Downloaded 21 times



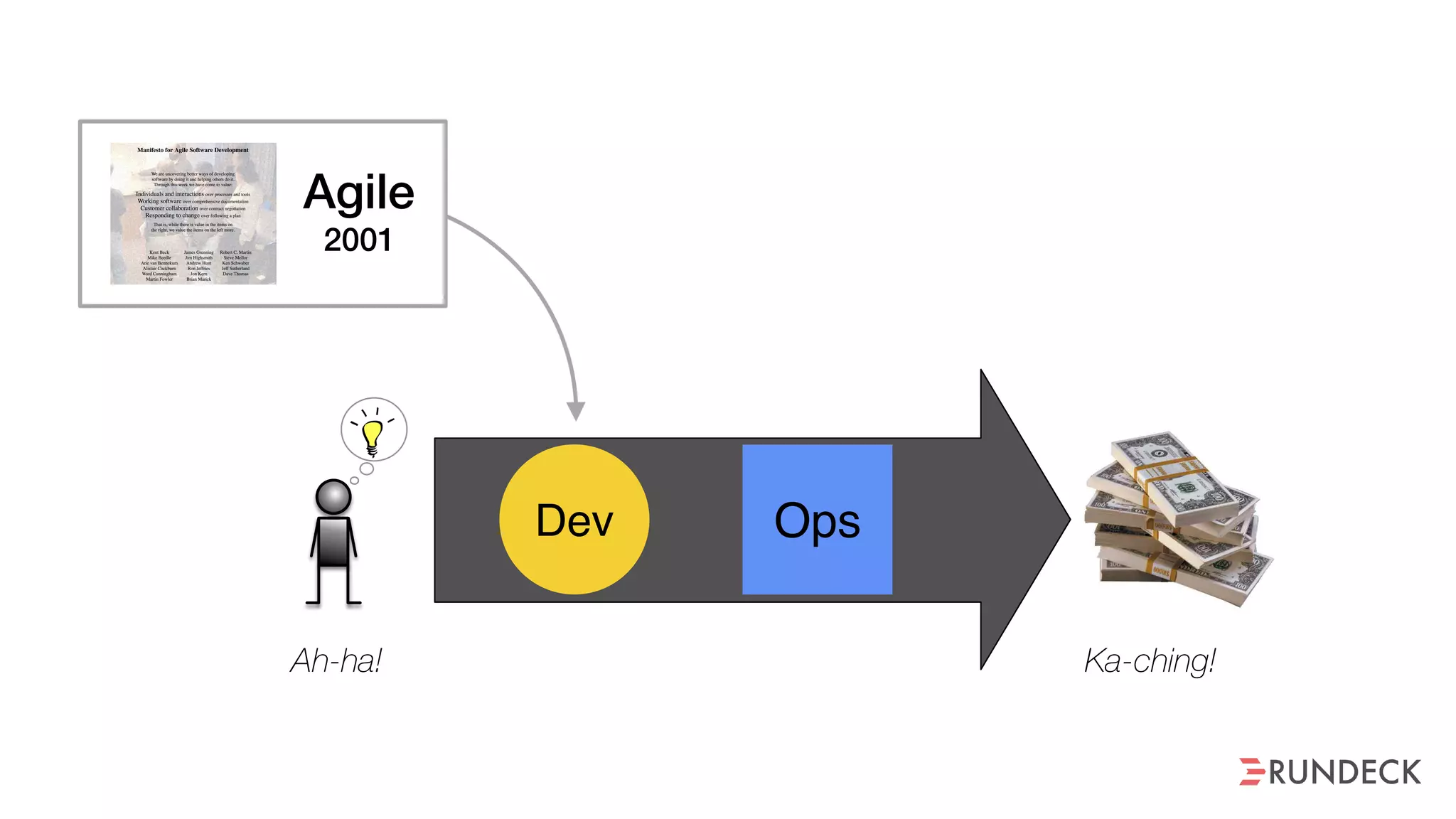

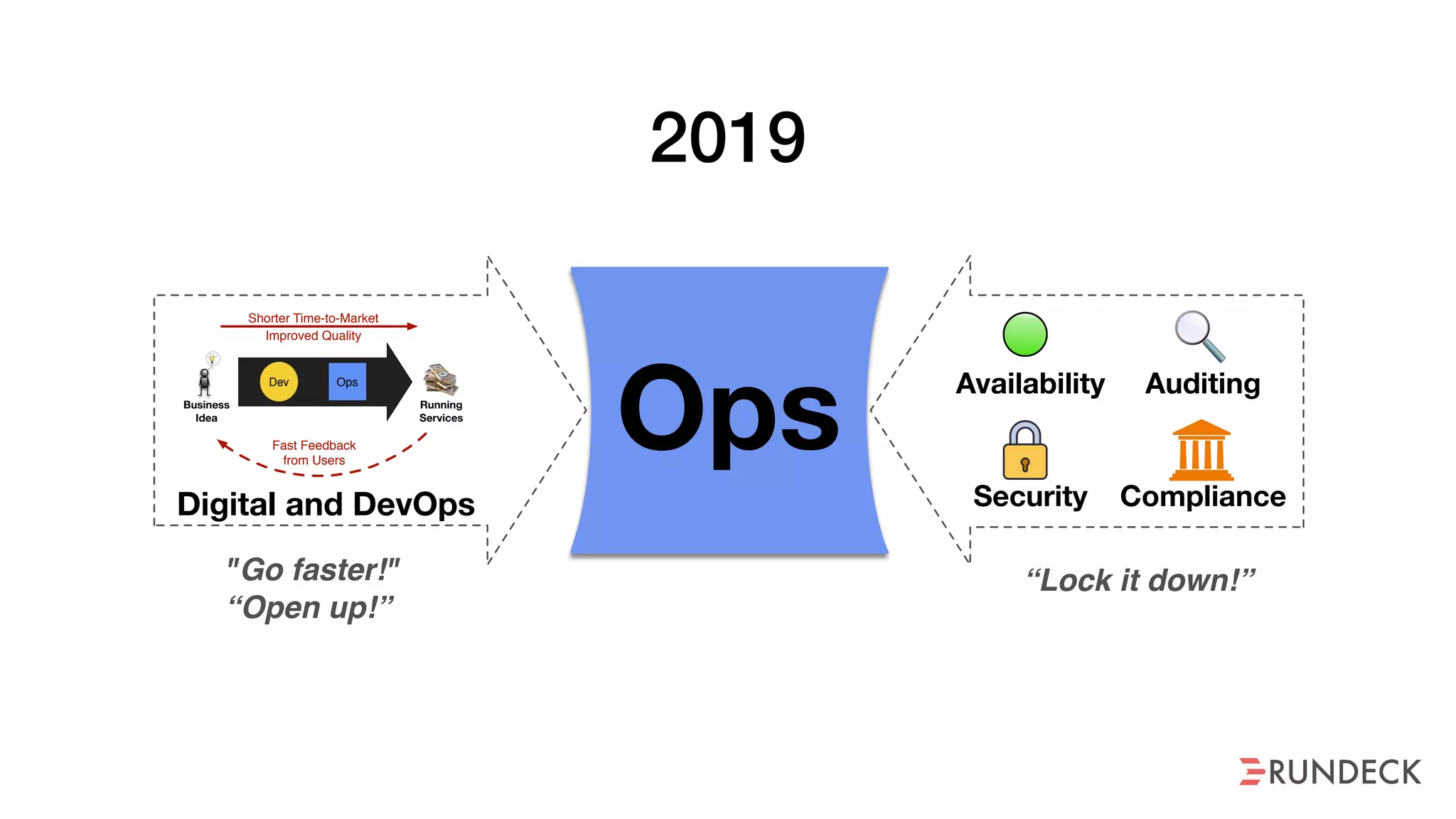




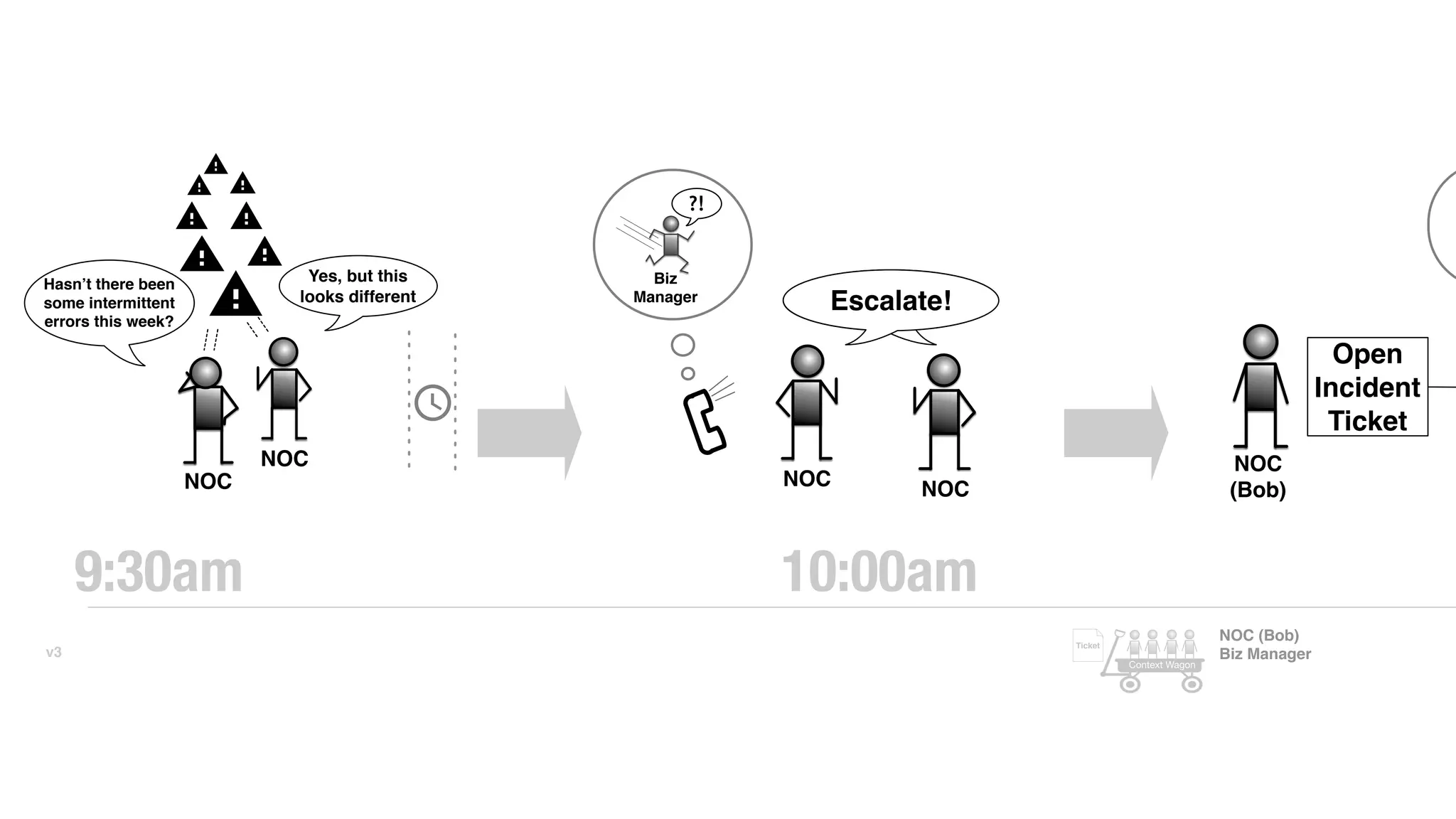

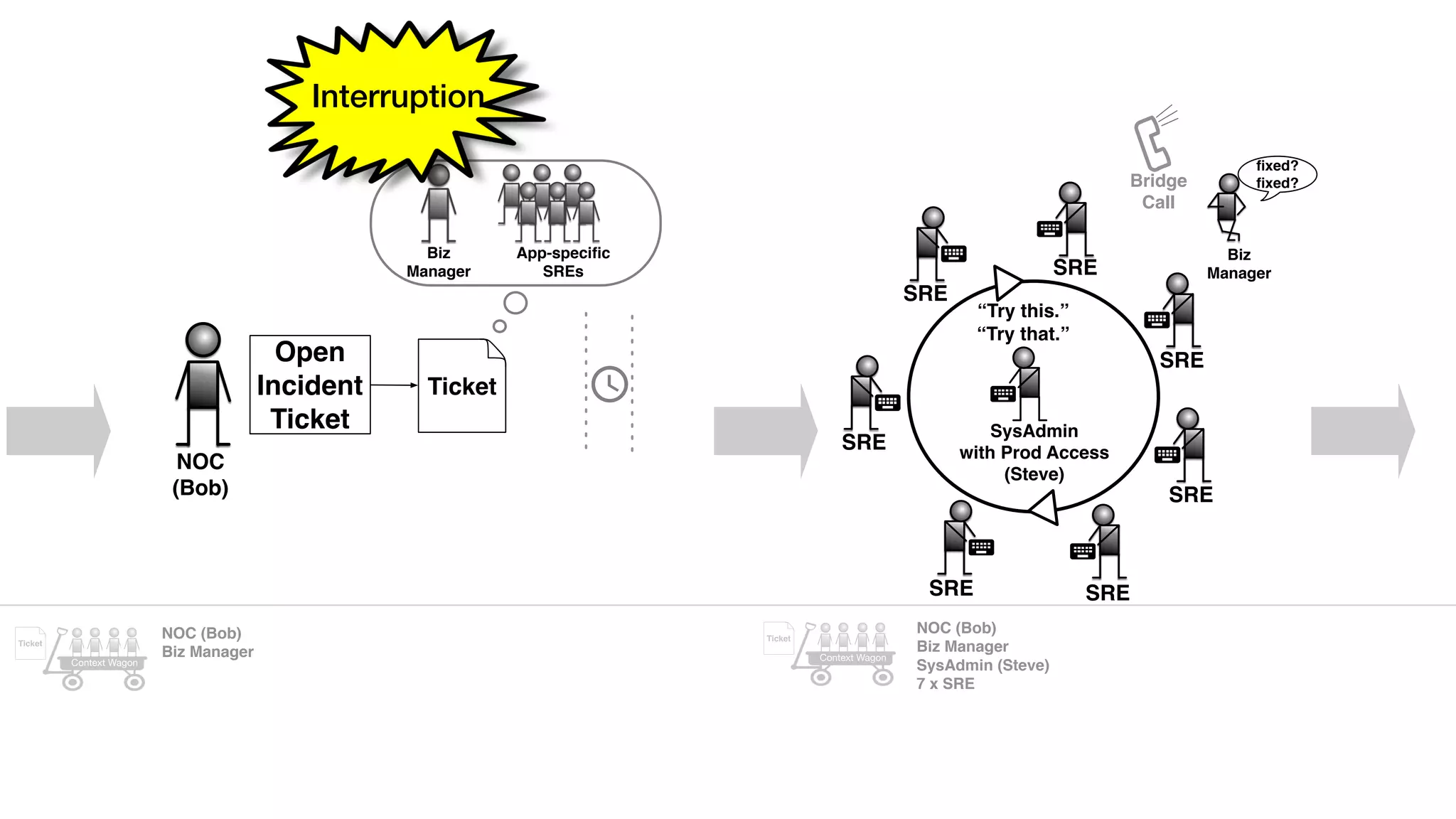

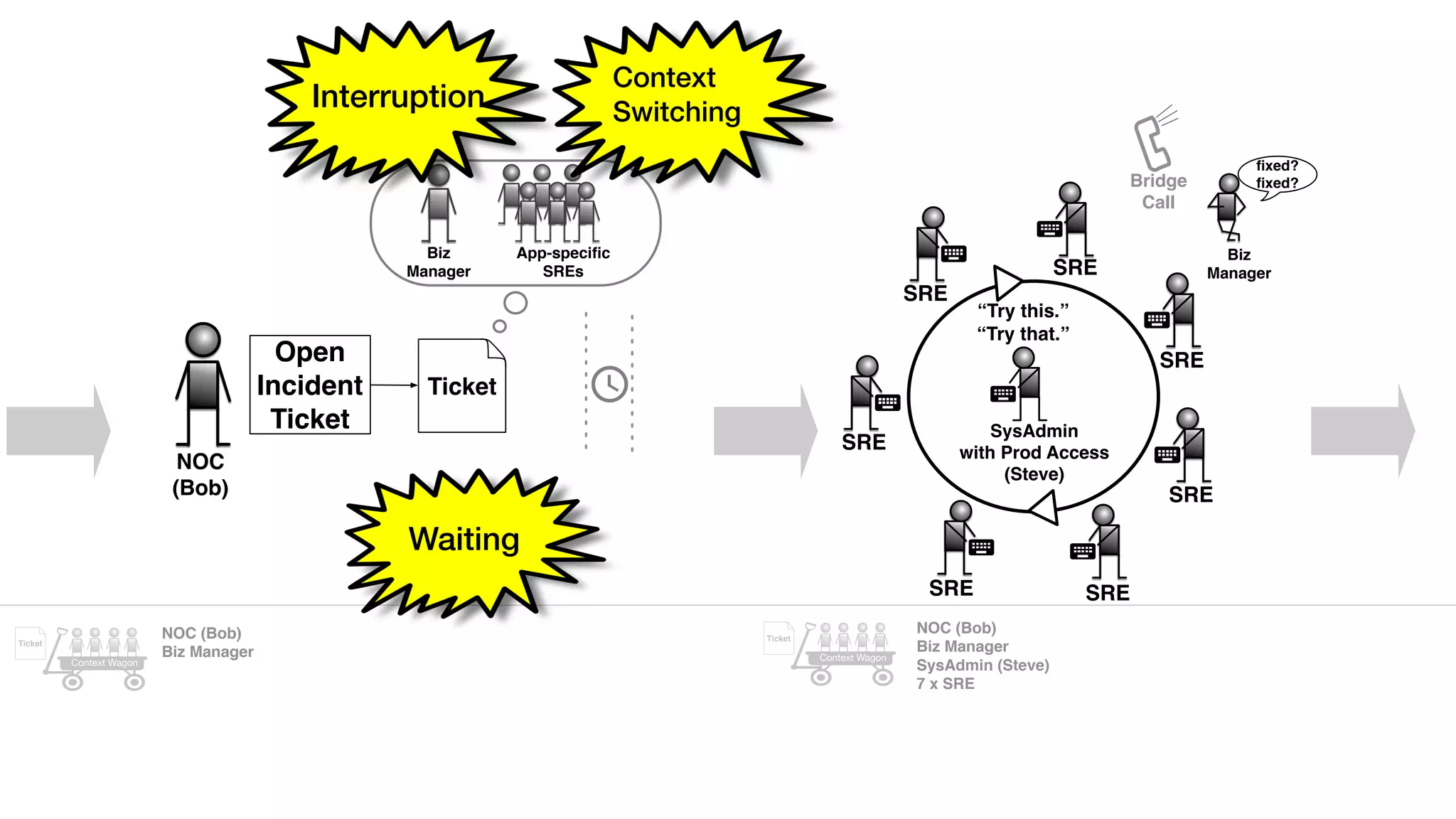
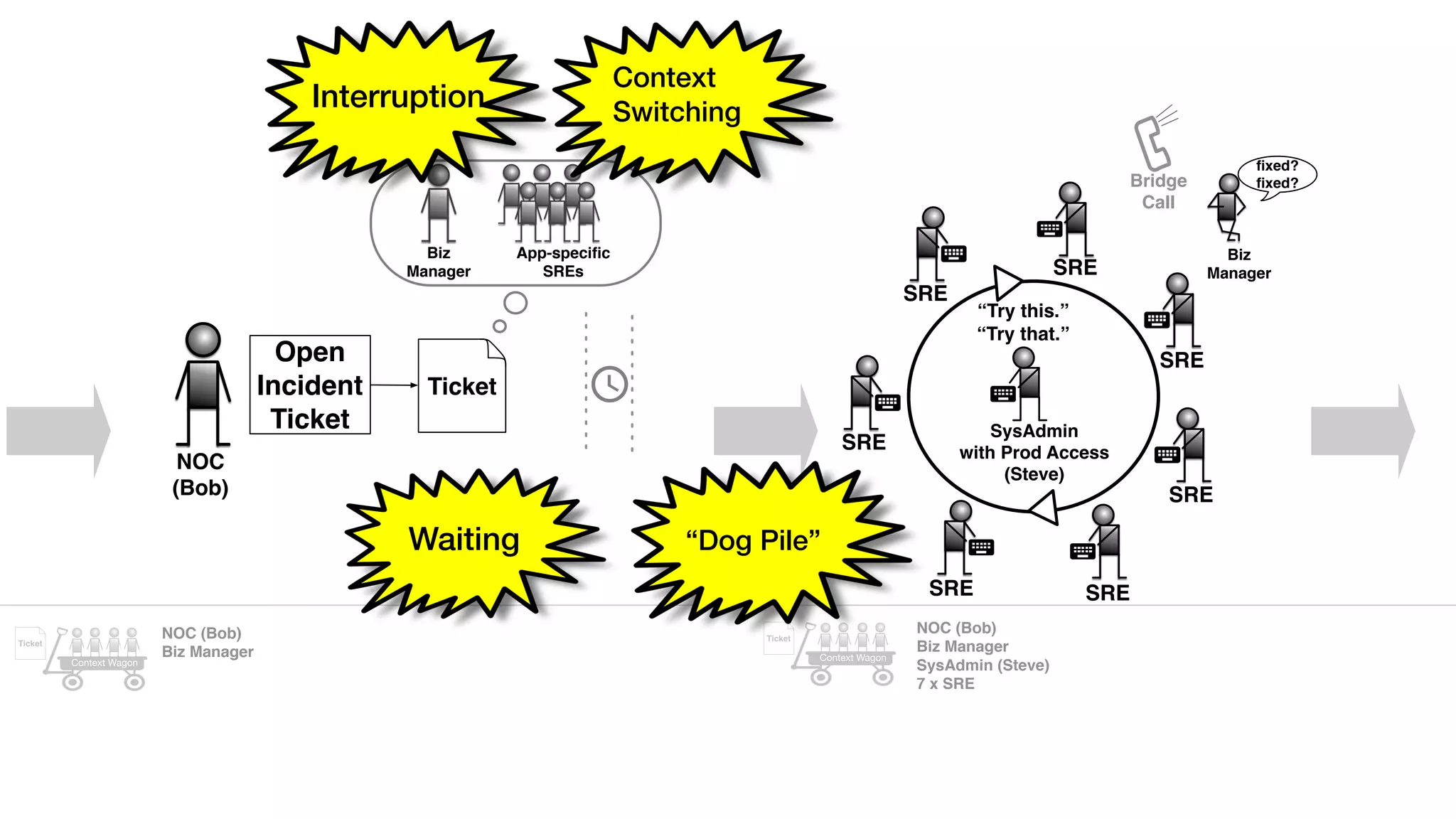

