

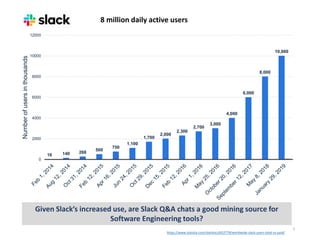

![Data Sets
5
Community
(Slack Channels)
#Conversations Community
(SO Tags)
#Posts
Slackauto Slackmanual SOauto SOmanual
clojurians#clojure 5,013 80 clojure 1,3920 80
elmlang#beginners 7,627 80 elm 1,019 160
elmlang#general 5,906 80 - - -
pythondev#help 3,768 80 python 806,763 80
racket#general 1,579 80 racket 3,592 80
Total 23,893 400 Total 825,294 400
Data Preparation:
• Chat Disentanglement [Elsner and Charniak 2008]
• LDA topic model](https://image.slidesharecdn.com/slidesmsr2019preetha-190529132804/85/Exploratory-Study-of-Slack-Q-A-Chats-as-a-Mining-Source-for-Software-Engineering-Tools-5-320.jpg)

![How has Stack Overflow been used as a
mining resource?
8
Code:
• IDE code recommendation [DeSouza‘14, Rahman‘14, Cordeiro’12, Ponzanelli‘14,
Bacchelli‘12, Amintaber‘15]
• Automatic generation of comments [Wong’13, Rahman‘15]
API:
• Learning and recommendation of APIs [Chen’16, Rahman’16, Wang’13]
• Augmenting API documentation [Treude‘16, Subramanian ‘14, Chen’14]
Other:
• Building thesaurus of software-specific terms [Tian’14, Chen’17]
• Gender bias and emotions [Novielli’14, Morgan ’17, Ford’16]
RQ1: Prevalence of information](https://image.slidesharecdn.com/slidesmsr2019preetha-190529132804/85/Exploratory-Study-of-Slack-Q-A-Chats-as-a-Mining-Source-for-Software-Engineering-Tools-7-320.jpg)




![Related Work on Analyzing Chats
18
• Learn developer behaviors [Elliot’03, Shihab’09, Yu’11, Lin’16]
• Filter out off-topic discussion [Chowdhury and Hindle’15]
• Extraction of rationale [Alkadhi’17, ‘18]
• Chatbots [Lebeuf’17, Paikari’18]](https://image.slidesharecdn.com/slidesmsr2019preetha-190529132804/85/Exploratory-Study-of-Slack-Q-A-Chats-as-a-Mining-Source-for-Software-Engineering-Tools-17-320.jpg)


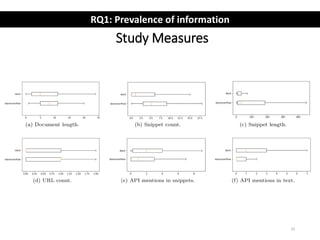
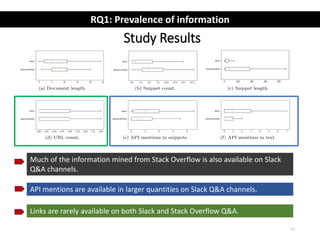
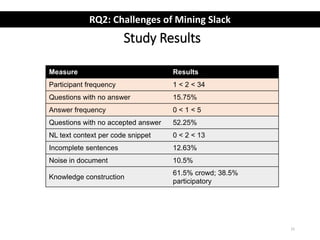
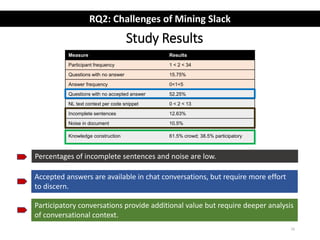
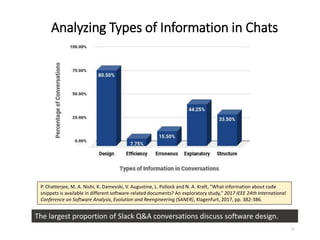
The document describes an exploratory study of mining information from Slack Q&A chat logs to support software engineering tools. The researchers analyzed conversations from several Slack communities to address how prevalent useful information is for tools (RQ1) and what challenges automatic mining faces (RQ2). Results found that while Slack contains similar information as Stack Overflow, identifying accepted answers is difficult. Future work is proposed to link Slack and Stack Overflow and mine conversations for insights.






































































