Download as PDF, PPTX












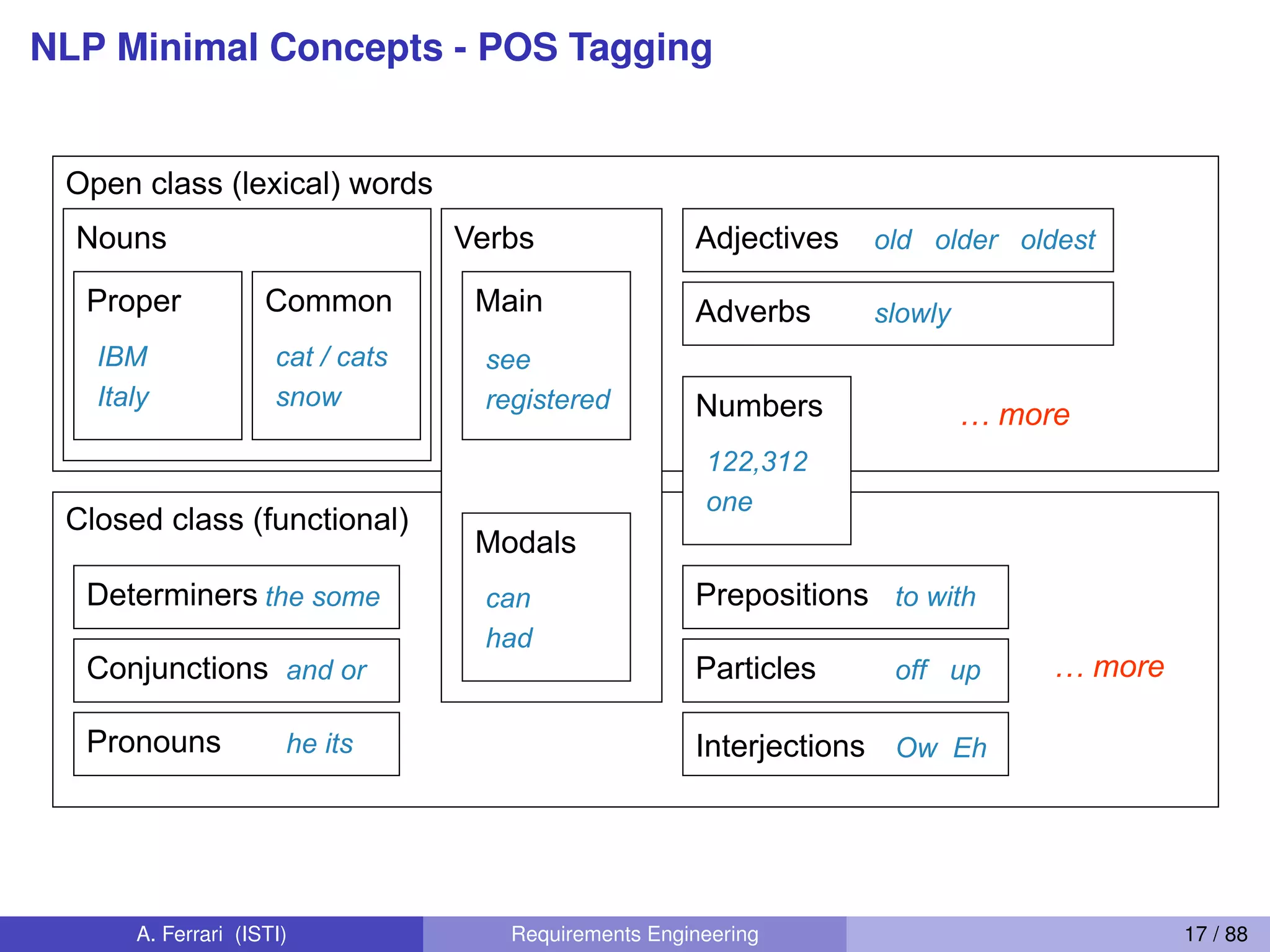























![Python - Language Features
Indentation instead of braces
Several sequence types
I Strings (immutable):
’This is a string’, and “Also this is a string”
I Tuples (immutable):
(’the’, ’system’, ’shall’, ’measure’, ’the’, ’heartbeat’)
I Lists (mutable):
[’the’, ’system’, ’shall’, ’measure’, ’the’, ’heartbeat’]
Lists and Tuples can contain anything:
I ((’REQ’, 1), ’the system shall measure the heartbeat’)
I [((’REQ’, 1), ’the system shall measure the heartbeat’), ((’REQ’, 2),
’the system shall alert the nurse’))]
A. Ferrari (ISTI) Requirements Engineering 49 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-49-2048.jpg)
![Python - Sequence Types
Tuples are defined using parentheses (and commas).
tu = (23, ‘abc’, 4.56, (2,3), ‘def’)
Lists are defined using square brackets (and commas)
li = [“abc”, 34, 4.34, 23]
Strings are defined using quotes (“, ‘, or “““)
st = “Hello World”
st = ‘Hello World’
st = “““Hello World ”””
A. Ferrari (ISTI) Requirements Engineering 50 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-50-2048.jpg)
![Python - Sequence Types
We can access individual members of a tuple, list, or string using
square bracket “array” notation.