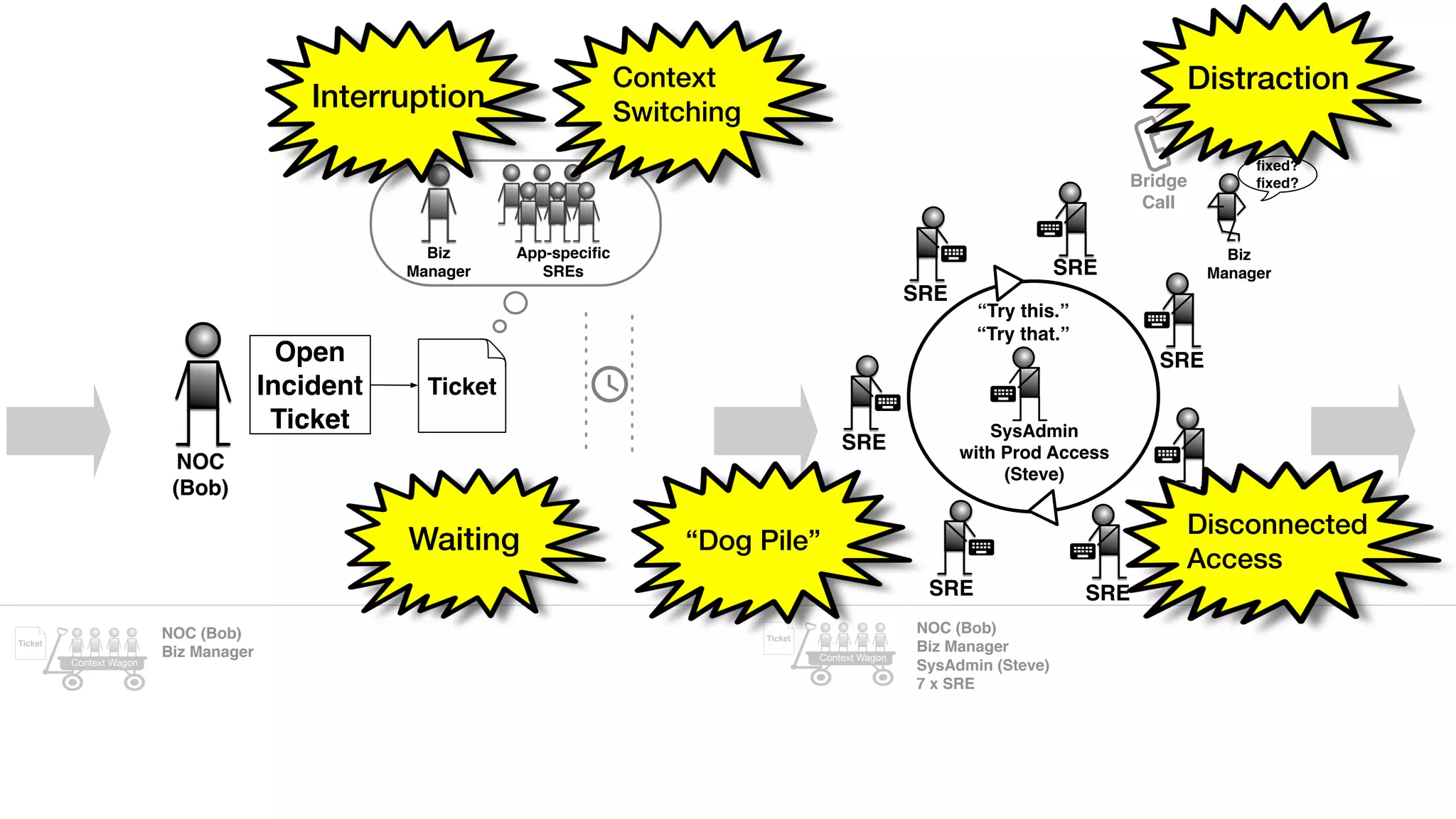

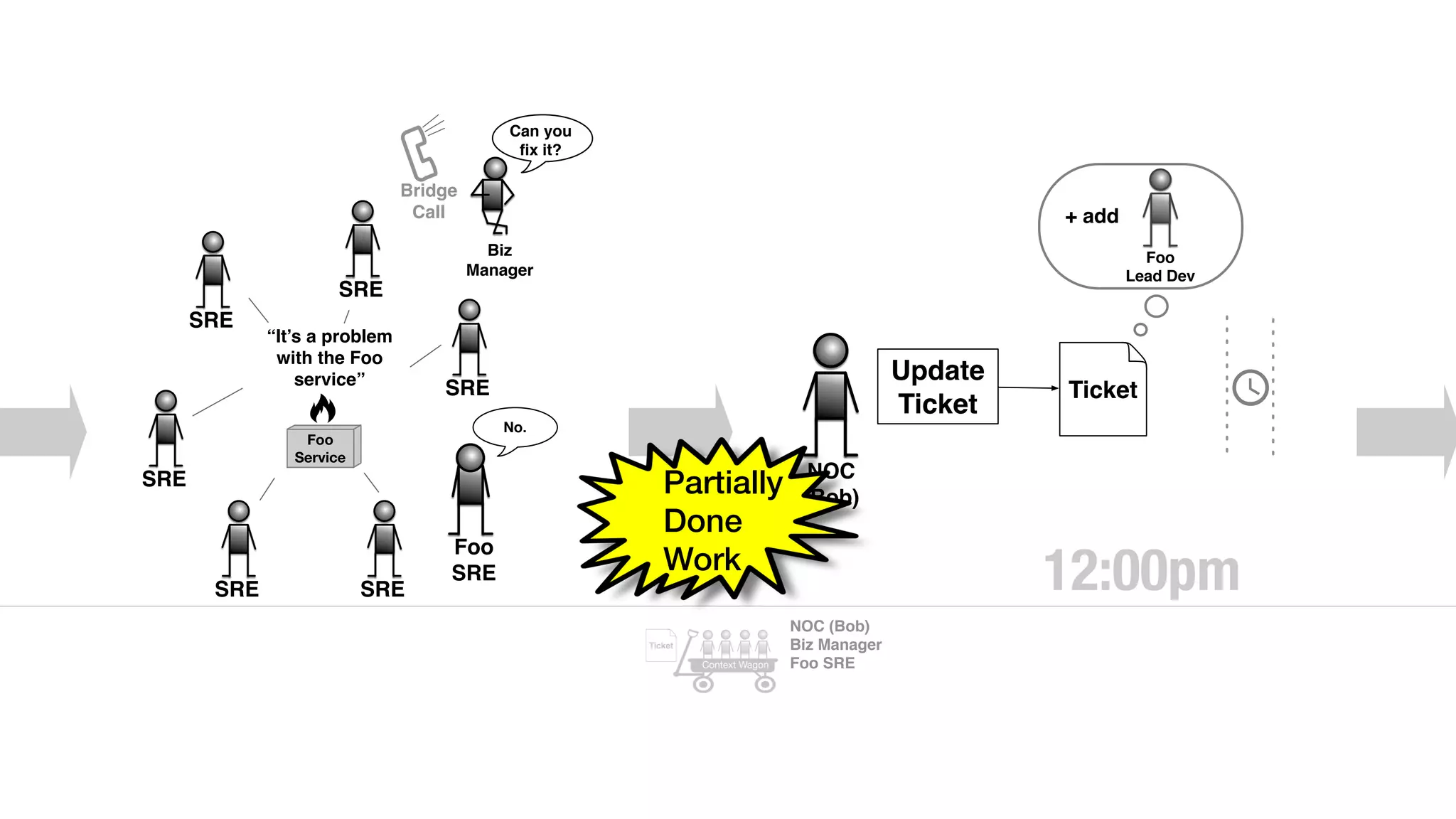






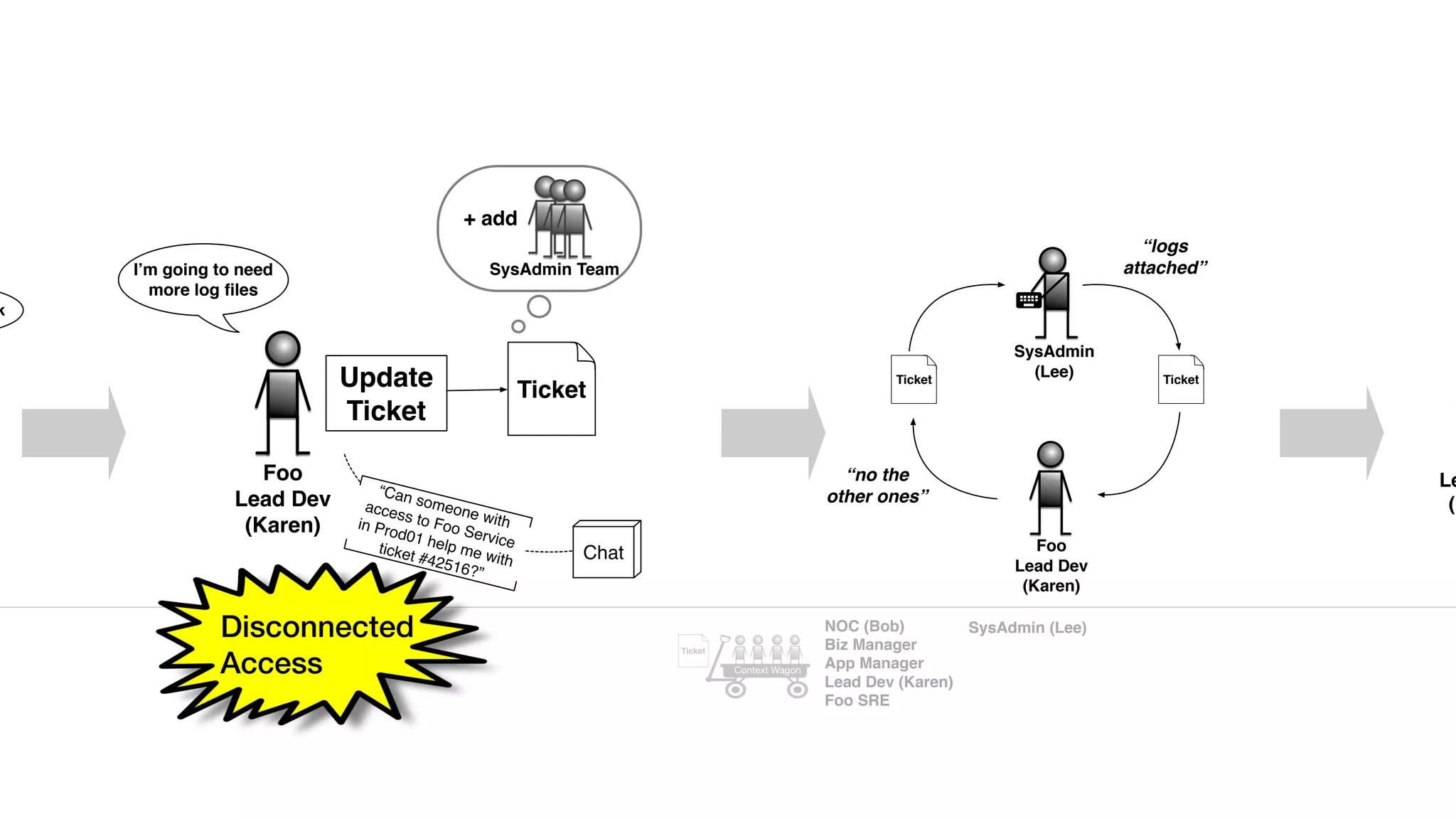



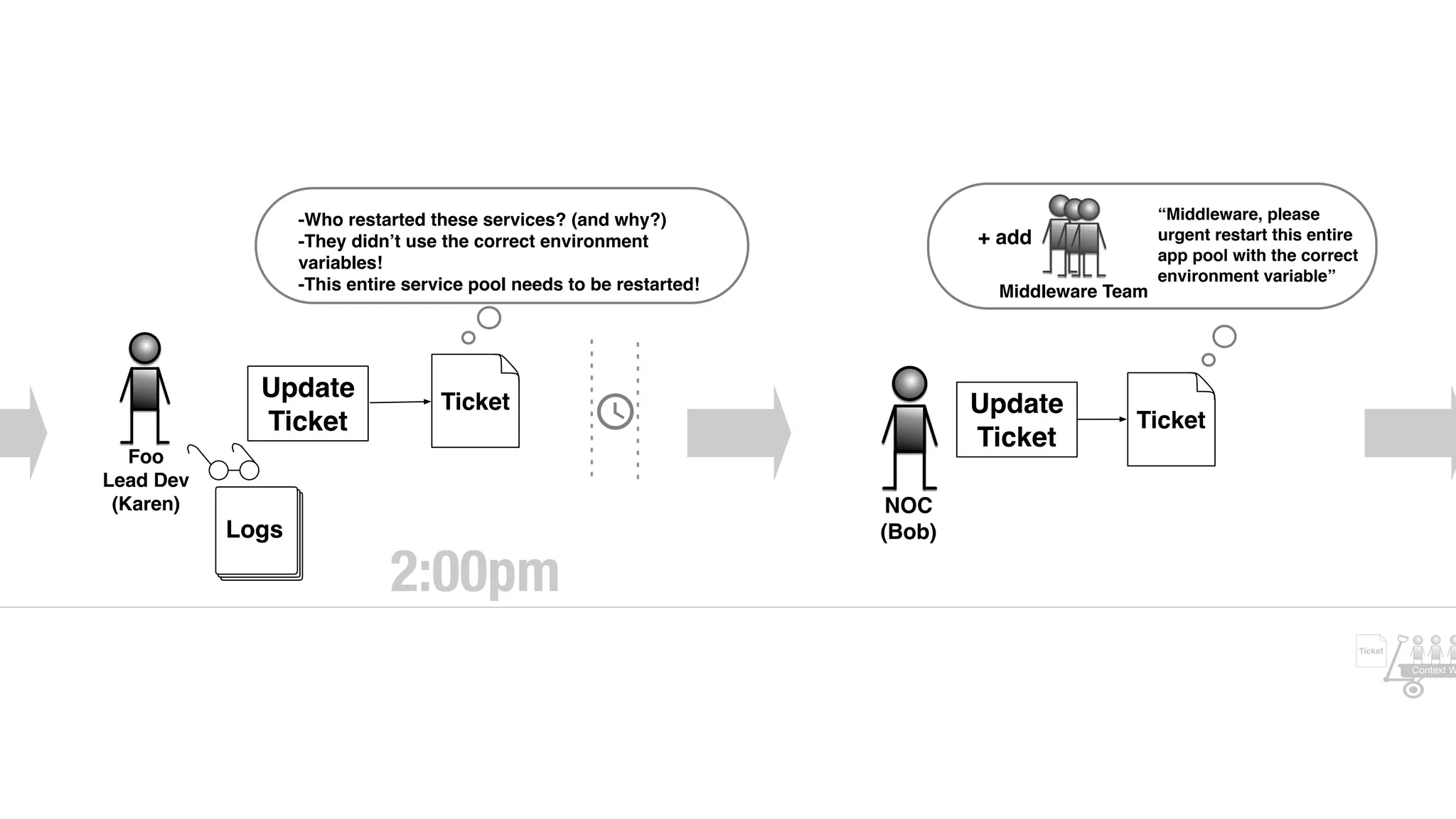






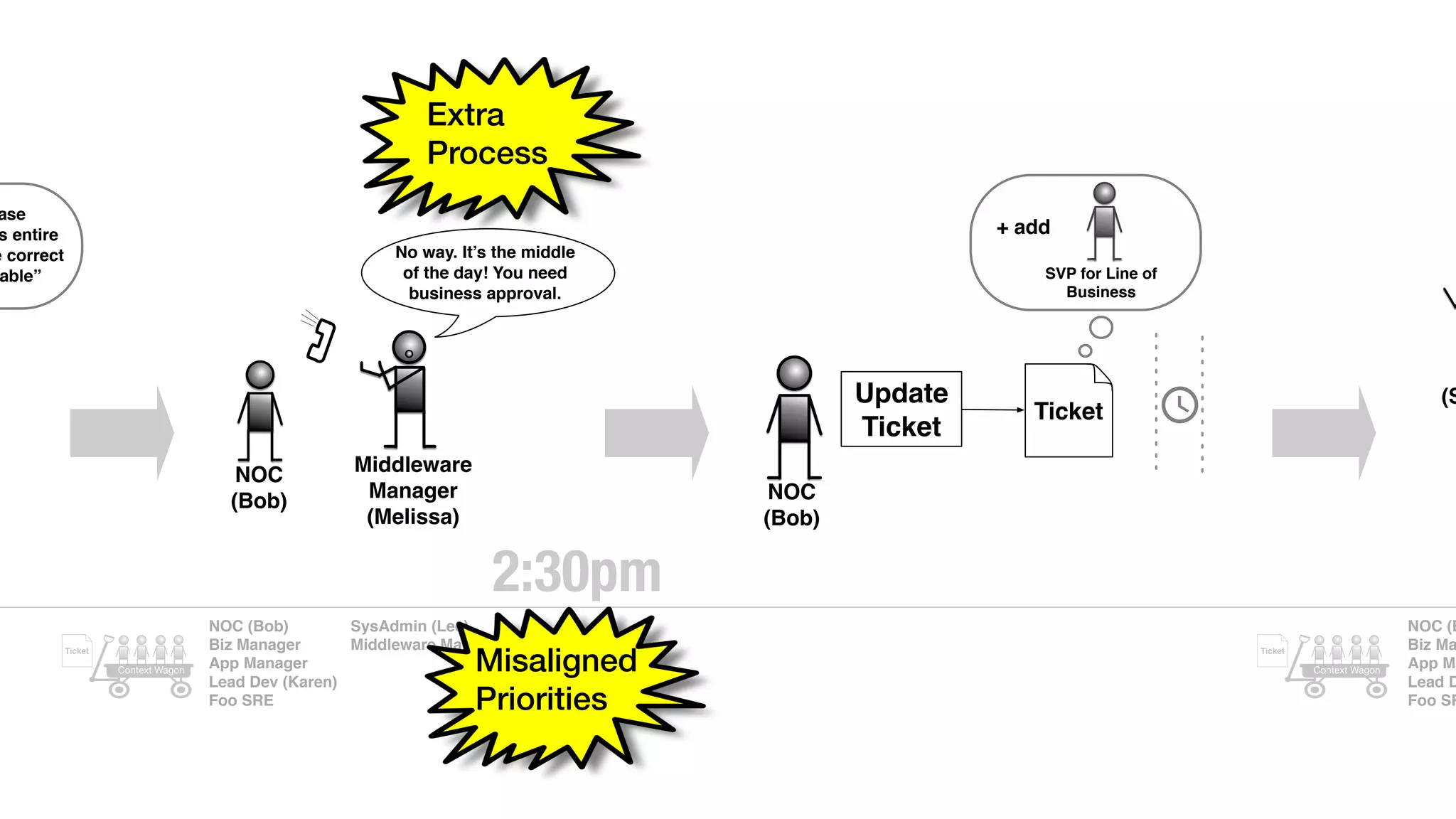


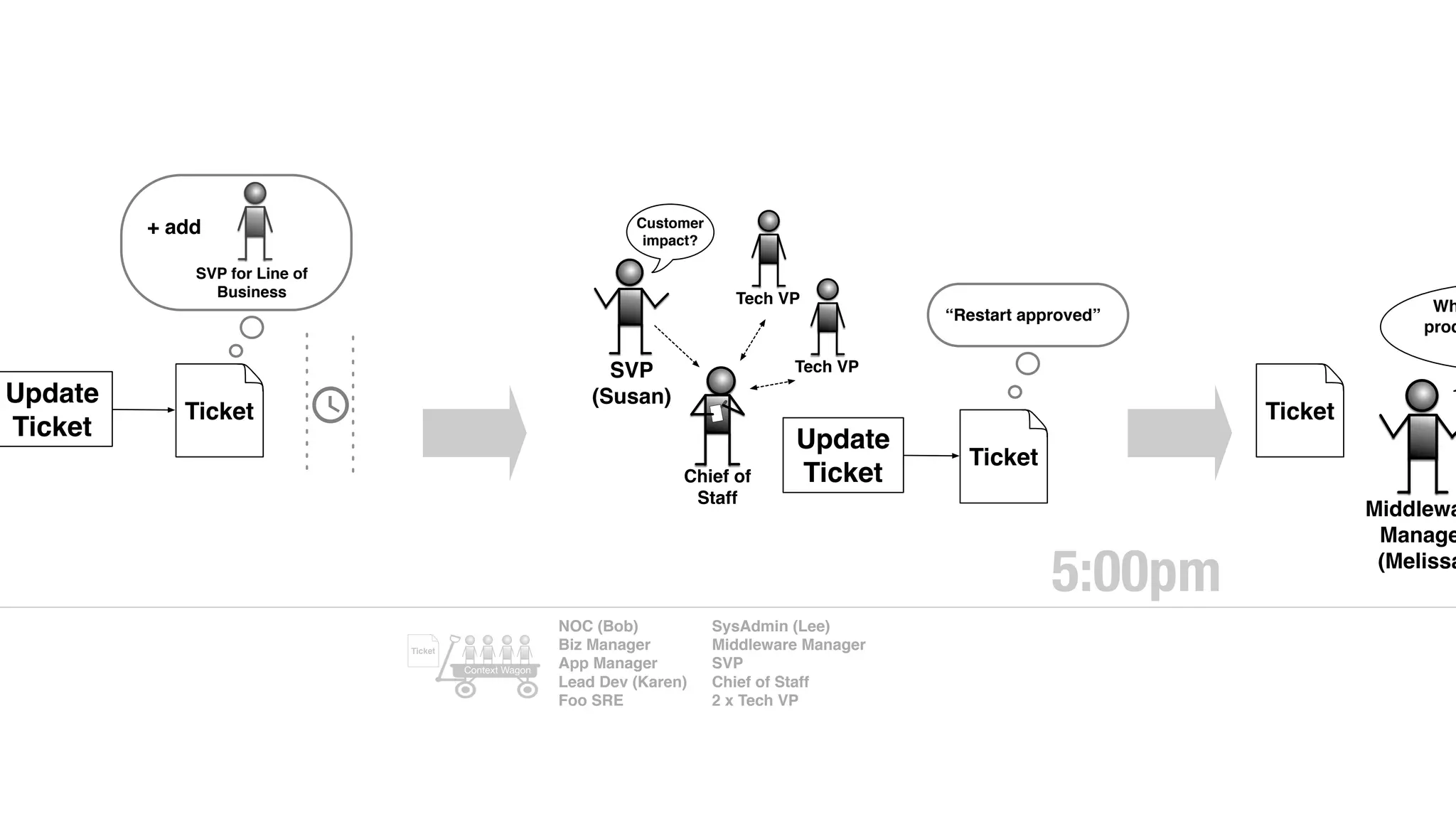
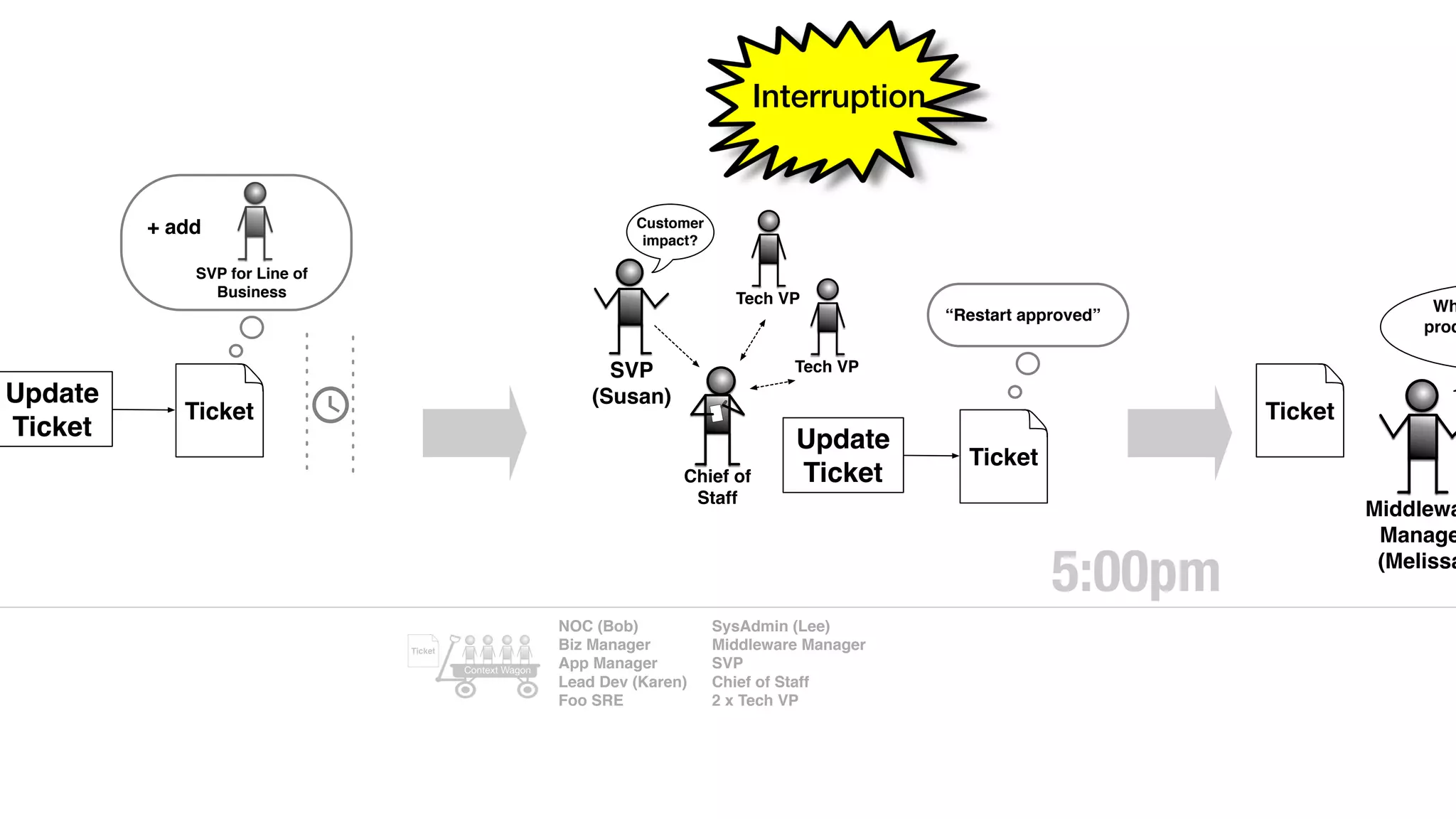


