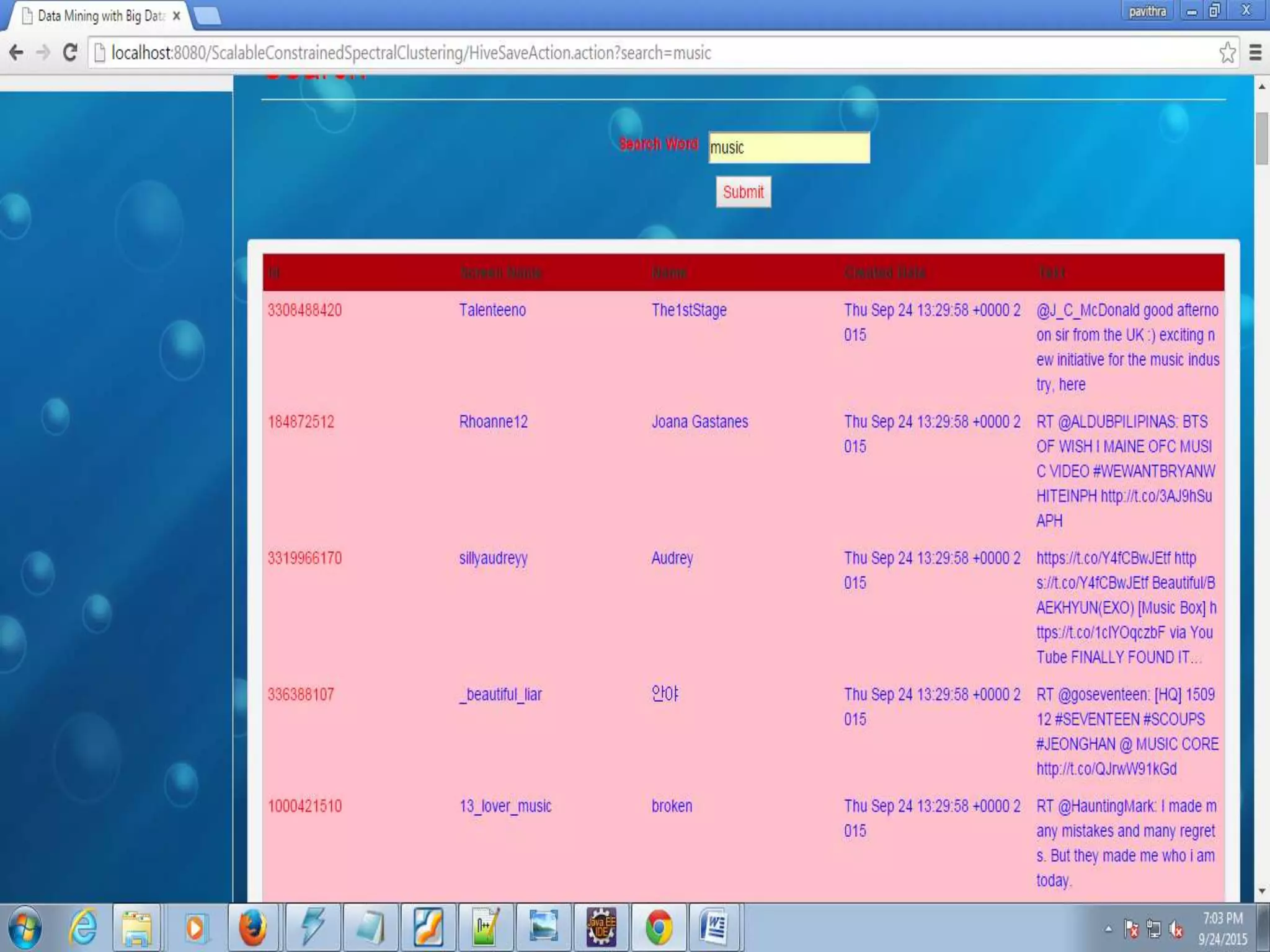
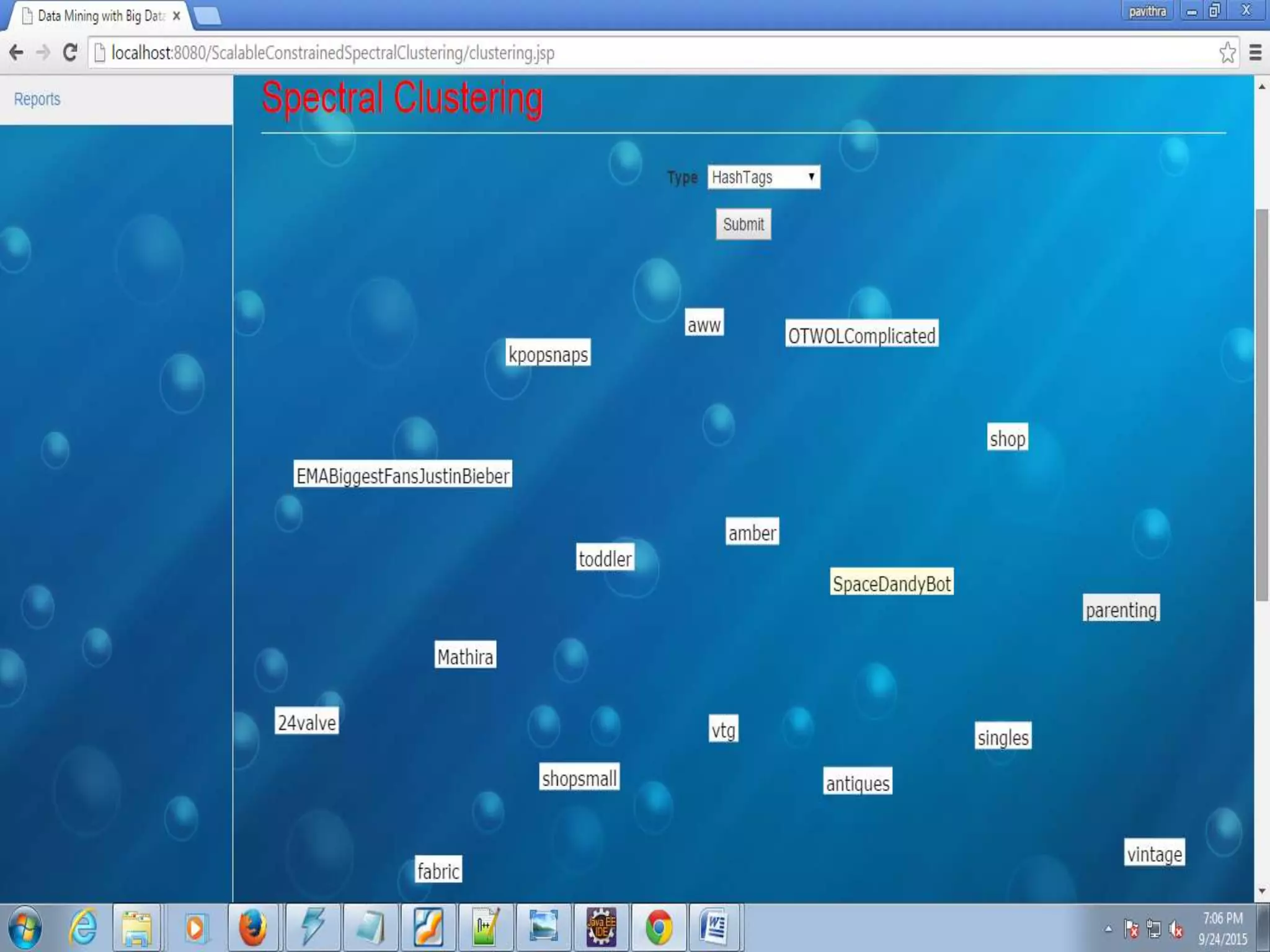



The document proposes a scalable constrained spectral clustering (SCACS) algorithm to improve the efficiency of existing constrained spectral clustering methods in handling moderate and large datasets. SCACS integrates sparse coding-based graph construction into the constrained normalized cuts framework. This allows it to scale to large datasets while maintaining high clustering accuracy comparable to state-of-the-art methods but with less computational time and side information. The algorithm is presented as the first efficient and scalable version for constrained spectral clustering.


















































