We can access individual members of a tuple, lis
using square bracket “array” notation.
Note that all are 0 based…
>>> tu = (23, ‘abc’, 4.56, (2,3), ‘def’)
>>> tu[1] # Second item in the tuple.
‘abc’
>>> li = [“abc”, 34, 4.34, 23]
>>> li[1] # Second item in the list.
34
>>> st = “Hello World”
>>> st[1] # Second character in string.
‘e’
A. Ferrari (ISTI) Requirements Engineering 51 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-51-2048.jpg)
![Python - Negative IndicesNegative indices
>>> t = (23, ‘abc’, 4.56, (2,3), ‘def’)
Positive index: count from the left, starting with 0.
>>> t[1]
‘abc’
Negative lookup: count from right, starting with –1.
>>> t[-3]
4.56
A. Ferrari (ISTI) Requirements Engineering 52 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-52-2048.jpg)
![Python - Slicing
30
Slicing: Return Copy of a Subset 1
>>> t = (23, ‘abc’, 4.56, (2,3), ‘def’)
Return a copy of the container with a subset of the original
members. Start copying at the first index, and stop copying
before the second index.
>>> t[1:4]
(‘abc’, 4.56, (2,3))
You can also use negative indices when slicing.
>>> t[1:-1]
(‘abc’, 4.56, (2,3))
Optional argument allows selection of every nth item.
>>> t[1:-1:2]
(‘abc’, (2,3))
A. Ferrari (ISTI) Requirements Engineering 53 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-53-2048.jpg)
![Python - ‘in’ OperatorThe ‘in’ Operator
Boolean test whether a value is inside a collection (often
called a container in Python:
>>> t = [1, 2, 4, 5]
>>> 3 in t
False
>>> 4 in t
True
>>> 4 not in t
False
For strings, tests for substrings
>>> a = 'abcde'
>>> 'c' in a
True
>>> 'cd' in a
True
>>> 'ac' in a
False
Be careful: the in keyword is also used in the syntax of
for loops and list comprehensions.
A. Ferrari (ISTI) Requirements Engineering 54 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-54-2048.jpg)
![Python - ‘+’ Operator
34
The + Operator
The + operator produces a new tuple, list, or string whose
value is the concatenation of its arguments.
Extends concatenation from strings to other types