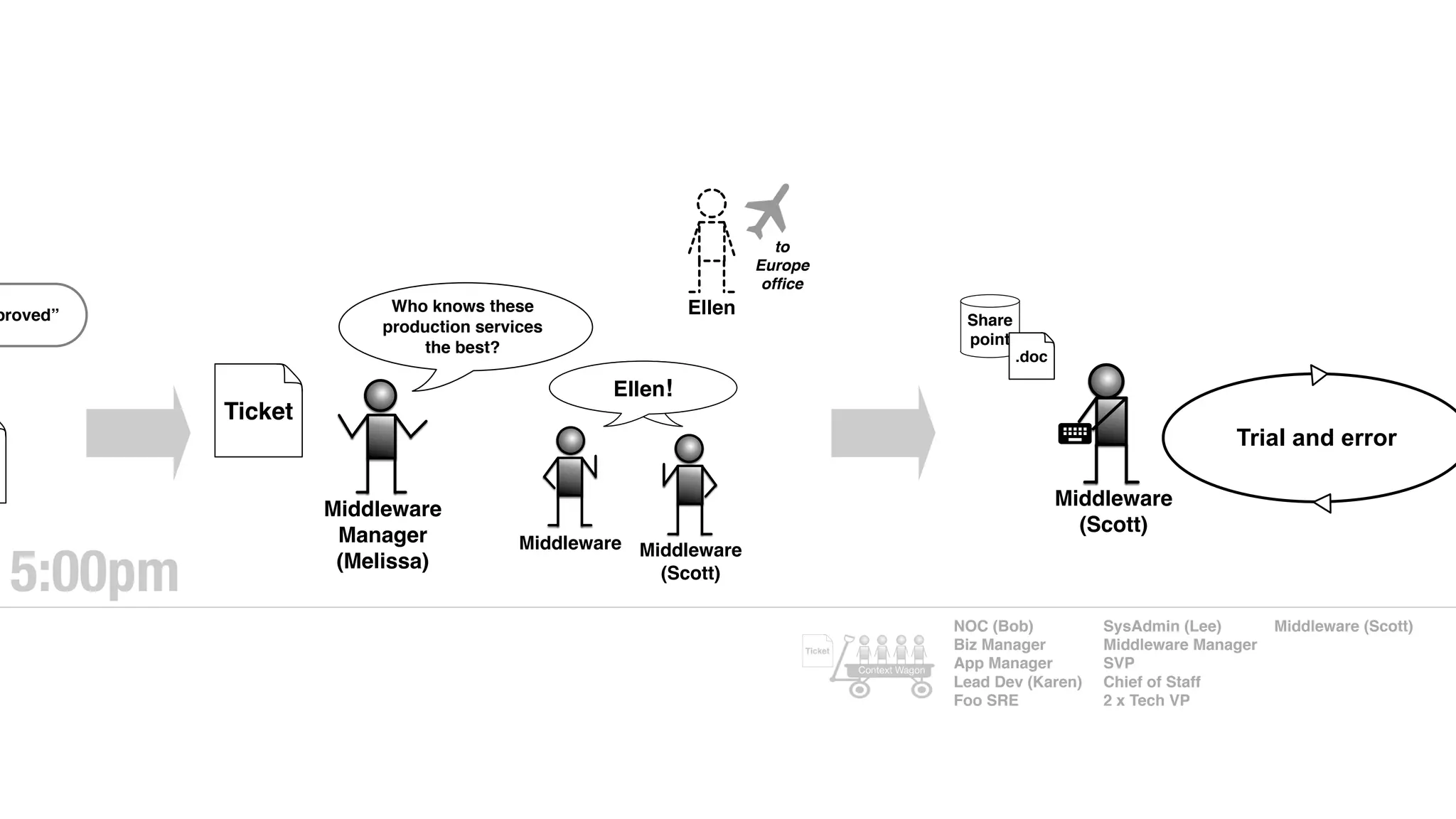



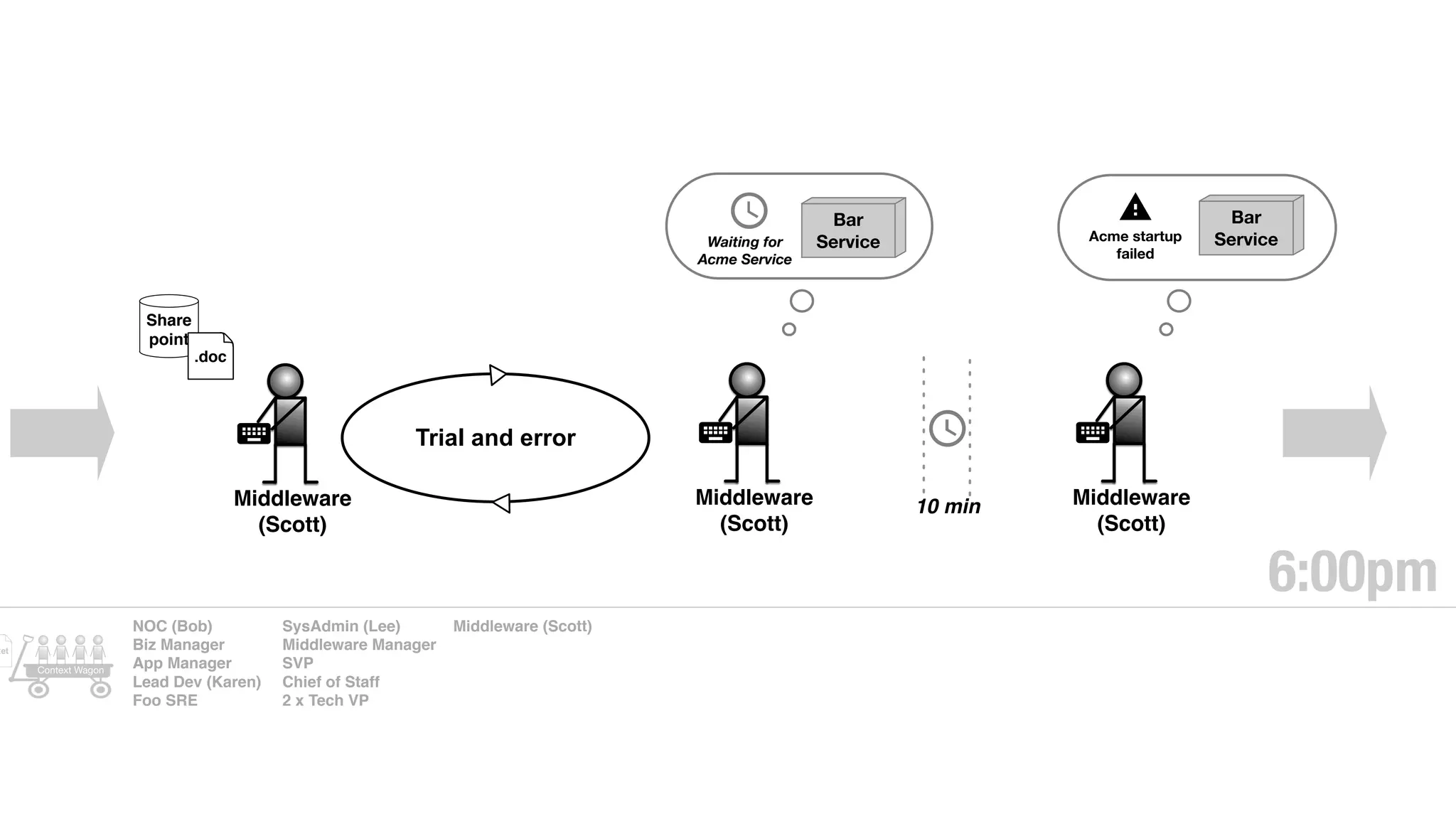


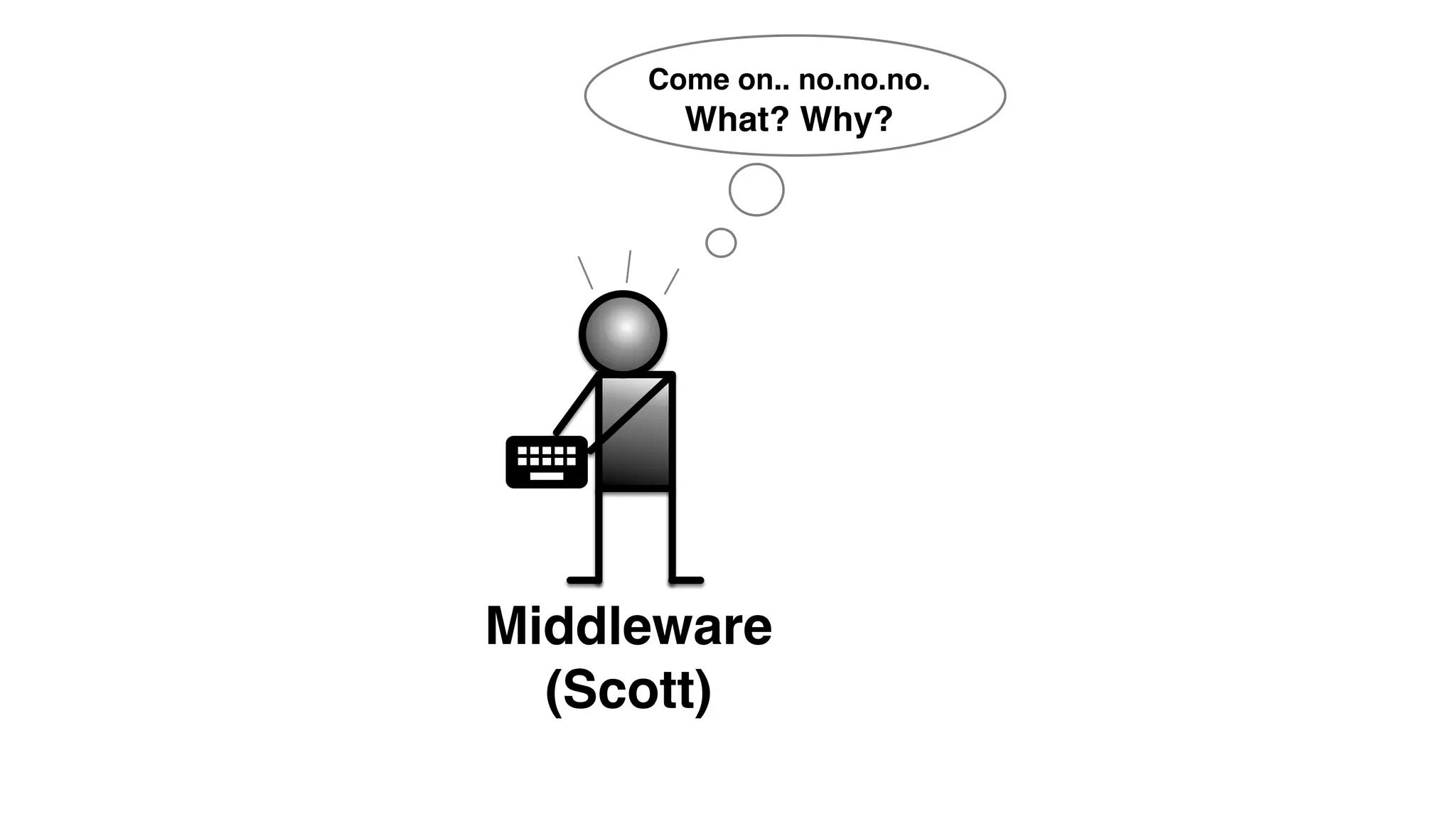
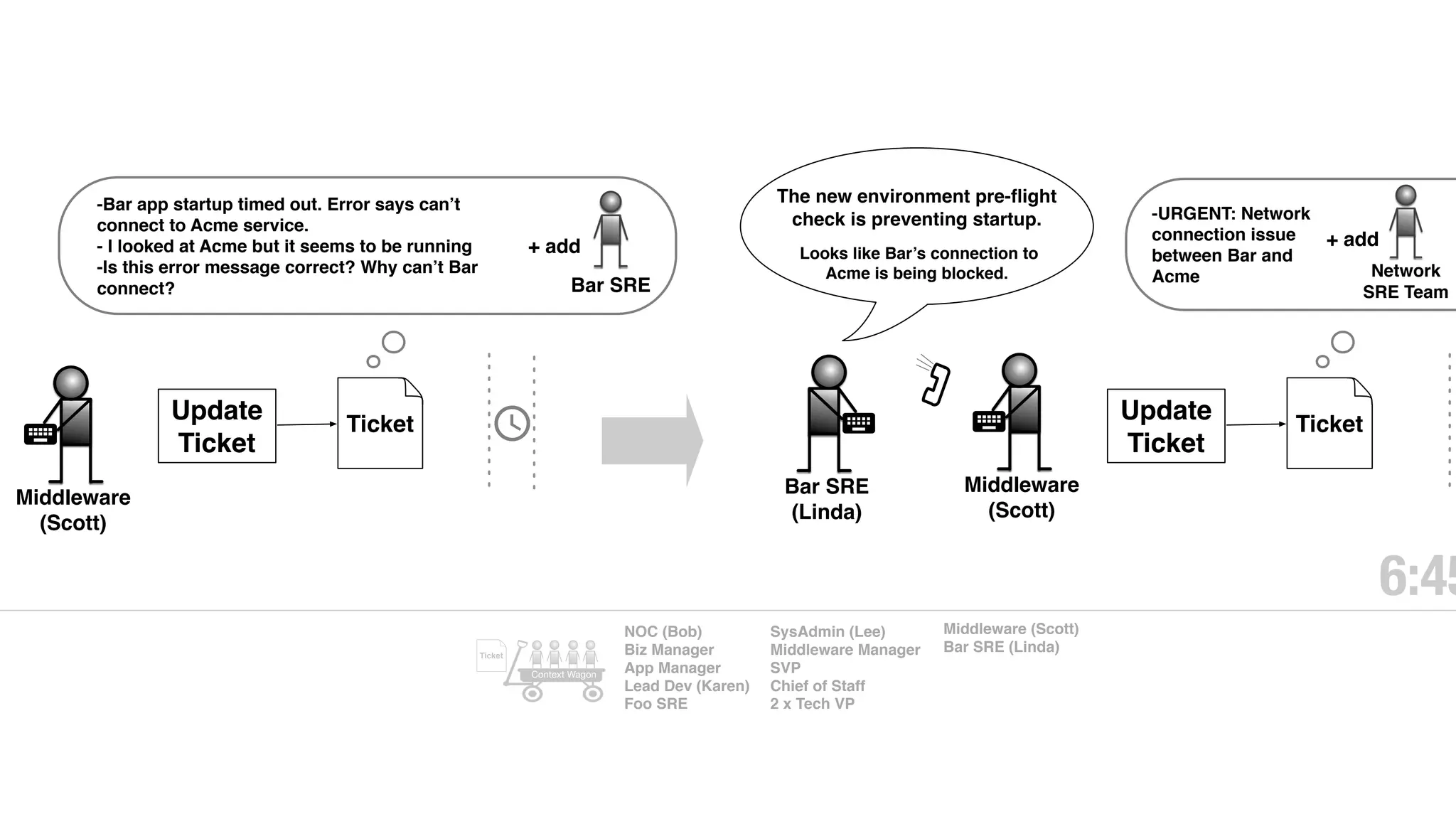
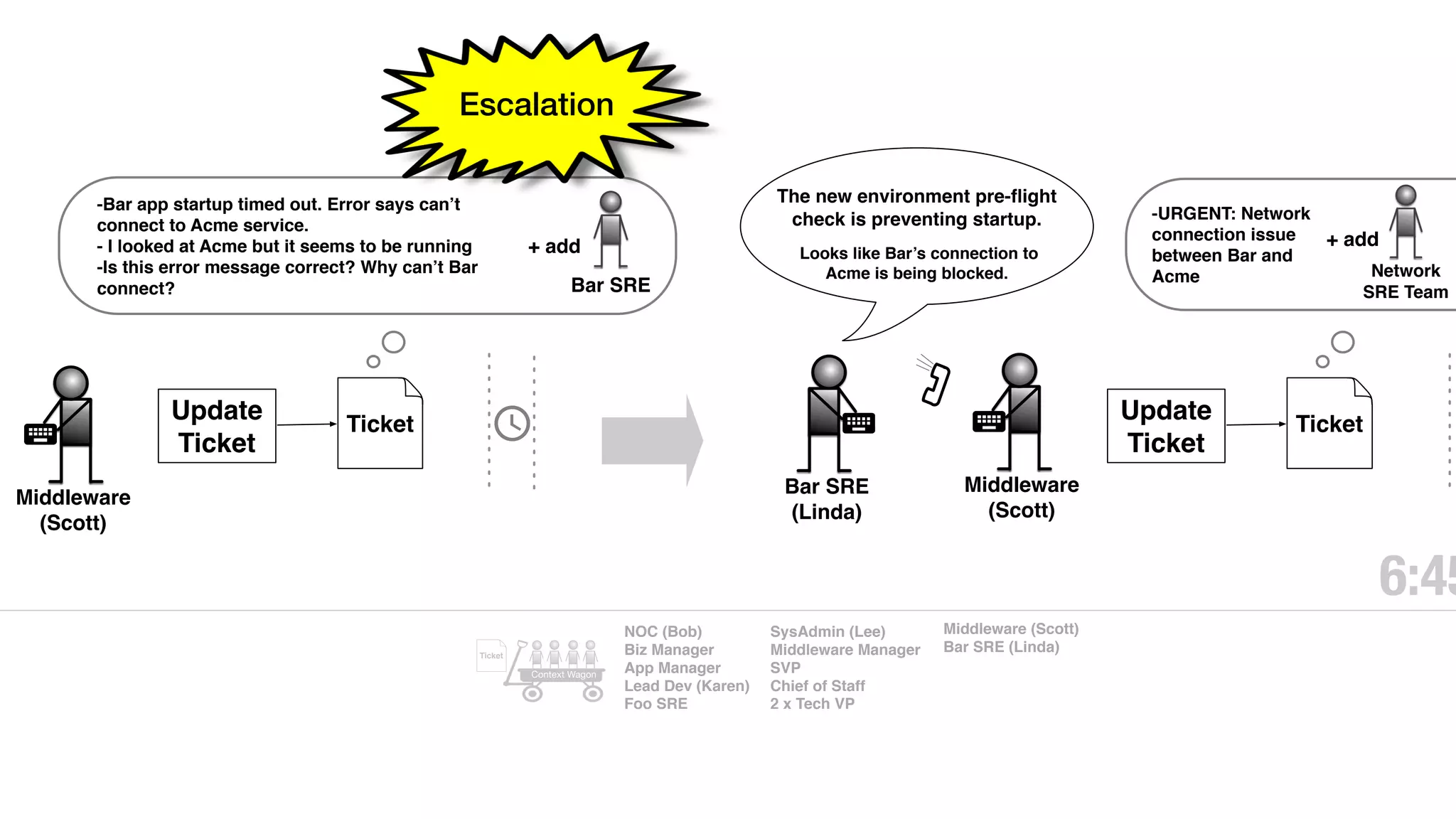


