


![Mining Code Segments for Software Tools
3
Emails and bug-reports:
• Re-documenting source code [Panichella 2012]
• Recommending mentors in software projects [Canfora 2012]
Tutorials: API learning [Jiang 2017, Petrosyan 2015]
Q & A forums:
• IDE recommendation [DeSouza 2014, Rahman 2014, Cordeiro 2012, Ponzanelli
2014, Bacchelli 2012, Amintaber 2015]
• Learning and recommendation of API [Chen 2016, Rahman 2016, Wang 2013]
• Automatic generation of comments for source code [Wong 2013, Rahman 2015]
• Building thesaurus of software-specific terms [Tian 2014, Chen 2017]
Research Articles?
Chats?](https://image.slidesharecdn.com/sigsys-190913213629/85/Mining-Code-Examples-with-Descriptive-Text-from-Software-Artifacts-3-320.jpg)



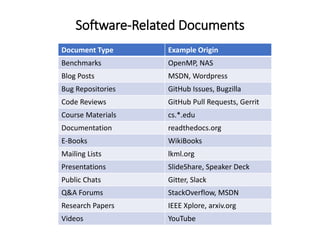
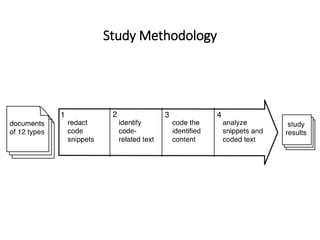
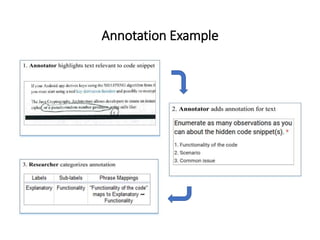
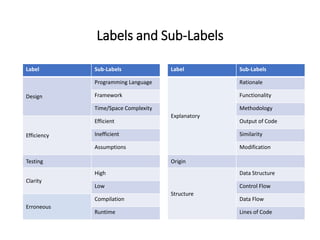

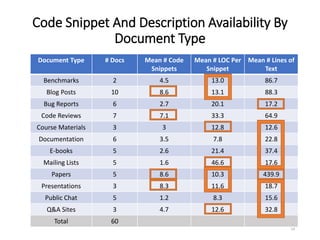





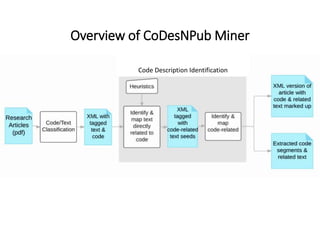




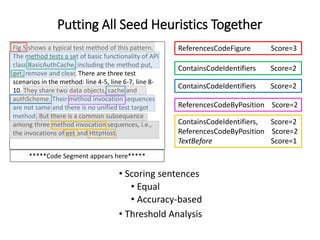


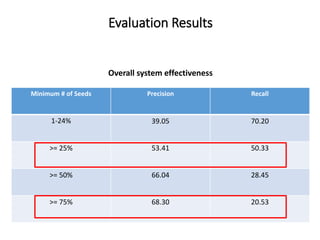




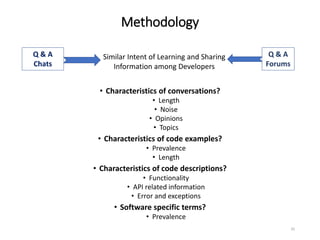
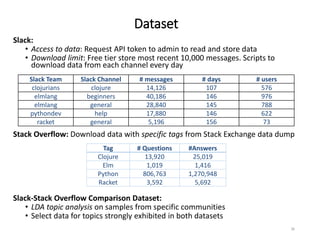



The document describes an exploratory study conducted to understand the types of information provided about code snippets embedded in different software-related documents. The study analyzed 60 documents across 12 categories and identified 17 labels and sub-labels for annotating the information about code snippets. Research papers were found to contain the most code snippets on average (8.6 per paper) with the longest descriptions (439 lines of text on average). The study aims to help develop techniques for mining relevant information from various document types to assist with software engineering tasks.










































