>>> (1, 2, 3) + (4, 5, 6)
(1, 2, 3, 4, 5, 6)
>>> [1, 2, 3] + [4, 5, 6]
[1, 2, 3, 4, 5, 6]
>>> “Hello” + “ ” + “World”
‘Hello World’
A. Ferrari (ISTI) Requirements Engineering 55 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-55-2048.jpg)
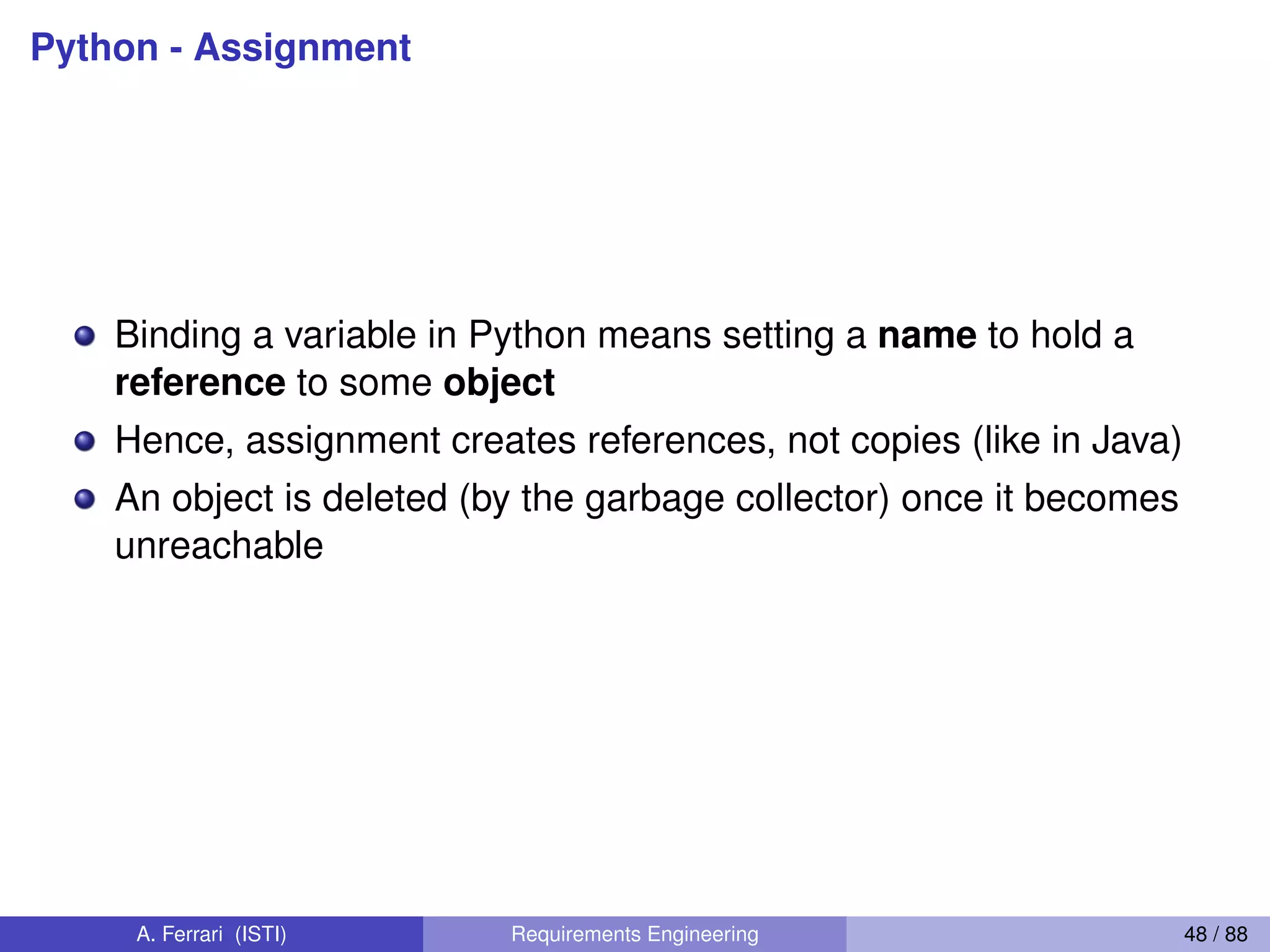
![Lists - Mutable
36
Lists: Mutable
>>> li = [‘abc’, 23, 4.34, 23]
>>> li[1] = 45
>>> li
[‘abc’, 45, 4.34, 23]
We can change lists in place.
Name li still points to the same memory reference when
we’re done.
A. Ferrari (ISTI) Requirements Engineering 56 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-56-2048.jpg)
![Tuples - Immutable
37
Tuples: Immutable
>>> t = (23, ‘abc’, 4.56, (2,3), ‘def’)
>>> t[2] = 3.14
Traceback (most recent call last):
File "<pyshell#75>", line 1, in -toplevel-
tu[2] = 3.14
TypeError: object doesn't support item assignment
You can’t change a tuple.
You can make a fresh tuple and assign its reference to a previously
used name.
>>> t = (23, ‘abc’, 3.14, (2,3), ‘def’)
The immutability of tuples means they’re faster than lists.
A. Ferrari (ISTI) Requirements Engineering 57 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-57-2048.jpg)
![Operations on Lists
38
Operations on Lists Only 1
>>> li = [1, 11, 3, 4, 5]
>>> li.append(‘a’) # Note the method syntax
>>> li
[1, 11, 3, 4, 5, ‘a’]
>>> li.insert(2, ‘i’)
>>>li
[1, 11, ‘i’, 3, 4, 5, ‘a’]
A. Ferrari (ISTI) Requirements Engineering 58 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-58-2048.jpg)

![Dictionaries - Creating and AccessingCreating and accessing
dictionaries
>>> d = {‘user’:‘bozo’, ‘pswd’:1234}
>>> d[‘user’]
‘bozo’
>>> d[‘pswd’]
1234
>>> d[‘bozo’]
Traceback (innermost last):
File ‘<interactive input>’ line 1, in ?
KeyError: bozo
A. Ferrari (ISTI) Requirements Engineering 60 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-60-2048.jpg)
![Dictionaries - Updating
Updating Dictionaries
>>> d = {‘user’:‘bozo’, ‘pswd’:1234}
>>> d[‘user’] = ‘clown’
>>> d
{‘user’:‘clown’, ‘pswd’:1234}
Keys must be unique.
Assigning to an existing key replaces its value.