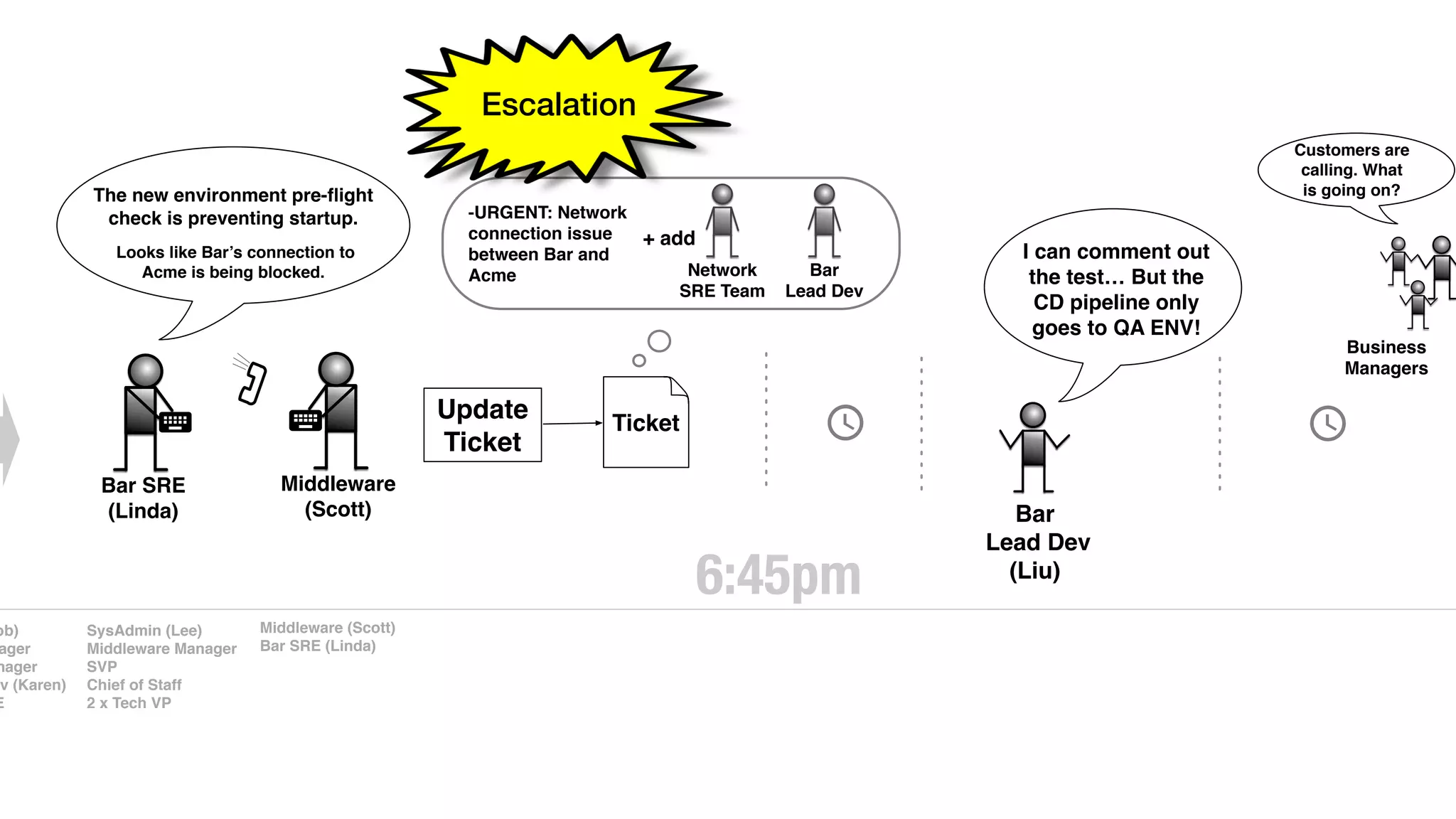






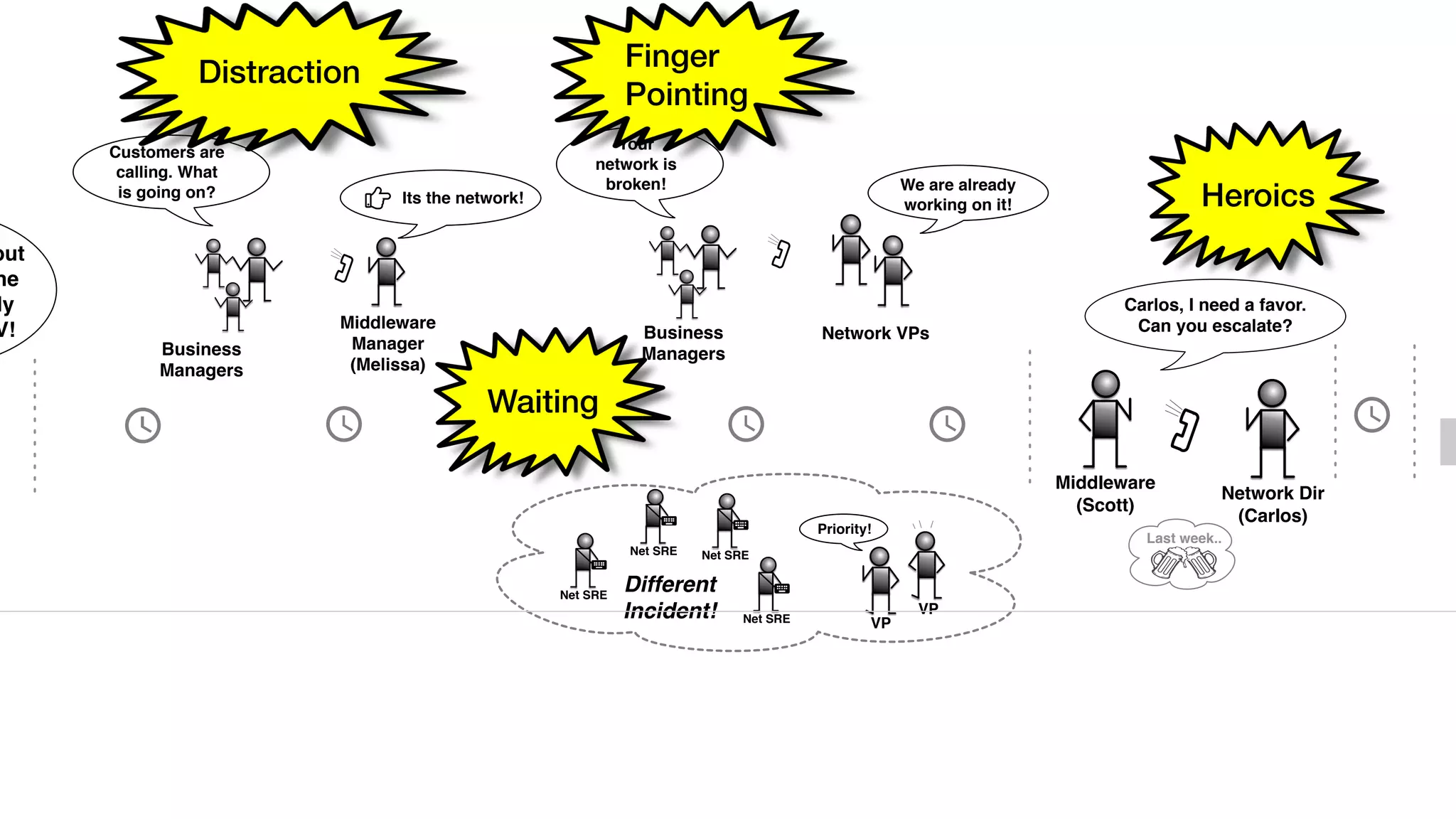



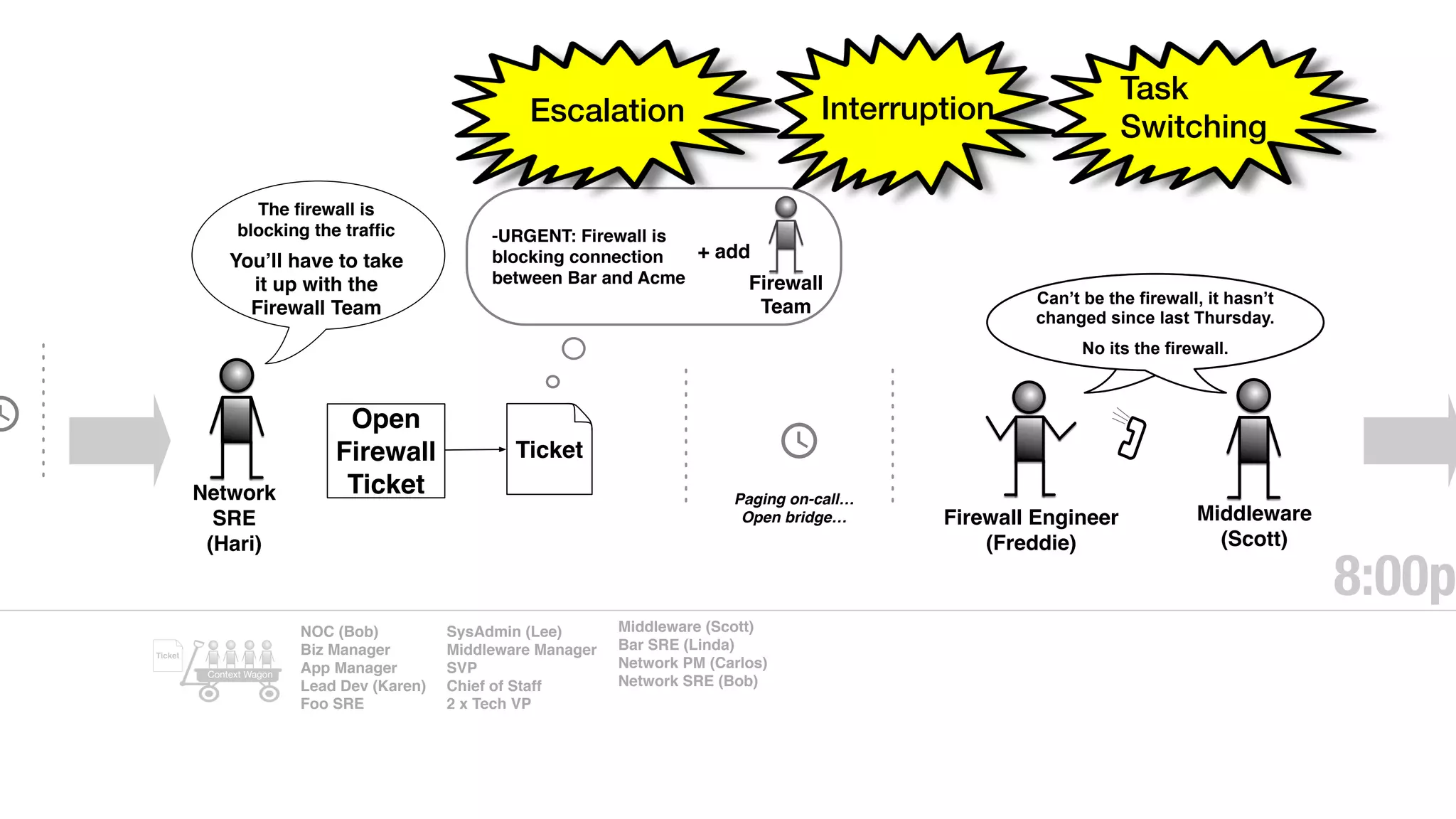







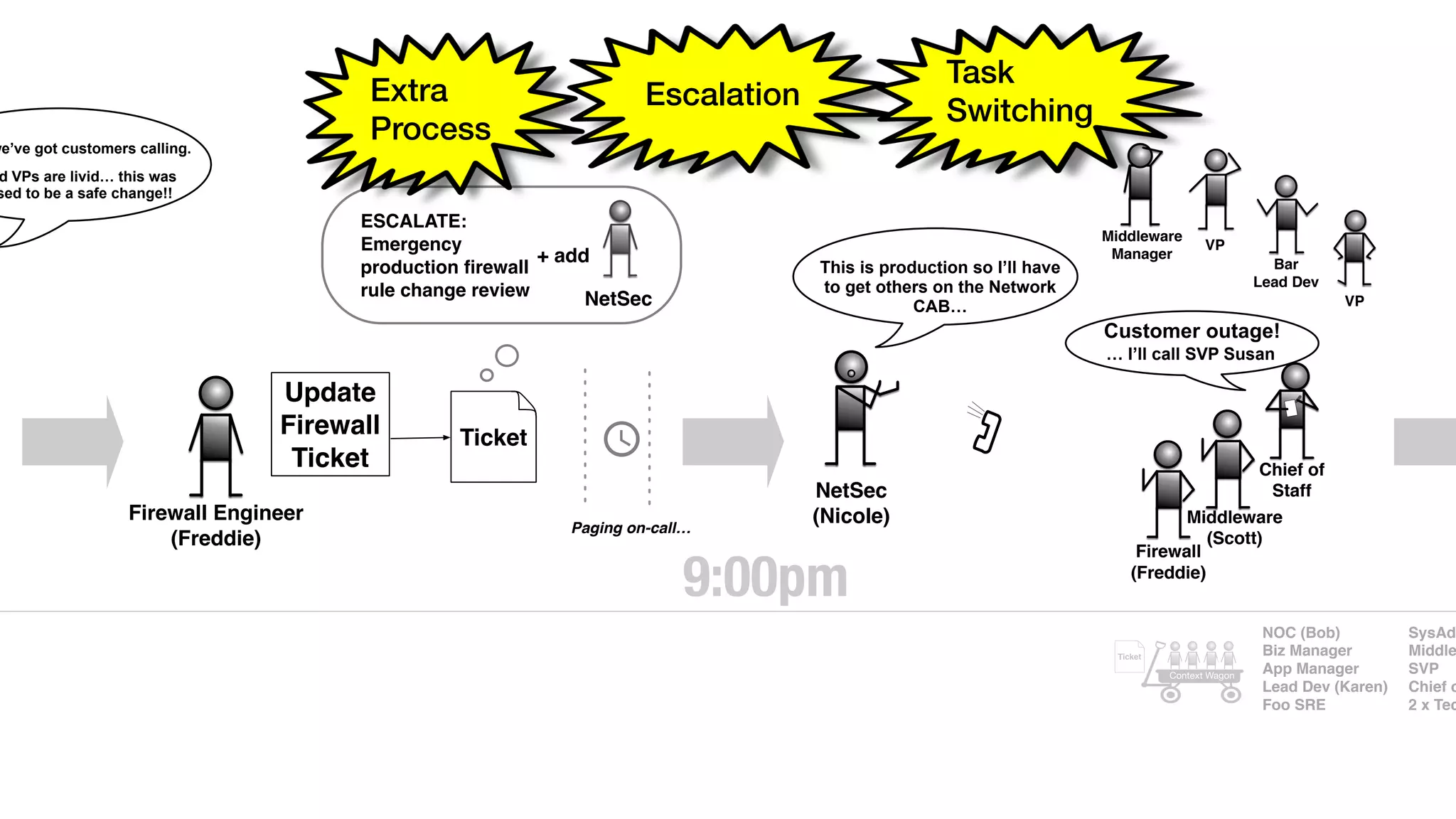
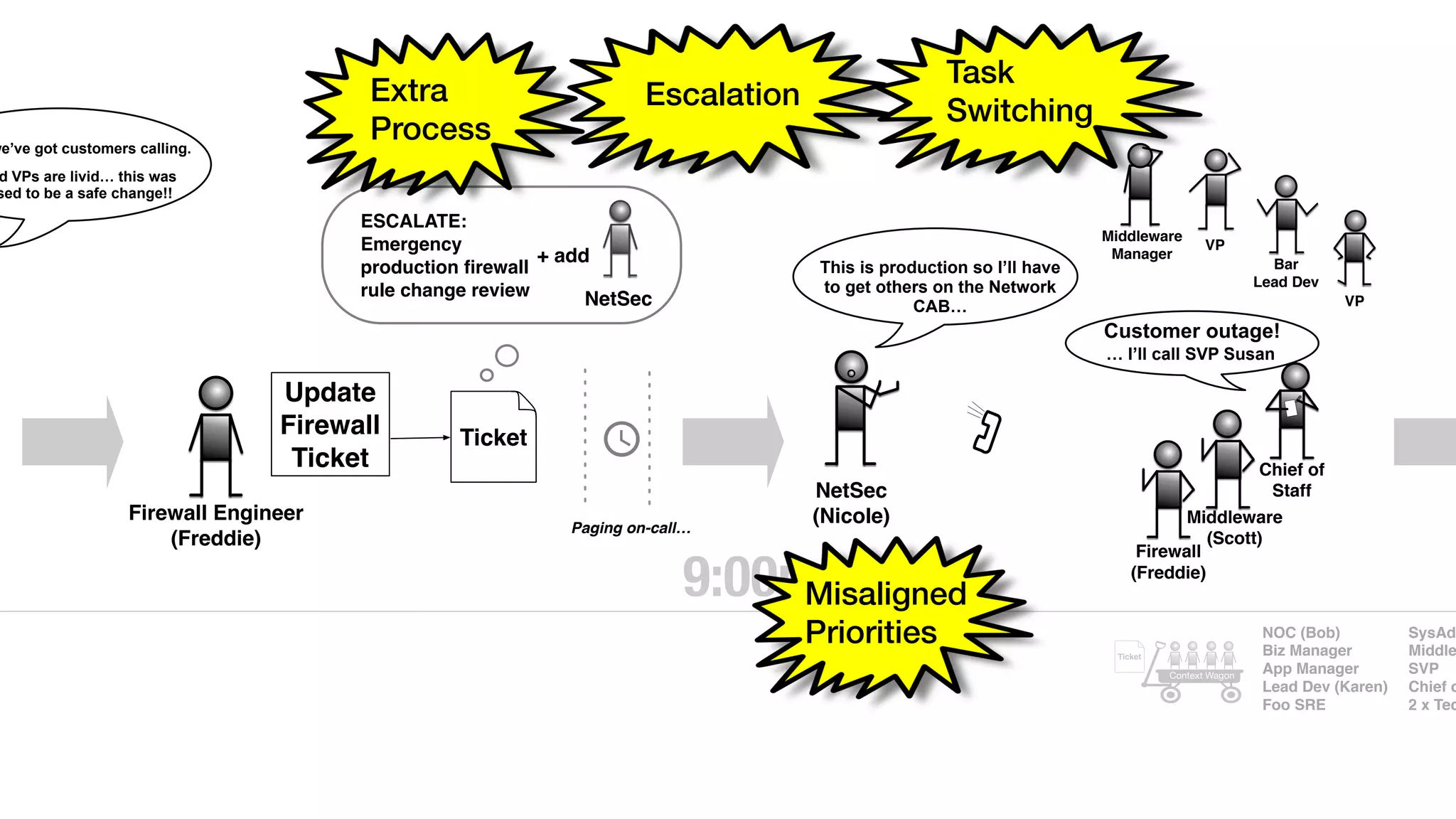
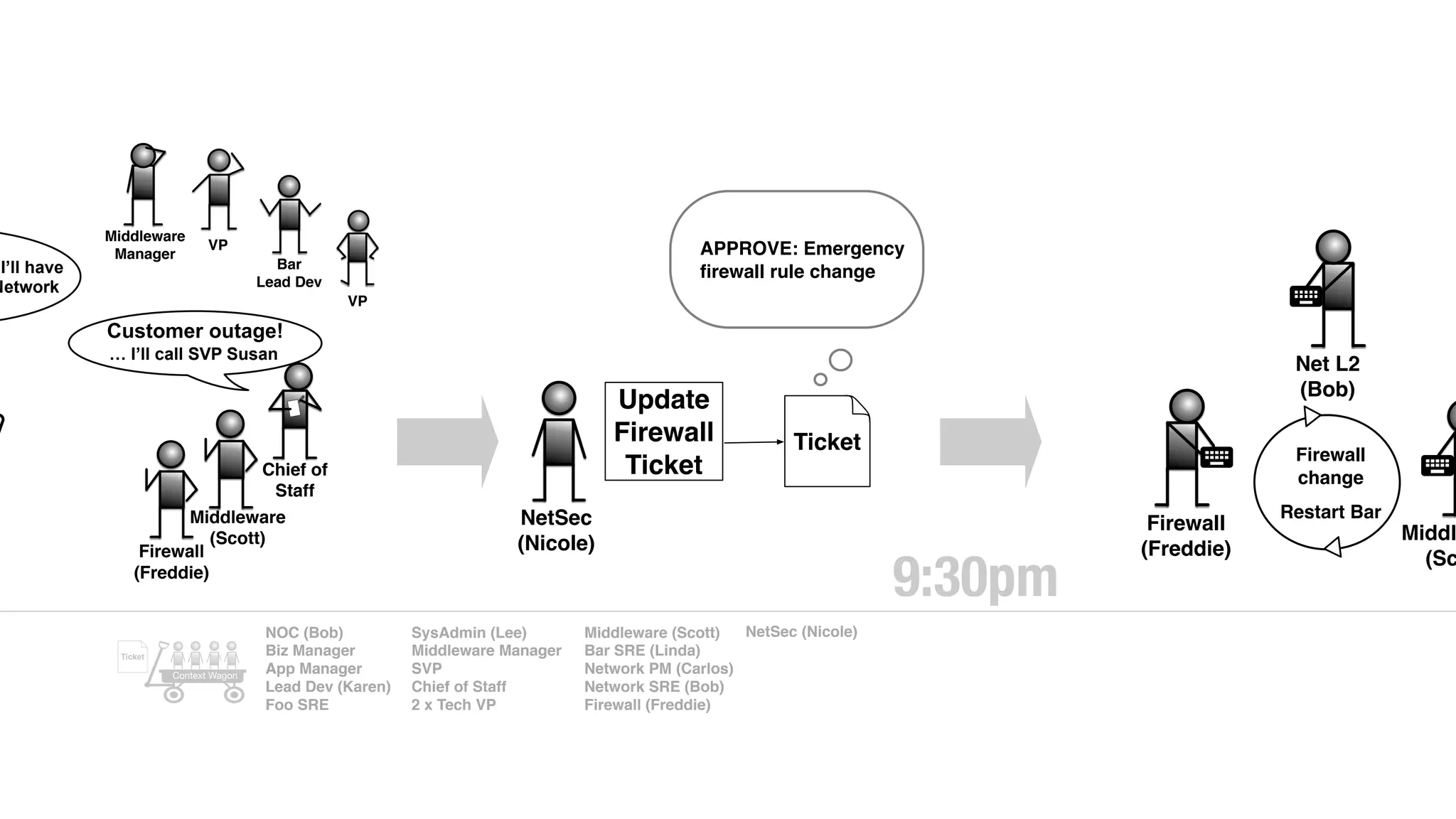






