Downloaded 30 times








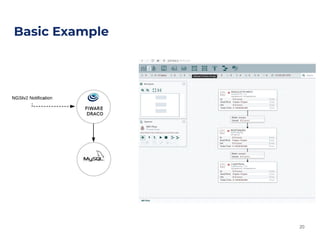



![def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
// Create Orion Source. Receive notifications on port 9001
val eventStream = env.addSource(new OrionSource(9001))
// Process event stream
val processedDataStream = eventStream
.flatMap(event => event.entities)
.map(entity => {
val temp = entity.attrs("temperature").value.asInstanceOf[Number].floatValue()
(entity.id, temp)
})
.keyBy(0)
.timeWindow(Time.seconds(10))
.aggregate(new Average)
// print the results with a single thread, rather than in parallel
processedDataStream.print().setParallelism(1)
env.execute("Temperature avg example")
}
Demo: Average temperature for each entity](https://image.slidesharecdn.com/4-teamupm-bigdataandmachinelearningwithfiware1-191028101211/85/FIWARE-Global-Summit-Big-Data-and-Machine-Learning-with-FIWARE-25-320.jpg)



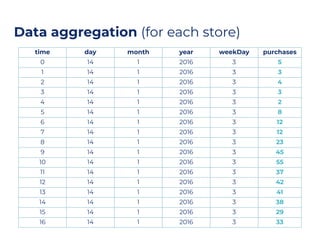
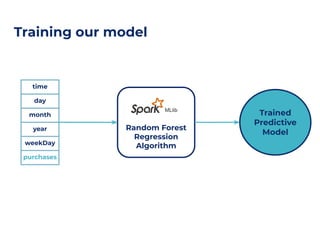
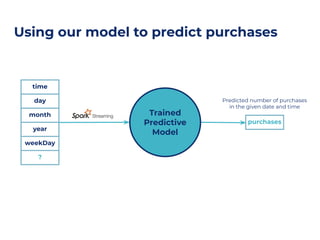
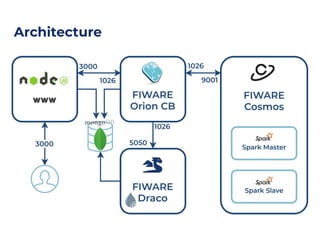
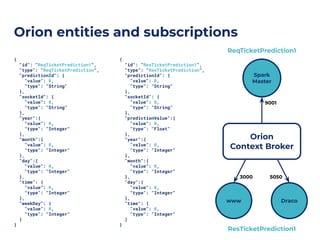




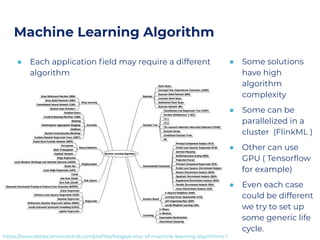
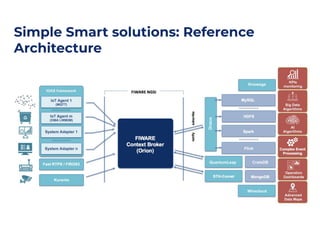
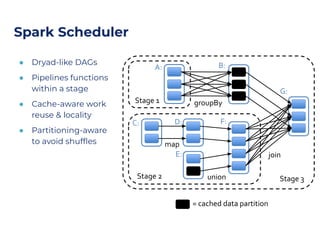
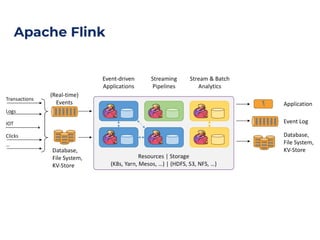
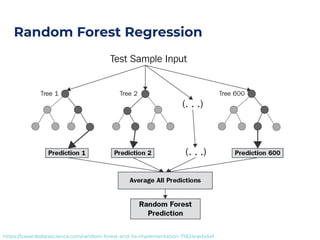
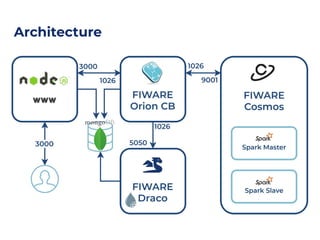
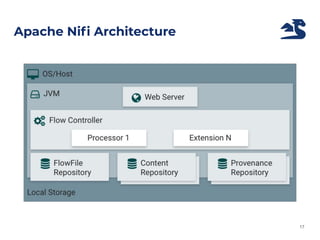
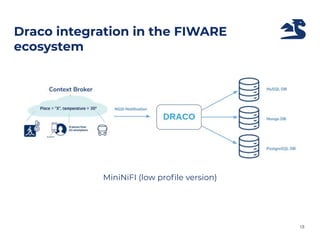
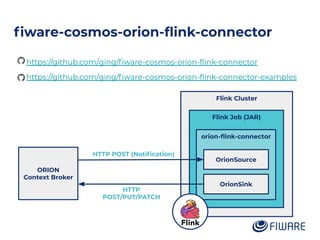
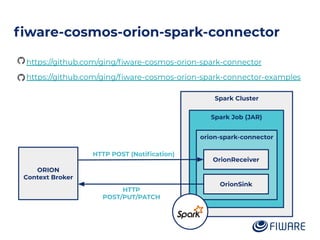
The document discusses an architecture integrating big data and machine learning through the FIWARE platform, highlighting specific algorithms like decision trees and random forests. It details the use and interconnectivity of components such as Apache NiFi and the Cosmos Generic Enabler for efficient data persistence and processing. Additionally, a practical use case is presented, predicting supermarket purchases using a random forest regression model, supported by an architecture based on the Orion Context Broker.




















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