>>> d[‘id’] = 45
>>> d
{‘user’:‘clown’, ‘id’:45, ‘pswd’:1234}
Dictionaries are unordered
New entry might appear anywhere in the output.
(Dictionaries work by hashing)
A. Ferrari (ISTI) Requirements Engineering 61 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-61-2048.jpg)
![Dictionaries - Removing
Removing dictionary entries
>>> d = {‘user’:‘bozo’, ‘p’:1234, ‘i’:34}
>>> del d[‘user’] # Remove one. Note that del is
# a function.
>>> d
{‘p’:1234, ‘i’:34}
>>> d.clear() # Remove all.
>>> d
{}
>>> a=[1,2]
>>> del a[1] # (del also works on lists)
>>> a
[1]
47
A. Ferrari (ISTI) Requirements Engineering 62 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-62-2048.jpg)
![Dictionaries - Useful Methods
Useful Accessor Methods
>>> d = {‘user’:‘bozo’, ‘p’:1234, ‘i’:34}
>>> d.keys() # List of current keys
[‘user’, ‘p’, ‘i’]
>>> d.values() # List of current values.
[‘bozo’, 1234, 34]
>>> d.items() # List of item tuples.
[(‘user’,‘bozo’), (‘p’,1234), (‘i’,34)]
A. Ferrari (ISTI) Requirements Engineering 63 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-63-2048.jpg)



![For Loops
Items can be more complex than a simple variable name
<statements>
<item> can be more complex than a single
variable name.
If the elements of <collection> are themselves collections,
then <item> can match the structure of the elements. (We
saw something similar with list comprehensions and with
ordinary assignments.)
for (x, y) in [(a,1), (b,2), (c,3), (d,4)]:
print x
60
A. Ferrari (ISTI) Requirements Engineering 67 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-67-2048.jpg)
![For Loops and range() Function
For loops and the range() function
We often want to write a loop where the variables ranges
over some sequence of numbers. The range() function
returns a list of numbers from 0 up to but not including the
number we pass to it.
range(5) returns [0,1,2,3,4]
So we can say:
for x in range(5):
print x
(There are several other forms of range() that provide
variants of this functionality…)
xrange() returns an iterator that provides the same
functionality more efficiently
61
A. Ferrari (ISTI) Requirements Engineering 68 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-68-2048.jpg)
![For Loops and range() Function
Abuse of the range() function
Don't use range() to iterate over a sequence solely to have
the index and elements available at the same time
Avoid:
for i in range(len(mylist)):
print i, mylist[i]
Instead:
for (i, item) in enumerate(mylist):
print i, item
This is an example of an anti-pattern in Python