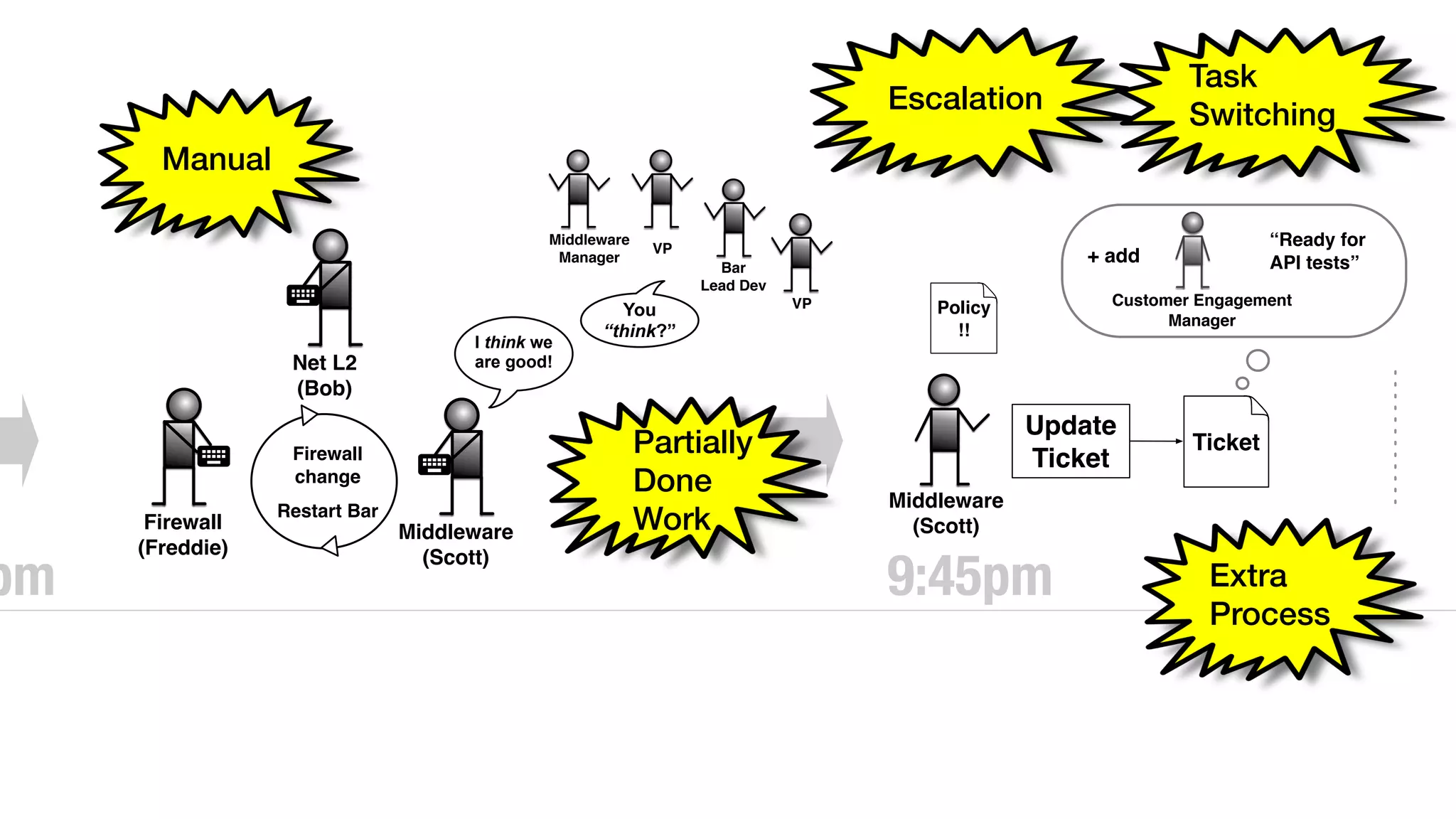

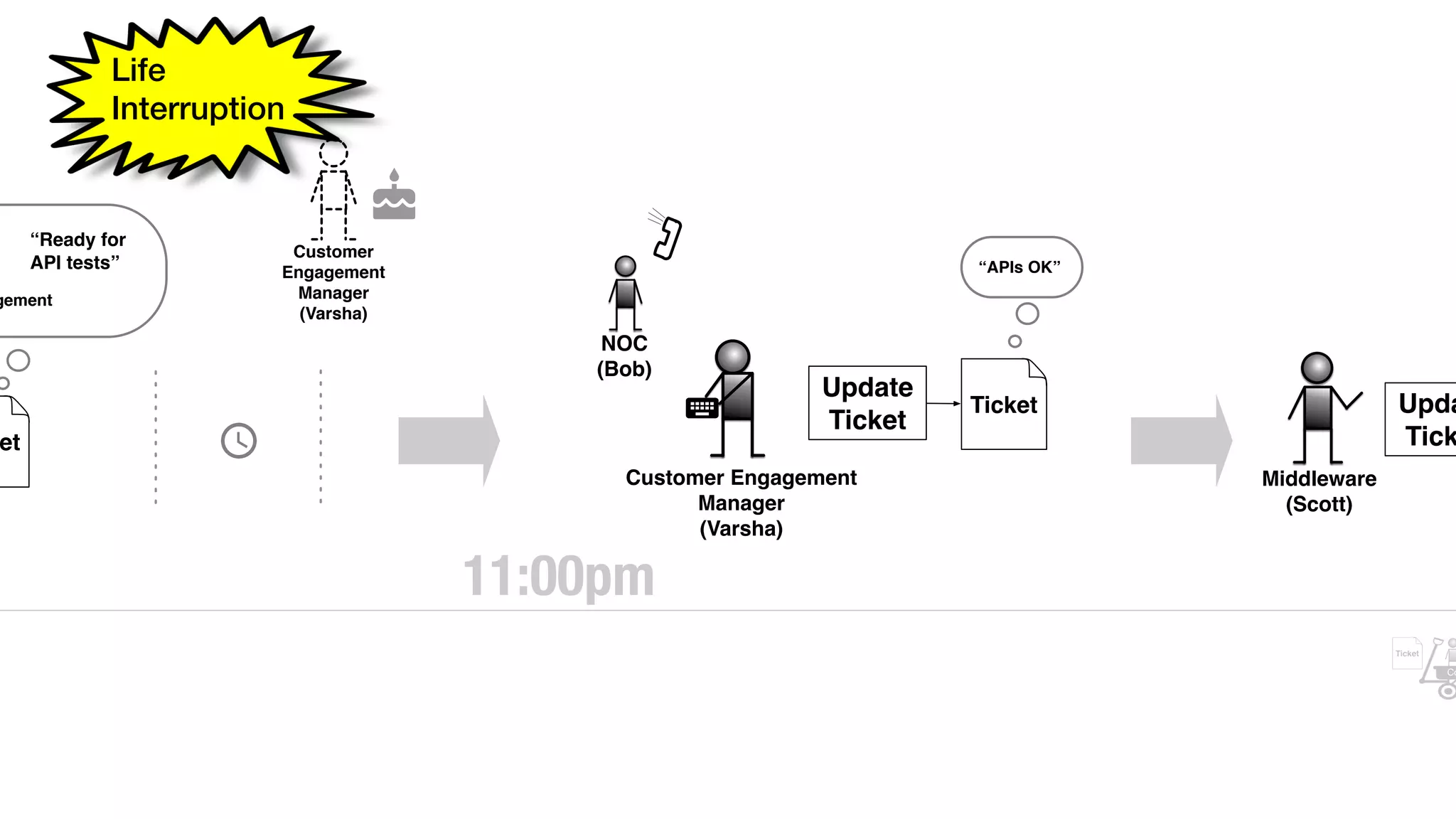

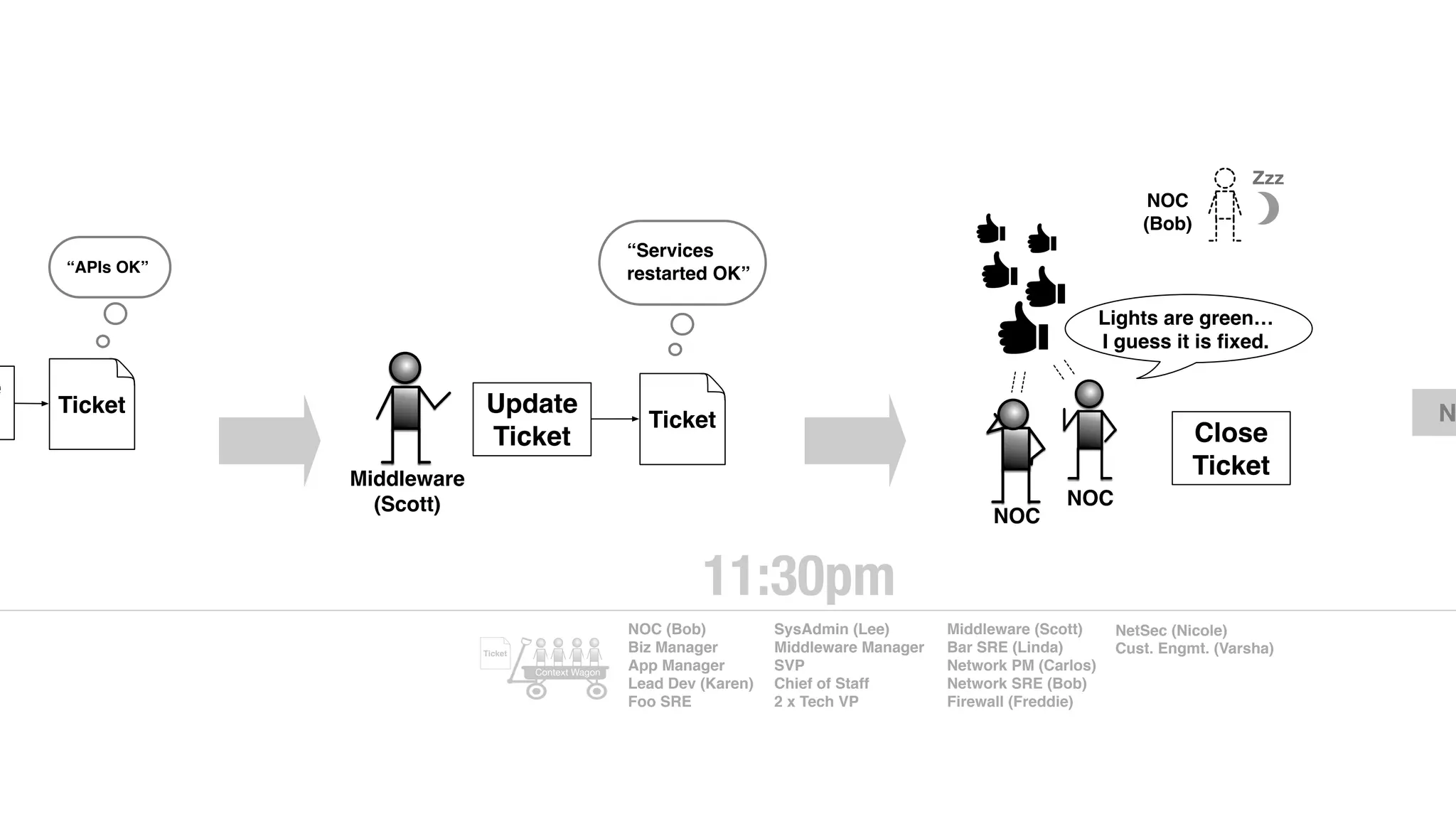
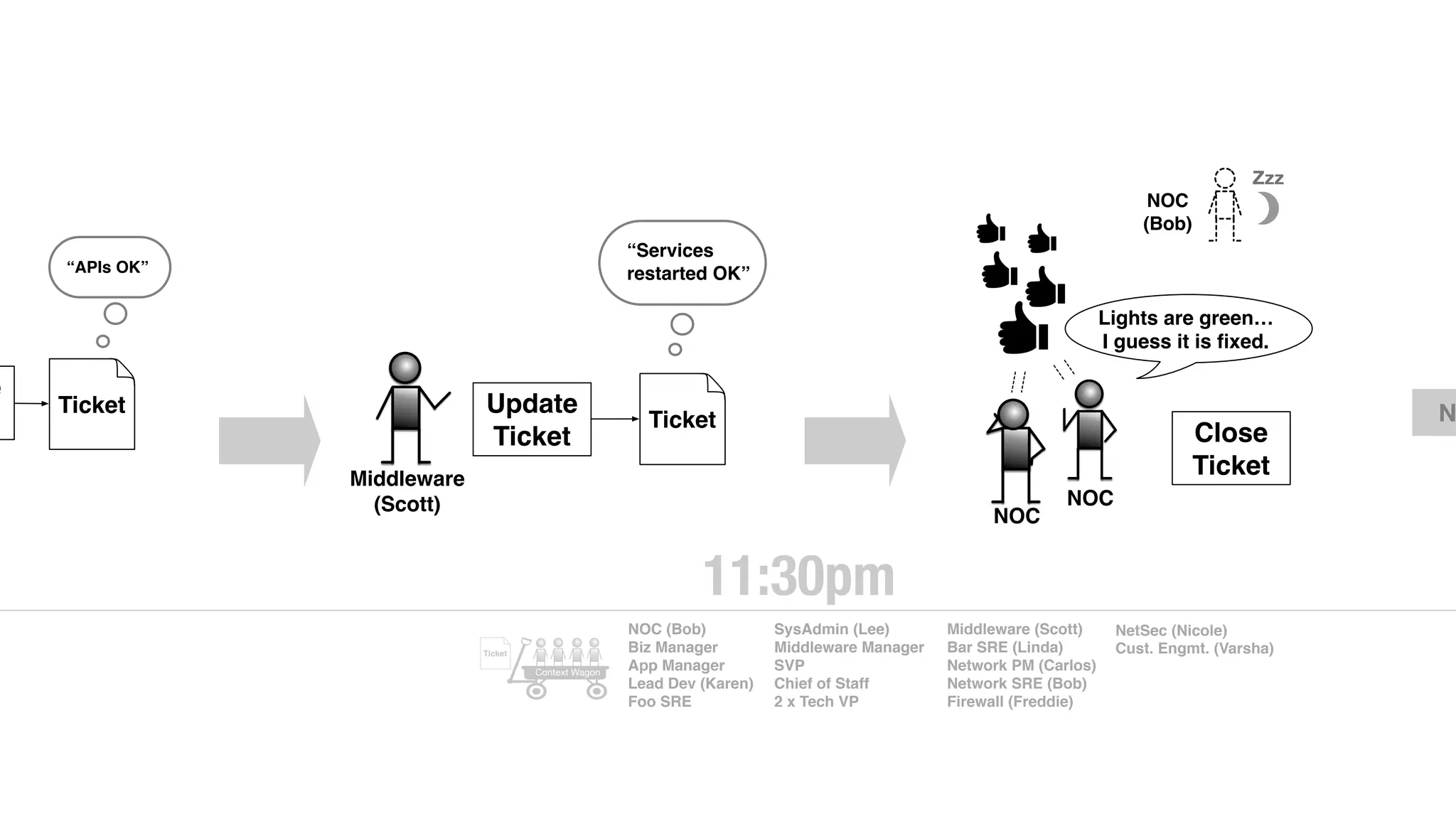