For more, see:
http://www.seas.upenn.edu/~lignos/py_antipatterns.html
http://stackoverflow.com/questions/576988/python-specific-antipatterns-and-bad-
practices
A. Ferrari (ISTI) Requirements Engineering 69 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-69-2048.jpg)
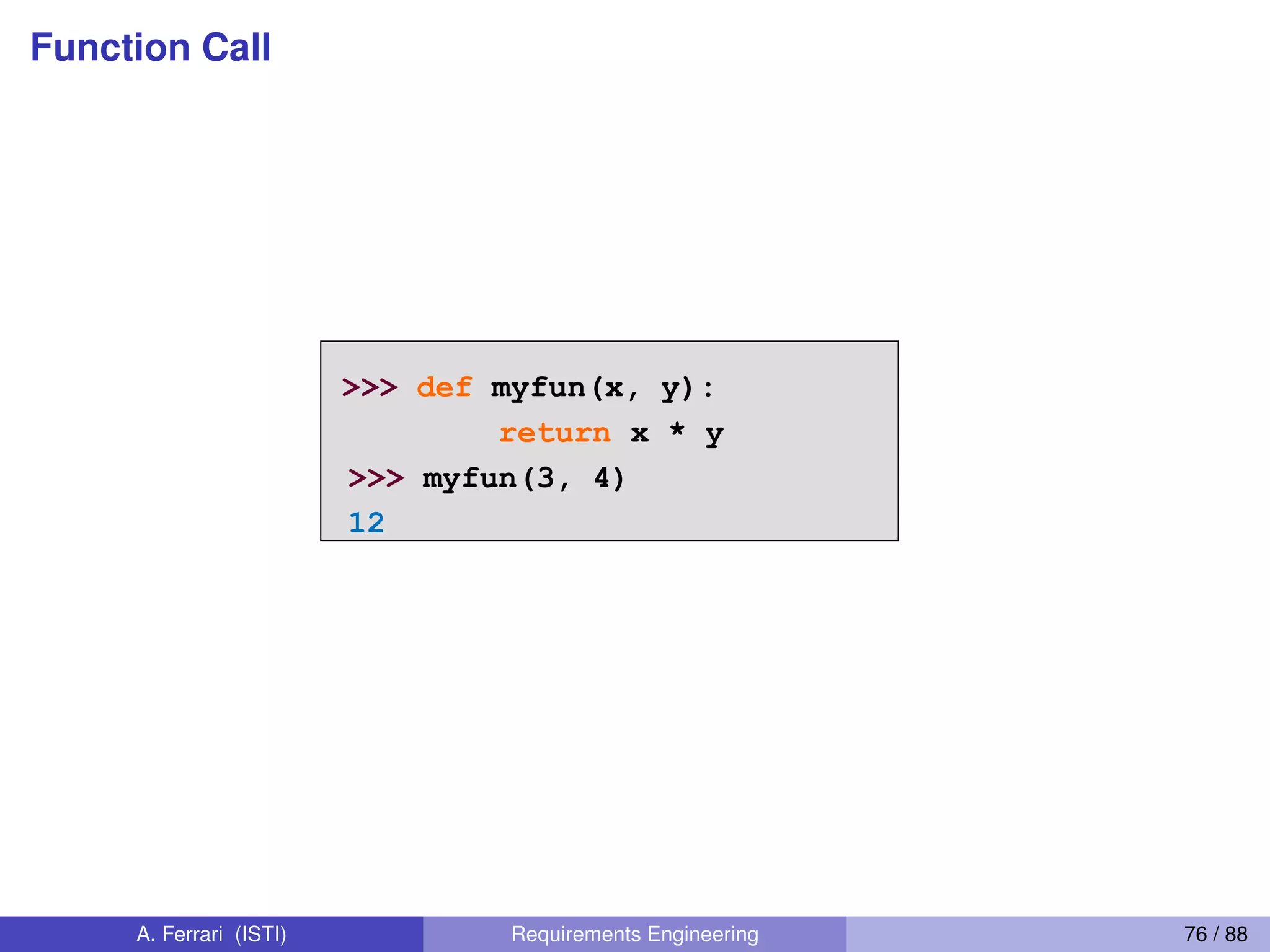
![List Comprehensions (remarkably cool)
List Comprehensions 1
A powerful feature of the Python language.
Generate a new list by applying a function to every member
of an original list.
Python programmers use list comprehensions extensively.
You’ll see many of them in real code.
[ expression for name in list ]
64
A. Ferrari (ISTI) Requirements Engineering 70 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-70-2048.jpg)
![List Comprehensions (remarkably cool)
List Comprehensions 2
>>> li = [3, 6, 2, 7]
>>> [elem*2 for elem in li]
[6, 12, 4, 14]
[ expression for name in list ]
Where expression is some calculation or operation
acting upon the variable name.
For each member of the list, the list comprehension
1. sets name equal to that member, and
2. calculates a new value using expression,
It then collects these new values into a list which is the
return value of the list comprehension.
[ expression for name in list ]
65
A. Ferrari (ISTI) Requirements Engineering 71 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-71-2048.jpg)
![List Comprehensions (remarkably cool)
List Comprehensions 3
If the elements of list are other collections, then
name can be replaced by a collection of names
that match the “shape” of the list members.
>>> li = [(‘a’, 1), (‘b’, 2), (‘c’, 7)]
>>> [ n * 3 for (x, n) in li]
[3, 6, 21]
[ expression for name in list ]
66
A. Ferrari (ISTI) Requirements Engineering 72 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-72-2048.jpg)
![Filtered List Comprehensions (remarkably cool)
Filtered List Comprehension 1
Filter determines whether expression is performed
on each member of the list.
When processing each element of list, first check if
it satisfies the filter condition.
If the filter condition returns False, that element is
omitted from the list before the list comprehension
is evaluated.
[ expression for name in list if filter]
67
A. Ferrari (ISTI) Requirements Engineering 73 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-73-2048.jpg)
![Filtered List Comprehensions (remarkably cool)
>>> li = [3, 6, 2, 7, 1, 9]
>>> [elem * 2 for elem in li if elem > 4]
[12, 14, 18]
Only 6, 7, and 9 satisfy the filter condition.
So, only 12, 14, and 18 are produced.