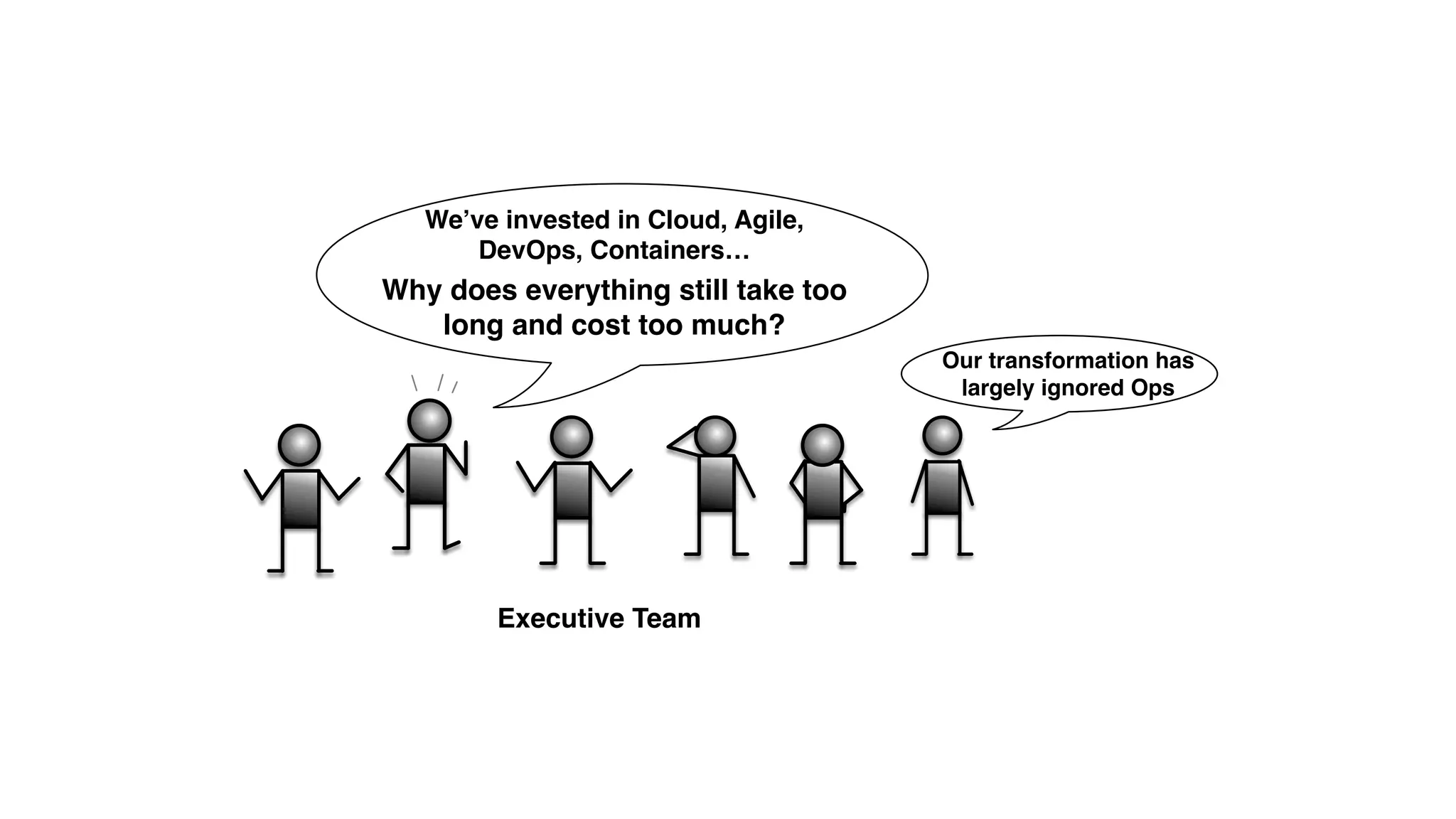

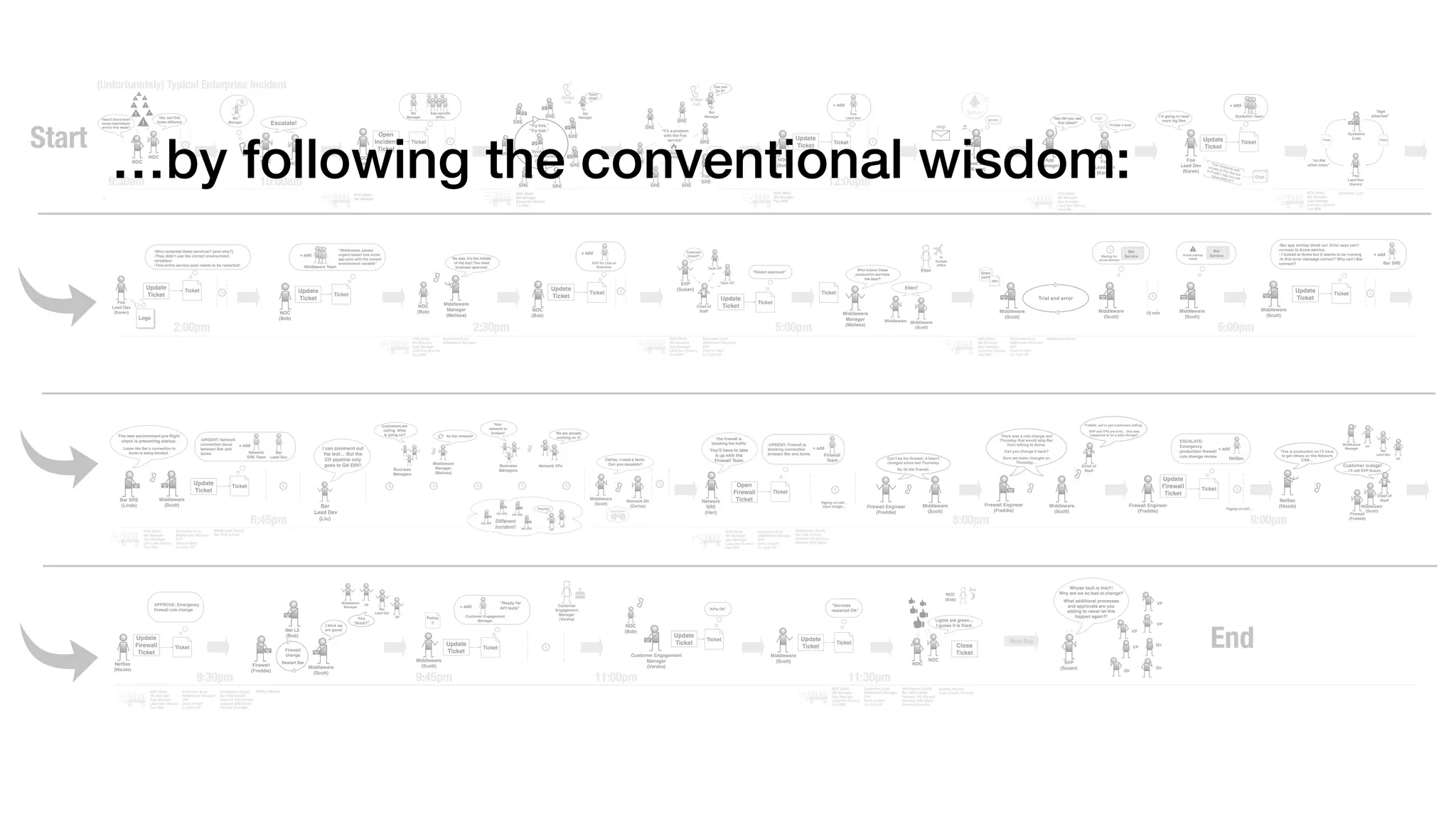










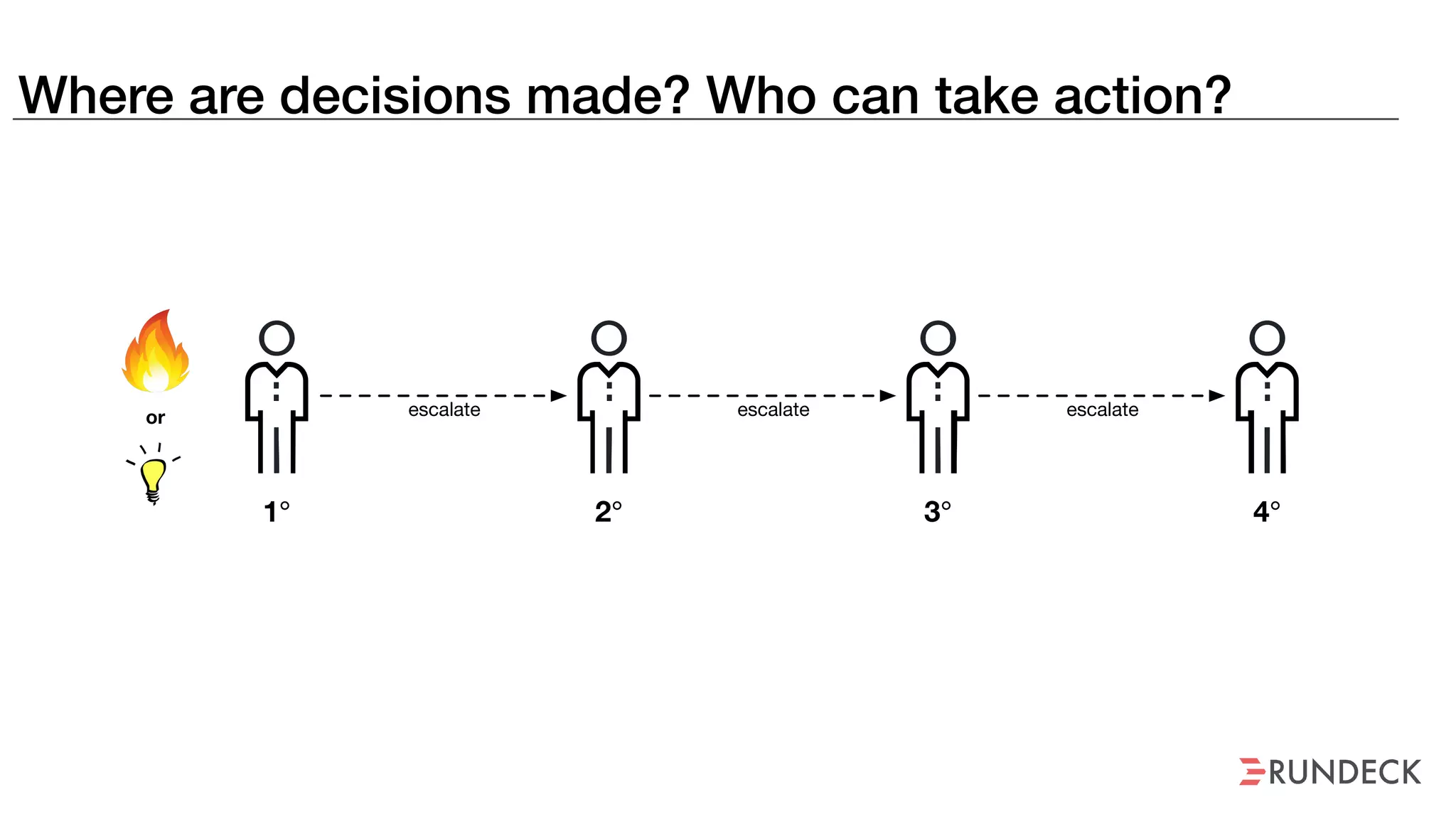






















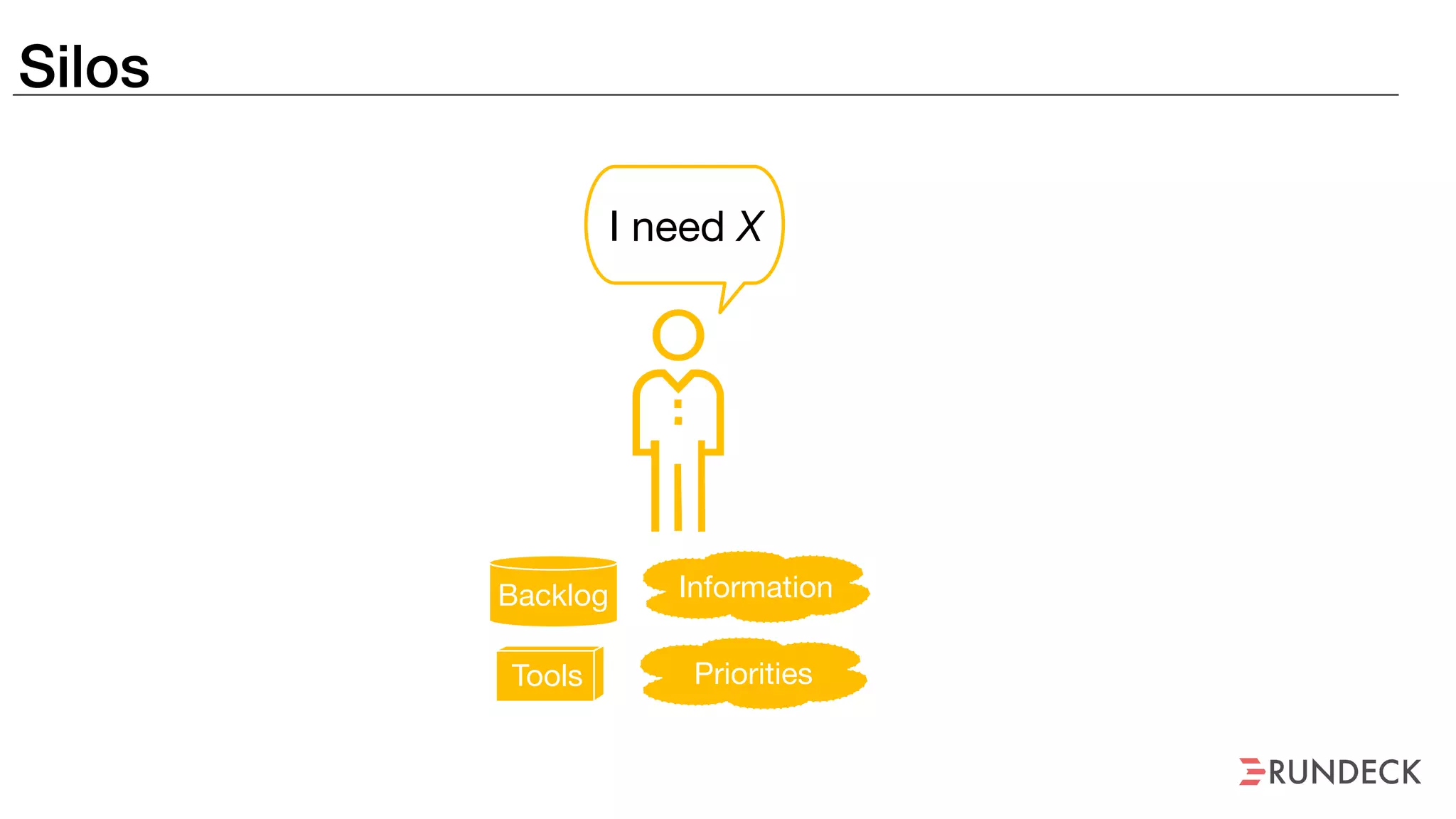

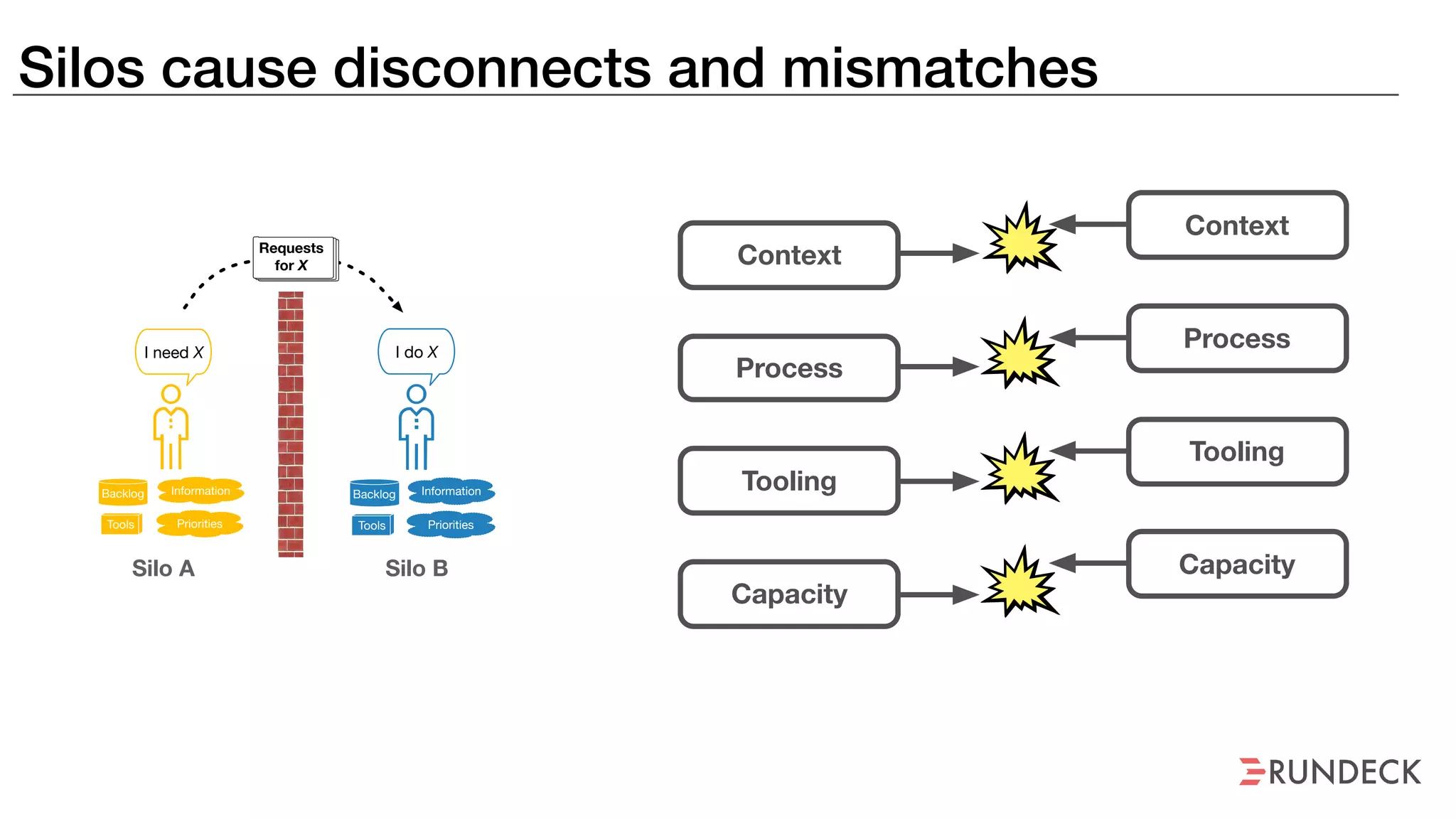
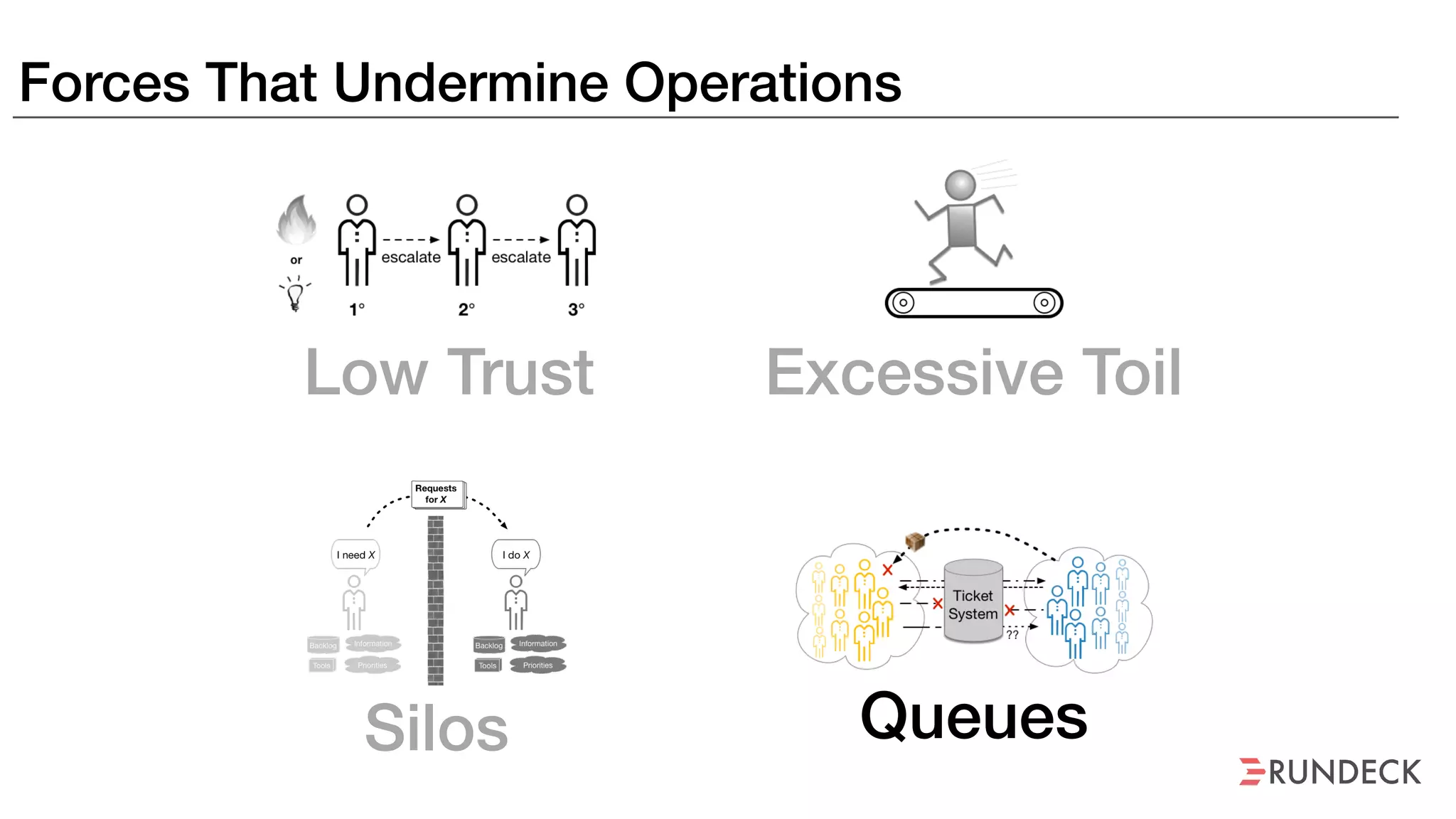



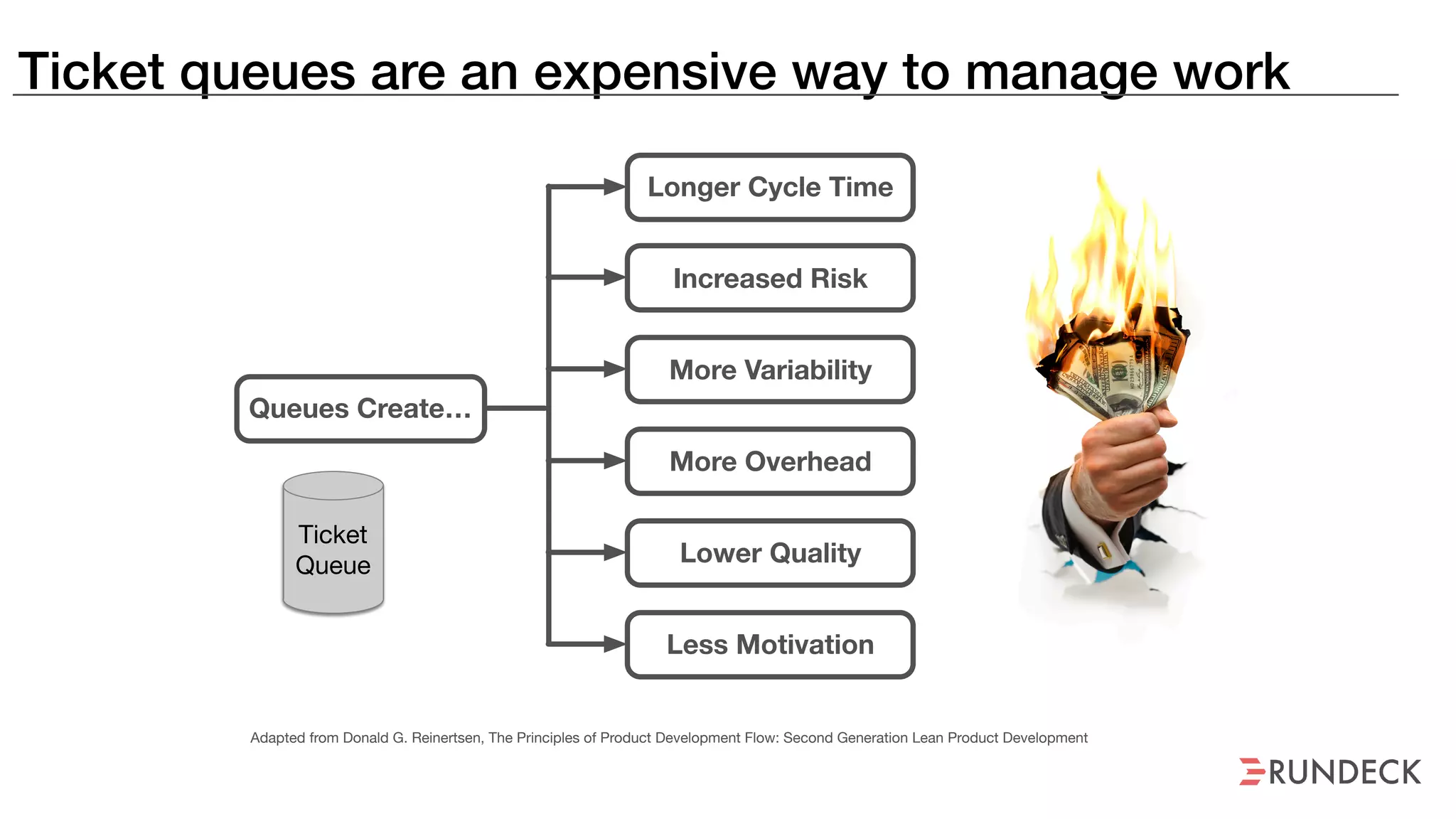














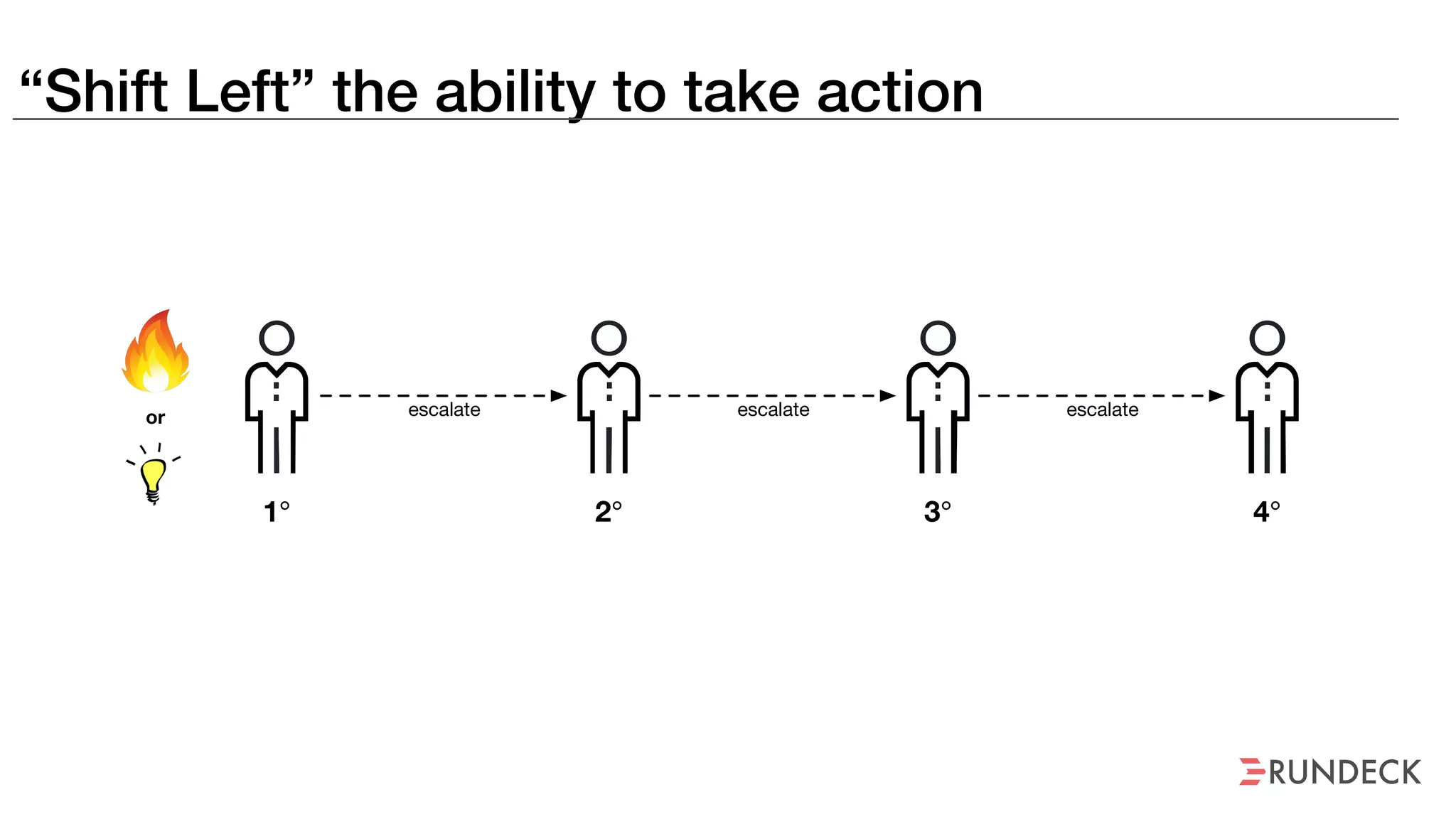


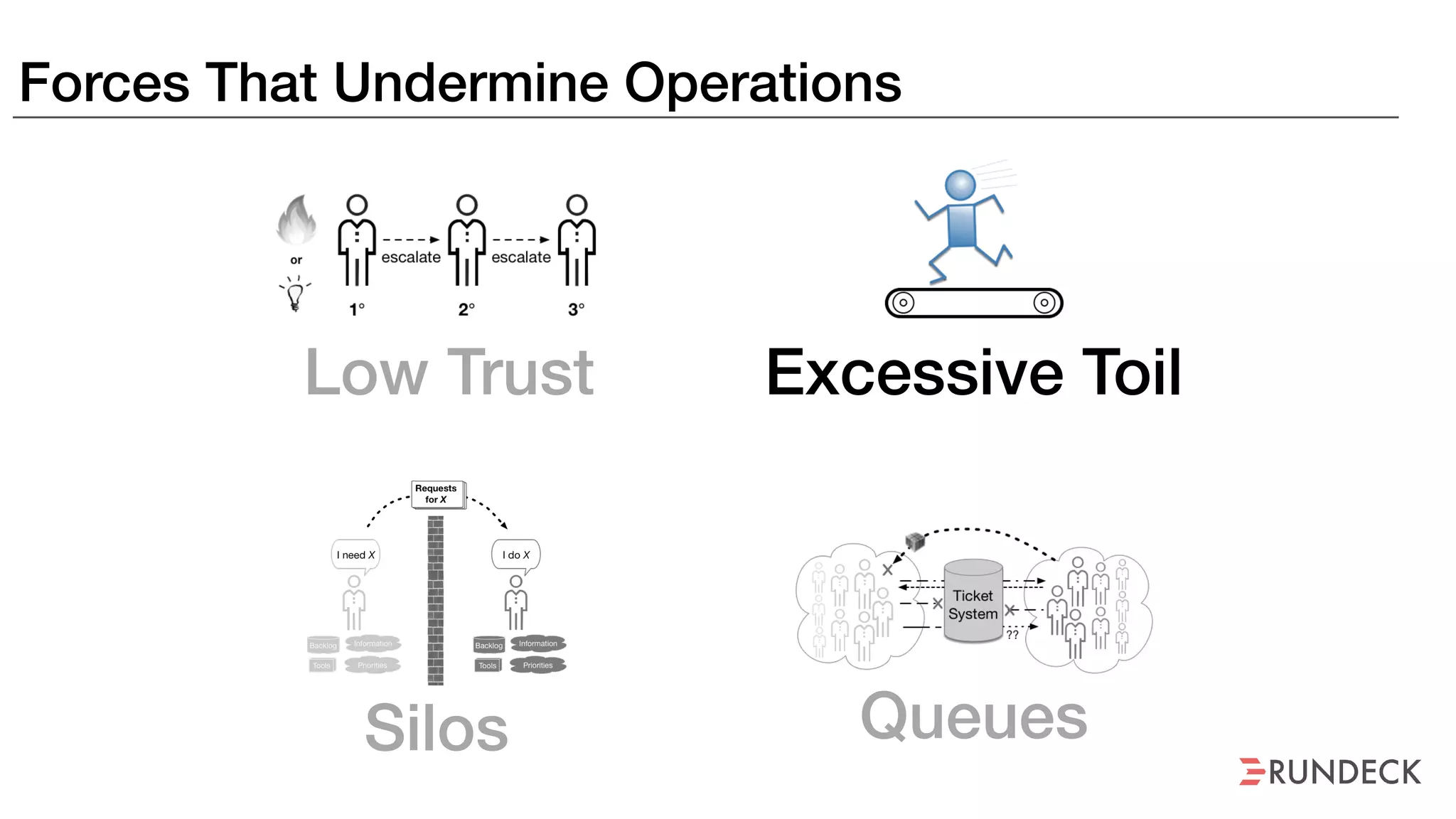







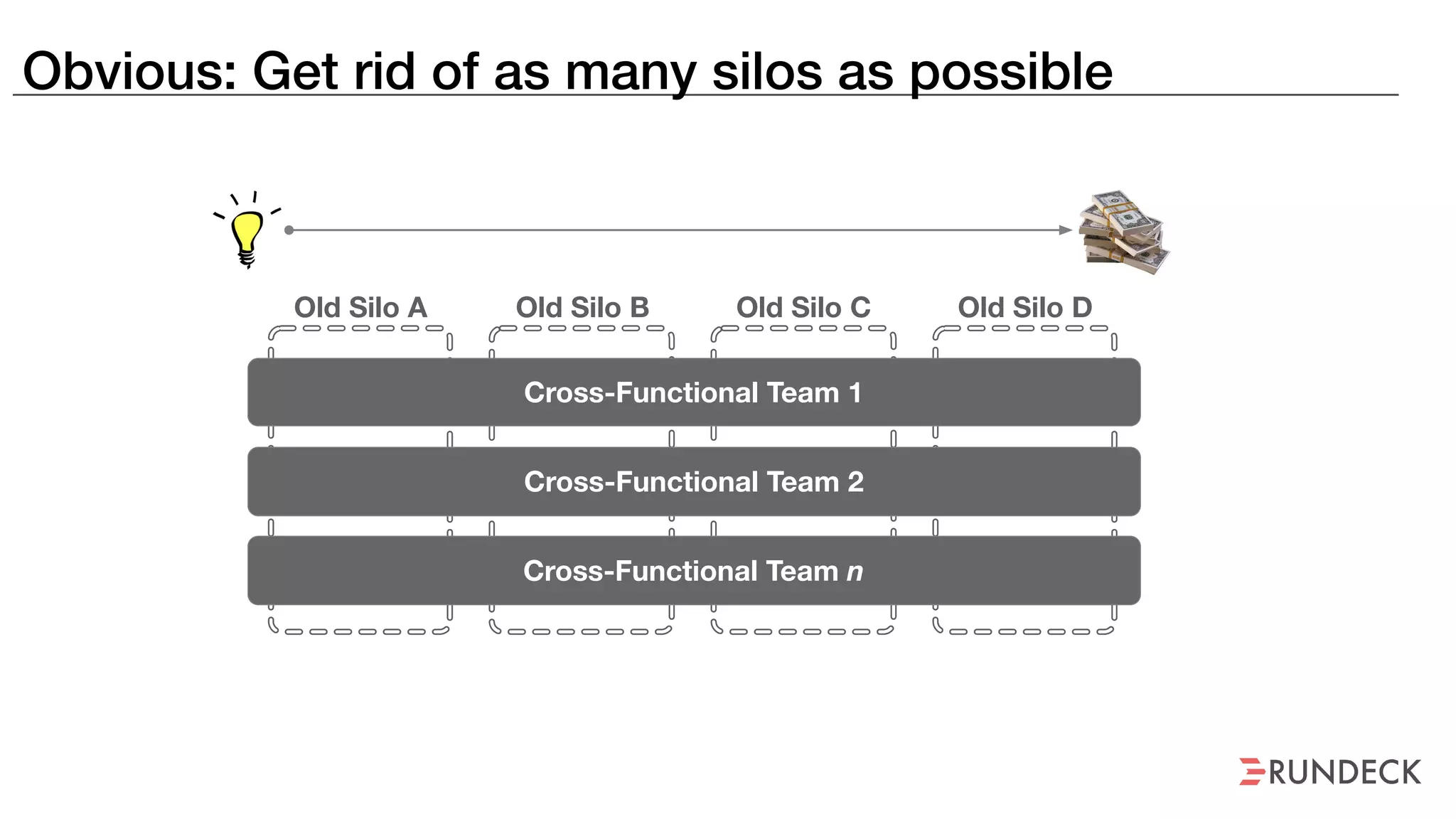



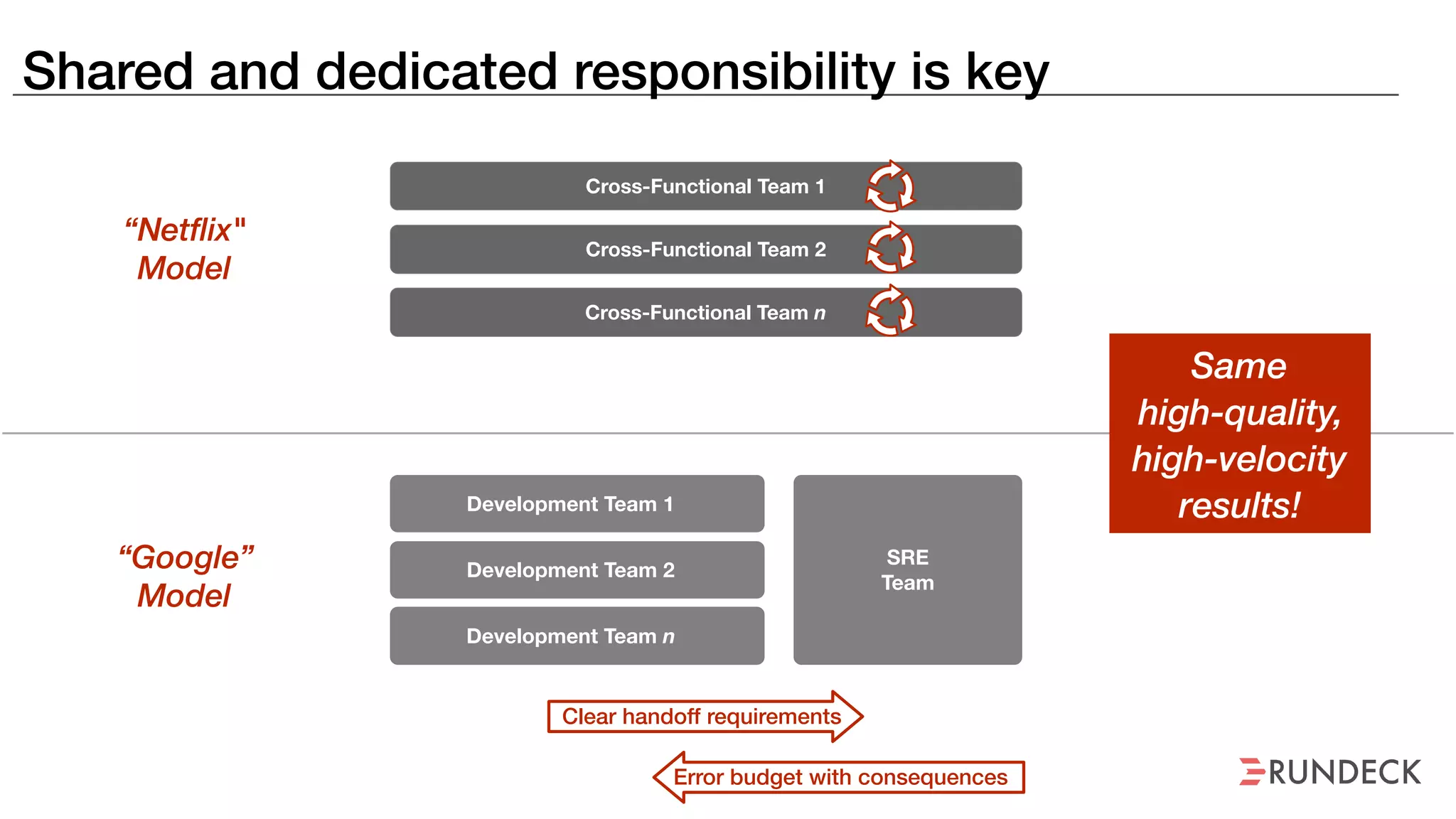

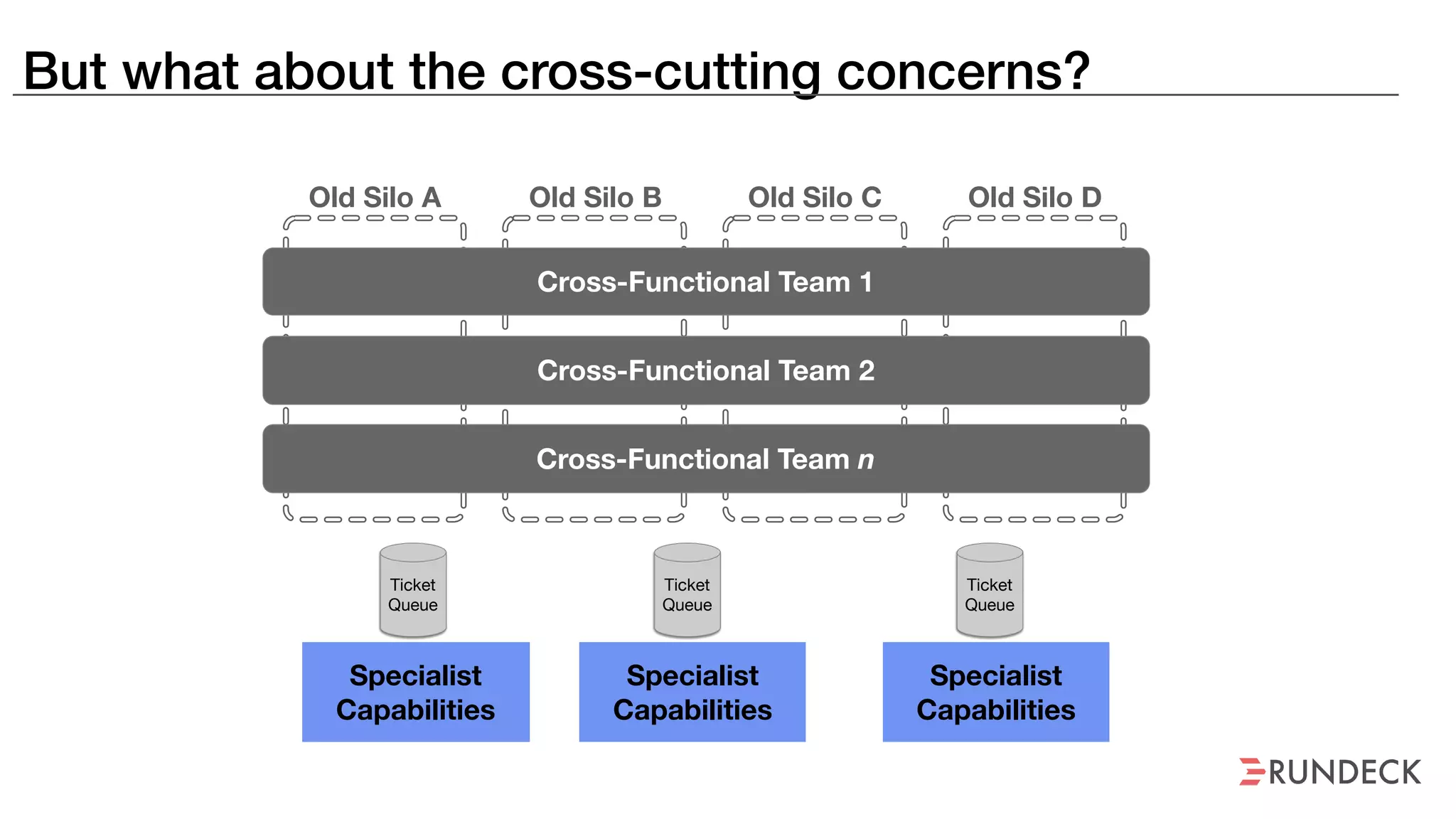
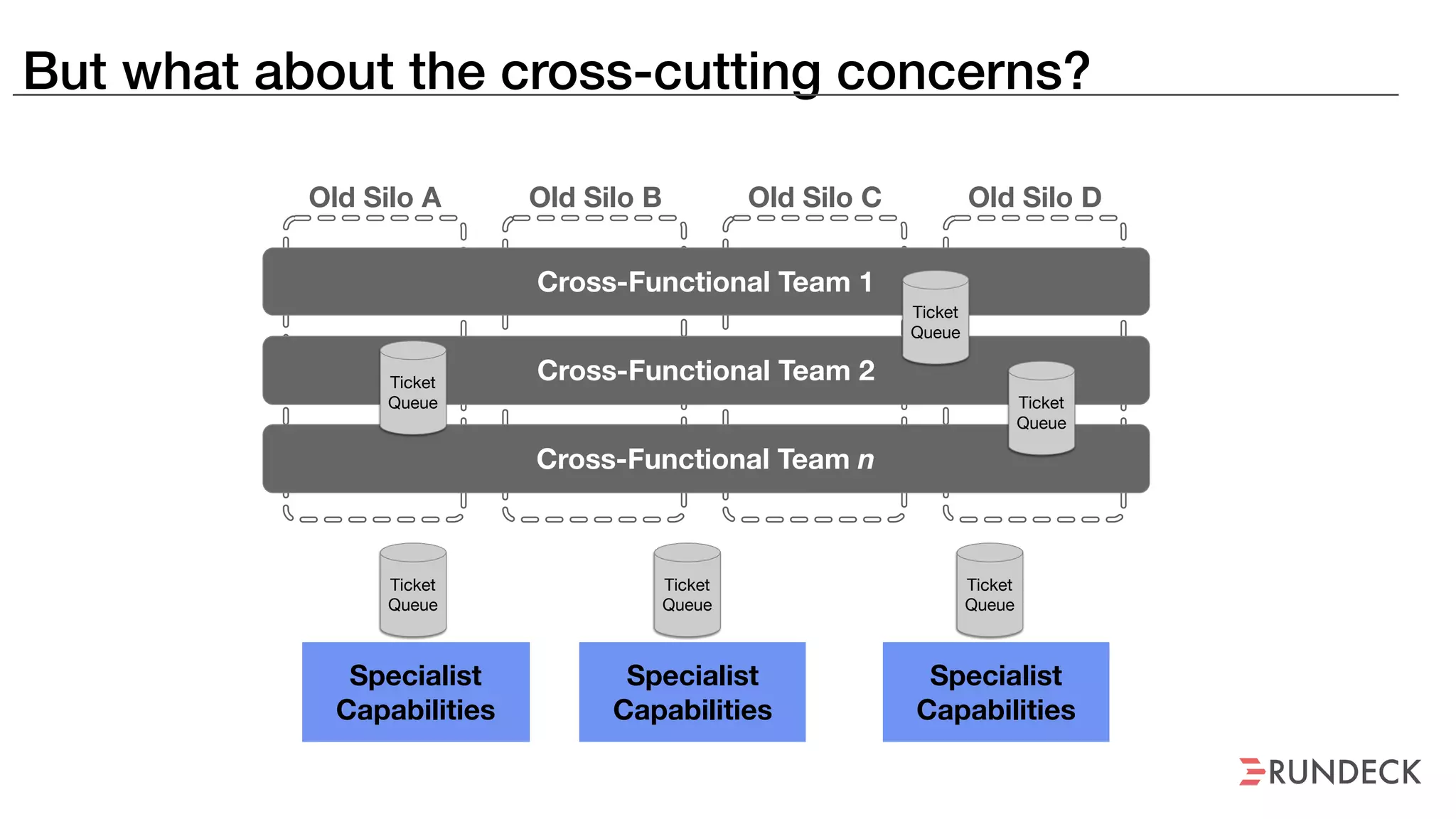
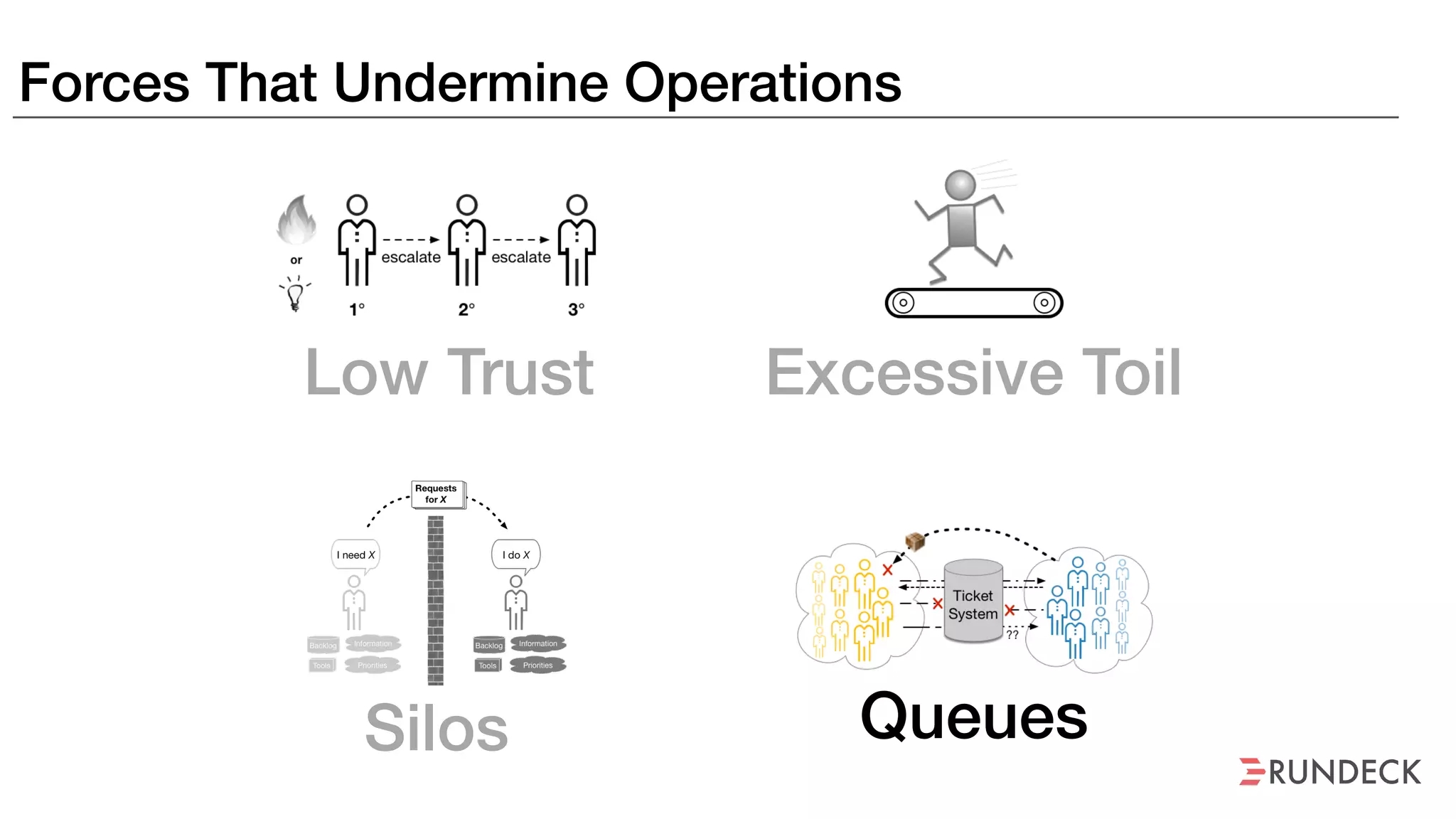