Filtered List Comprehension 2
[ expression for name in list if filter]
A. Ferrari (ISTI) Requirements Engineering 74 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-74-2048.jpg)




![Python NLTK - sentence tokenization (splitting)
>>> from nltk.tokenize import sent_tokenize
>>> sent_tokenize("hello this is nltk")
[’hello this is nltk’]
>>> sent_tokenize("hello. this is nltk")
[’hello.’, ’this is nltk’]
A. Ferrari (ISTI) Requirements Engineering 80 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-80-2048.jpg)
![Python NLTK - word tokenization
>>> from nltk.tokenize import word_tokenize
>>> word_tokenize("this is nltk")
[’this’, ’is’, ’nltk’]
A. Ferrari (ISTI) Requirements Engineering 81 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-81-2048.jpg)
![Python NLTK - word tokenization with punctuation
>>> word_tokenize("The woman’s car")
[’The’, ’woman’, "’s", ’car’]
>>> from nltk.tokenize import wordpunct_tokenize
>>> wordpunct_tokenize("The woman’s car")
[’The’, ’woman’, "’", ’s’, ’car’]
A. Ferrari (ISTI) Requirements Engineering 82 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-82-2048.jpg)


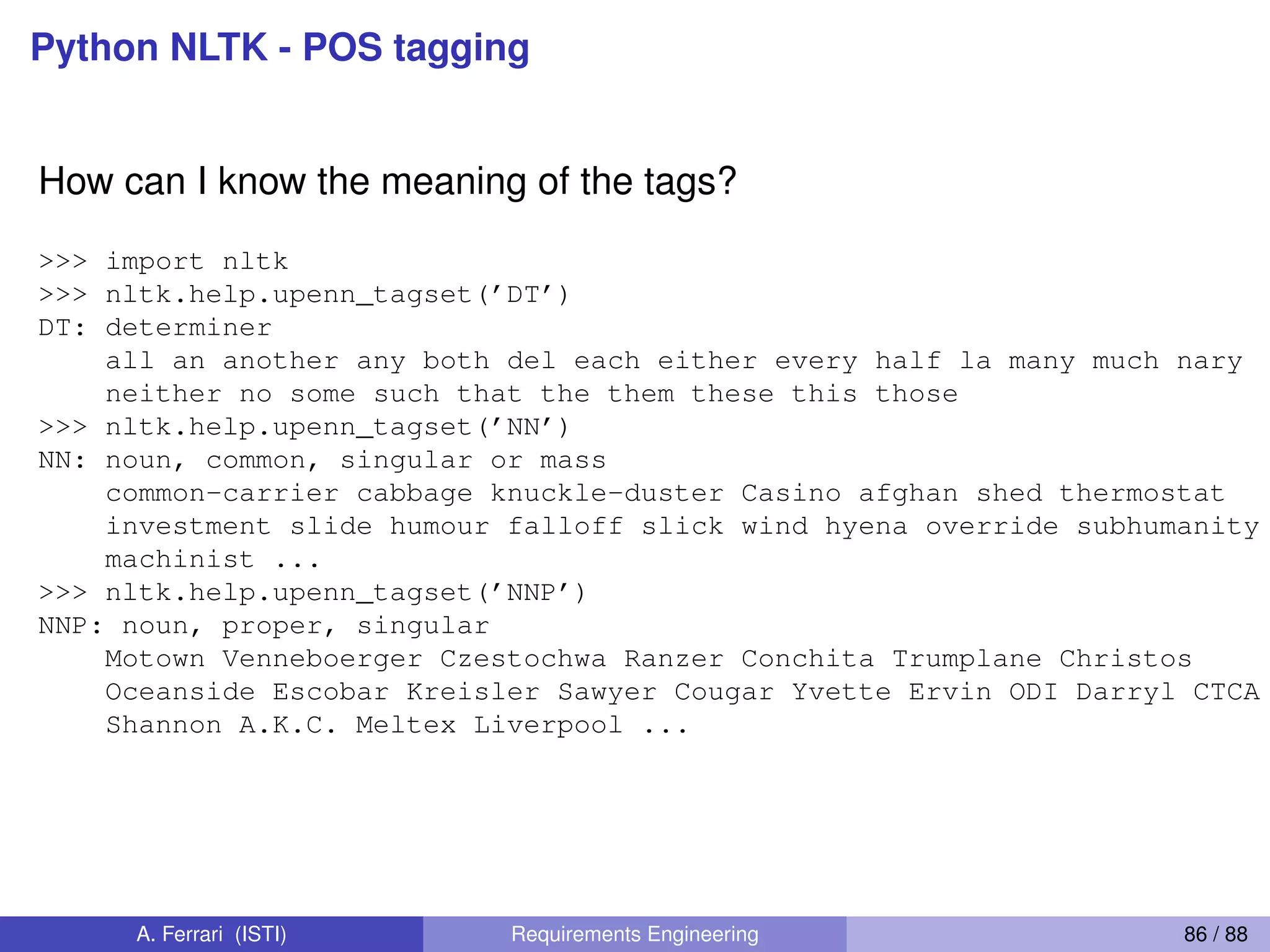
![Python NLTK - POS tagging
>>> t = word_tokenize("The system shall be nice")
>>> from nltk import pos_tag
>>> pos_tag(t)
[(’The’, ’DT’), (’system’, ’NN’),
(’shall’, ’MD’), (’be’, ’VB’), (’nice’, ’JJ’)]
A. Ferrari (ISTI) Requirements Engineering 85 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-85-2048.jpg)
![Python NLTK - stopword removal
>>> from nltk.corpus import stopwords
>>> stoplist = stopwords.words(’english’)
>>> sentence = ’The system shall be usable’
>>> print [i for i in word_tokenize(sentence) if i not in stoplist]
[’The’, ’system’, ’shall’, ’usable’]
>>> print [i for i in word_tokenize(sentence.lower())
if i not in stoplist]
[’system’, ’shall’, ’usable’]