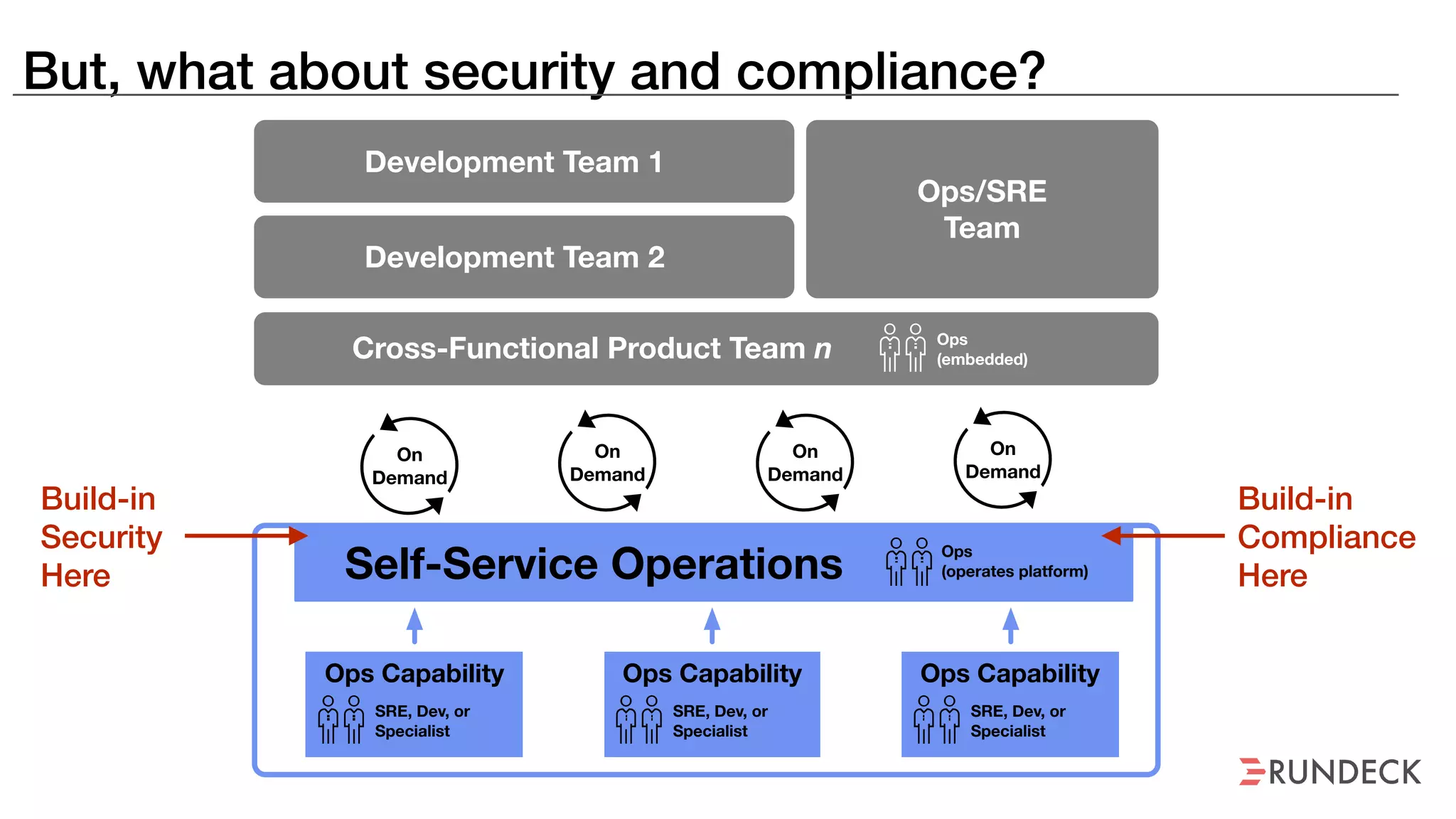



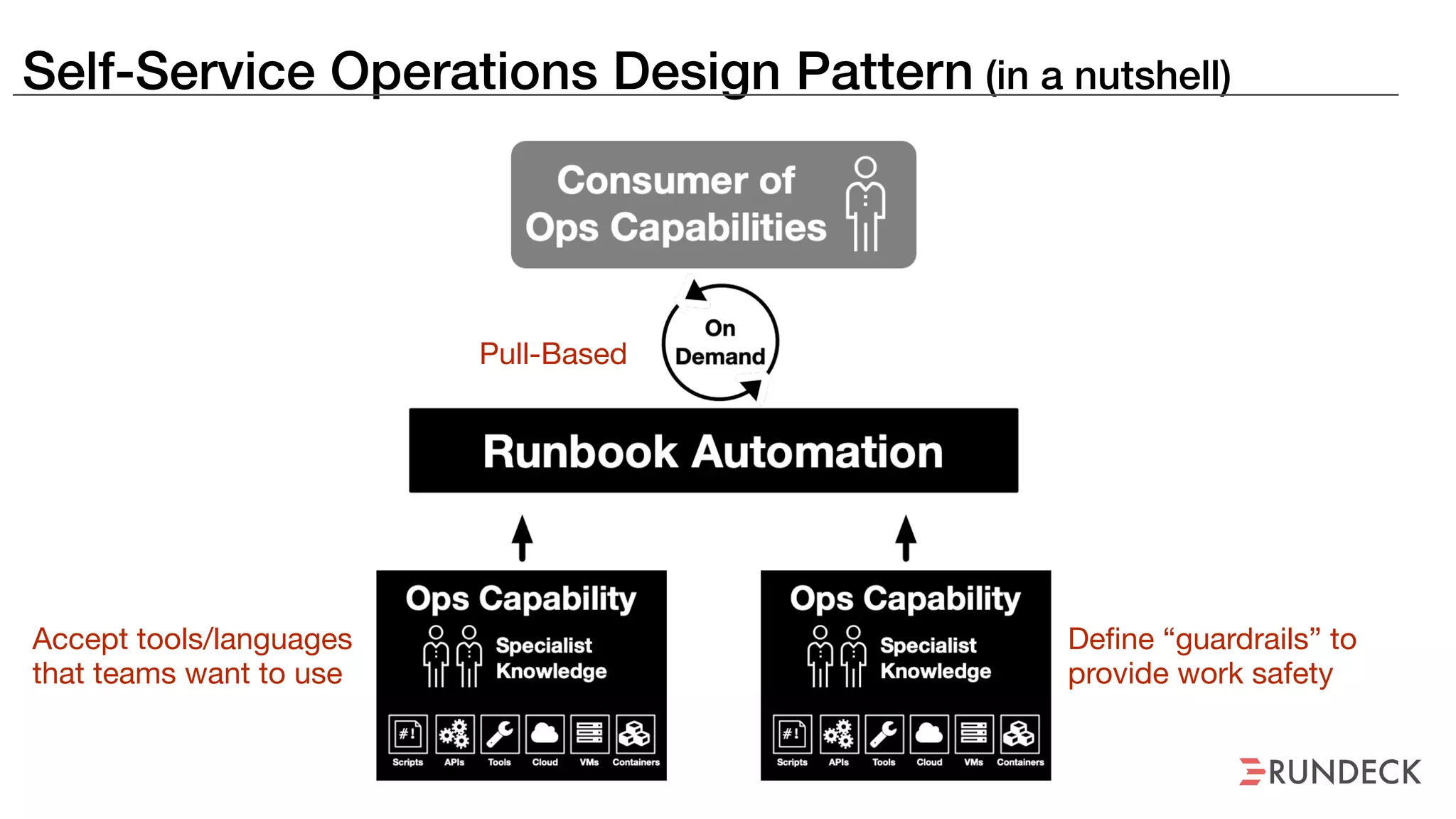
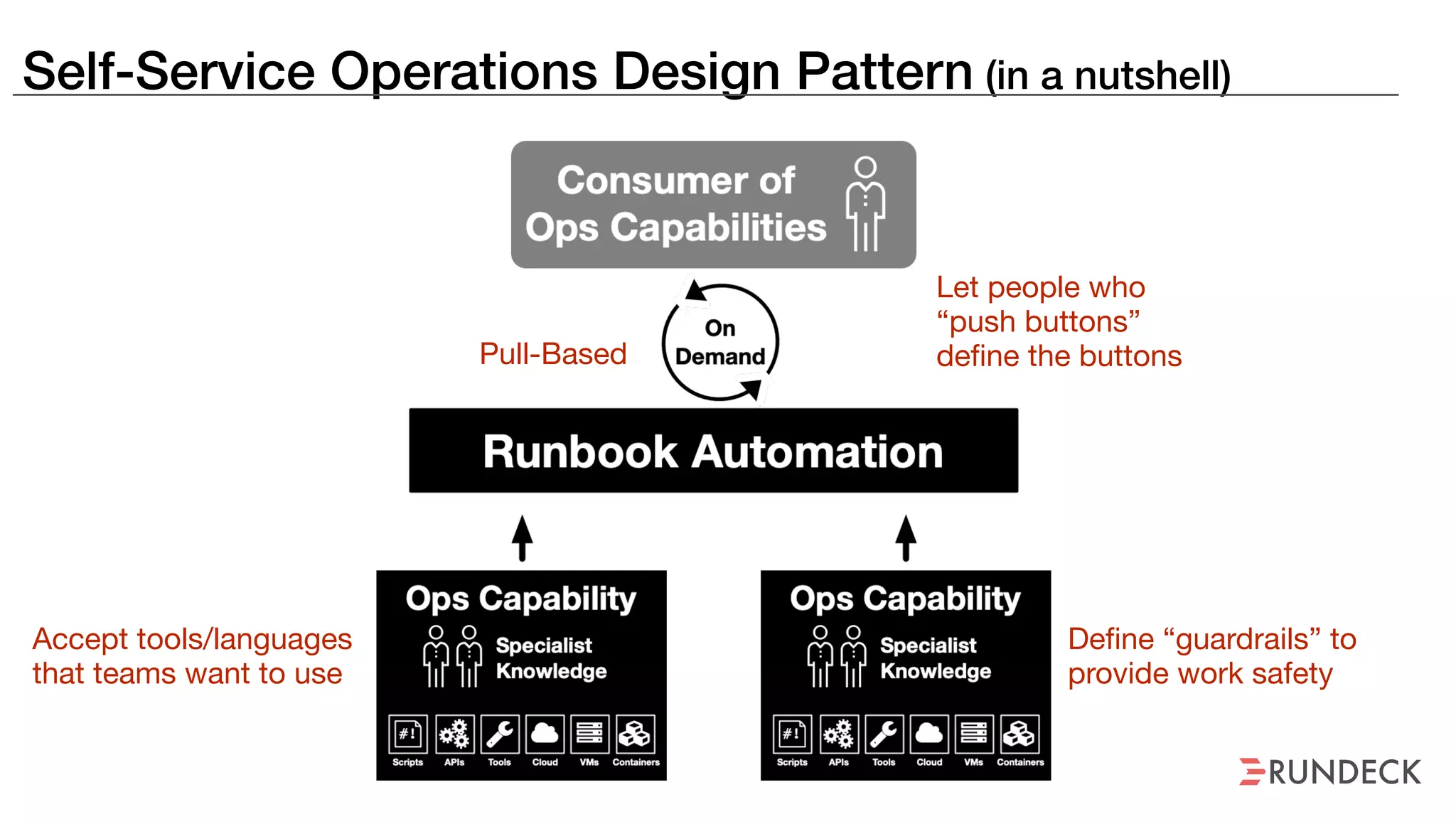
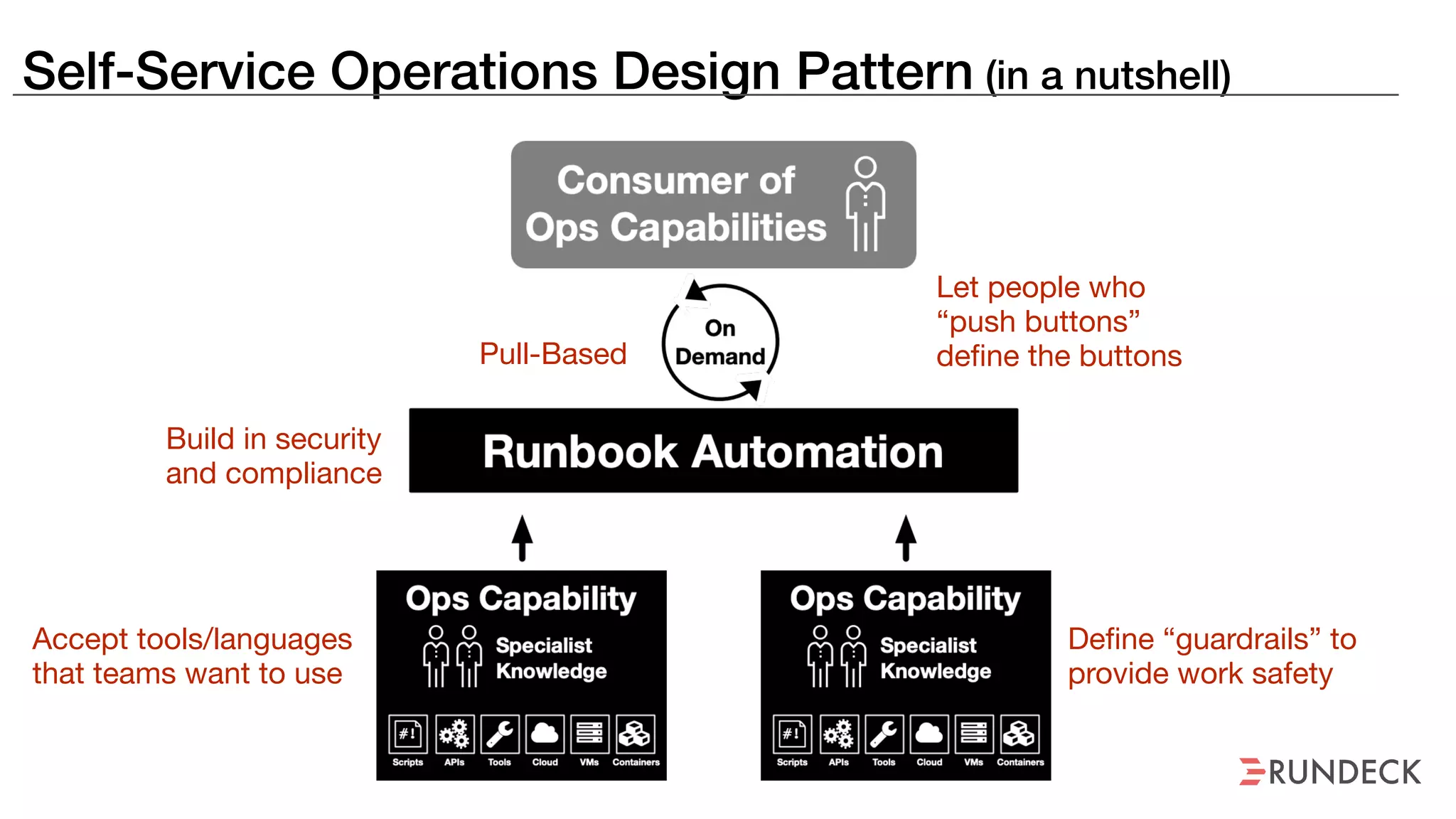





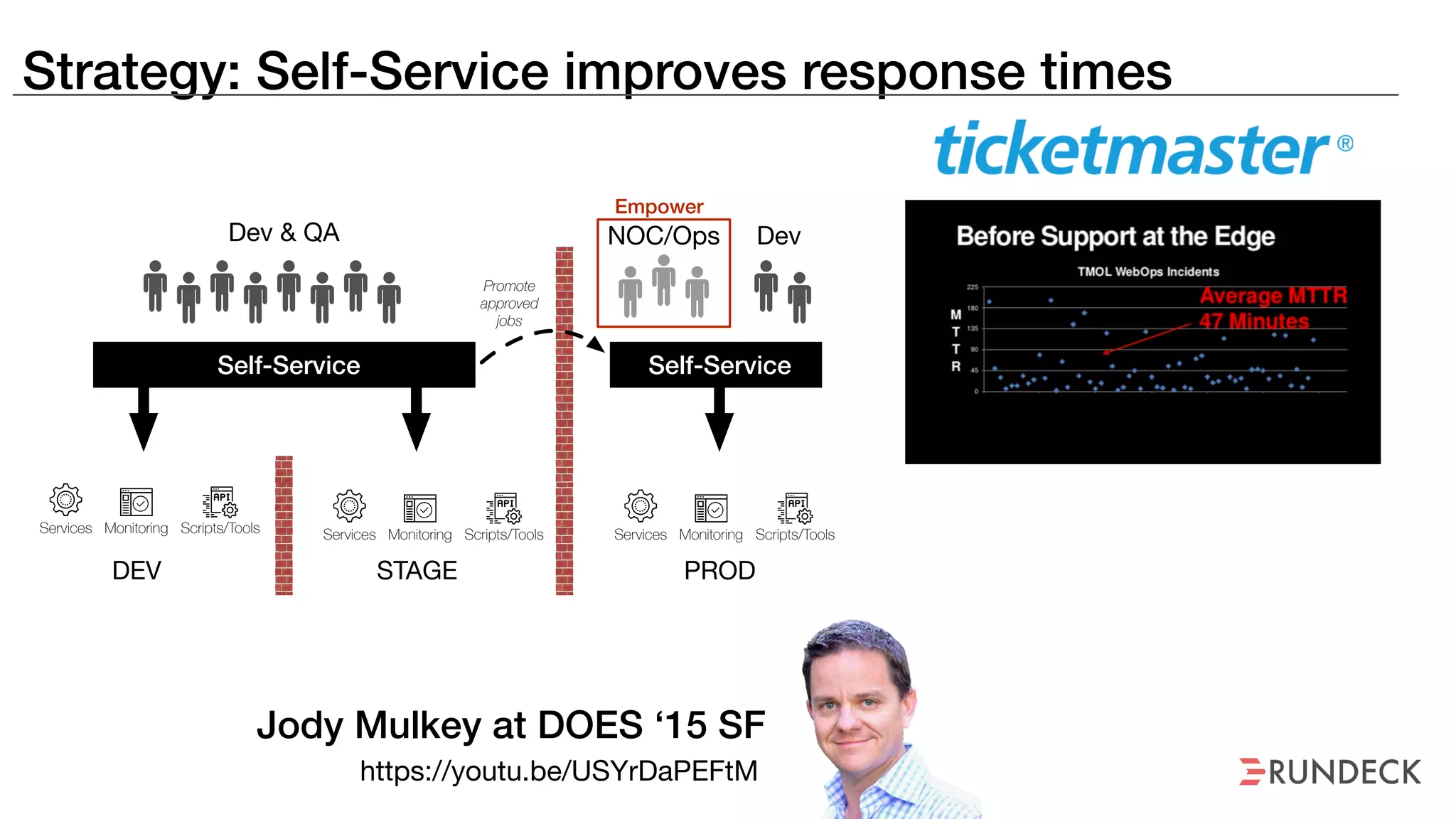



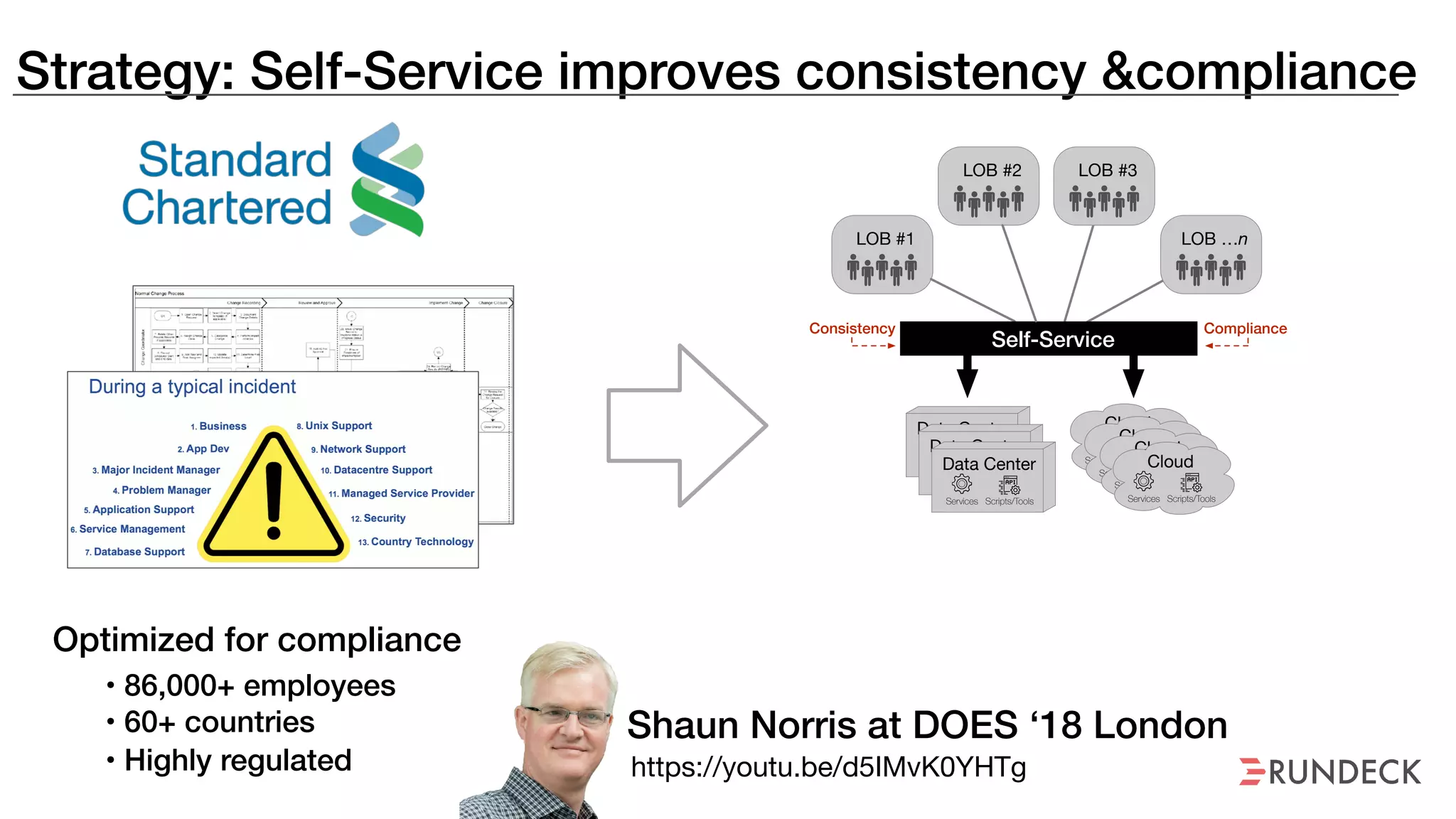




An outage of the Foo service caused many interruptions and context switches as the NOC, developers, SREs, and other teams worked to resolve the issue. It took time to escalate, diagnose the problem, get the necessary access and approvals, and restart the services with the correct configuration to fully resolve the outage. The process highlighted how handoffs between teams, disconnected access, waiting, and misaligned priorities can slow resolution of incidents in production.































































![Runbook Automation: Old News or a Key to Unlock Performance? [DOES2020]](https://cdn.slidesharecdn.com/ss_thumbnails/does-damonedwards-v2-201015073337-thumbnail.jpg?width=640&height=640&fit=bounds)