A. Ferrari (ISTI) Requirements Engineering 87 / 88](https://image.slidesharecdn.com/requirementsengineering2-phd-200410085020/75/Requirements-Engineering-focus-on-Natural-Language-Processing-Lecture-2-87-2048.jpg)


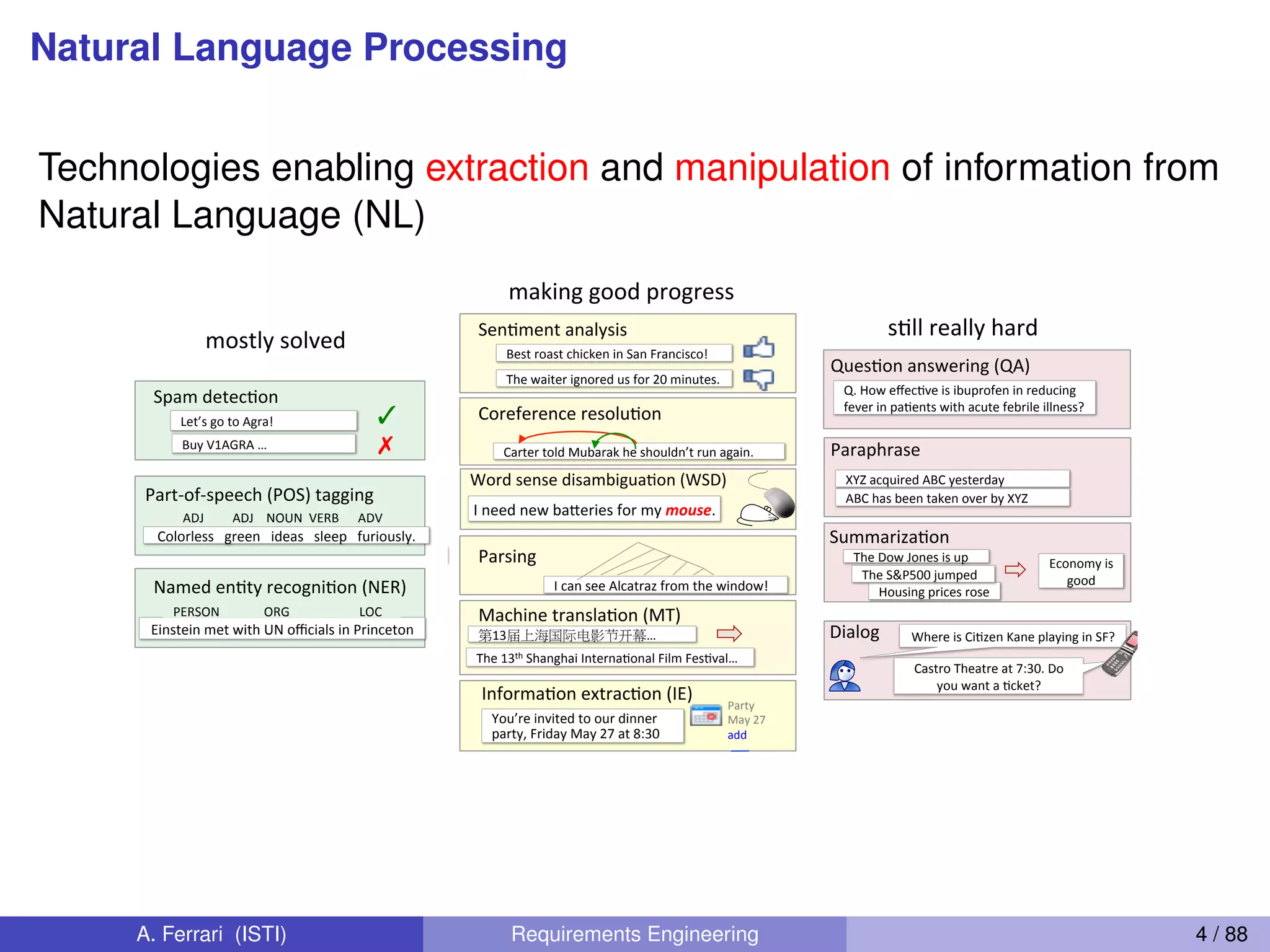
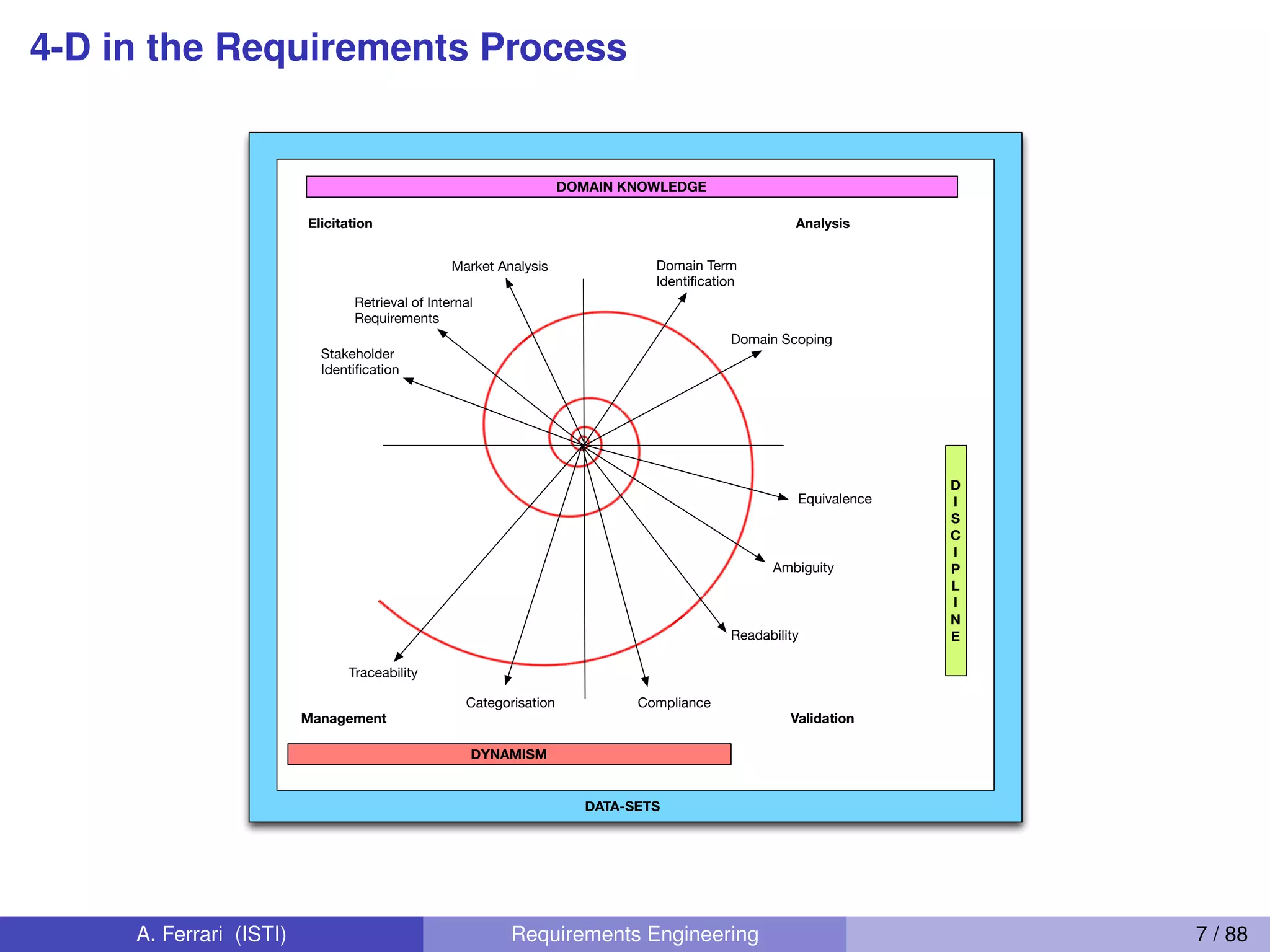
The document outlines objectives for a course on requirements engineering and natural language processing (NLP), emphasizing the relationship between NLP techniques and the elicitation and definition of software requirements. It covers various NLP concepts, such as ambiguity detection, tokenization, and part-of-speech tagging, which are crucial for processing natural language requirements effectively. Additionally, it discusses the challenges posed by ambiguity in requirements and the importance of rule-based approaches to ensure accuracy in identification.










































































