Download as PDF, PPTX

![API
Monolith
PUT /v1/locations
5 sec
loop
{
"lat": 37.61,
"lng": -122.38
}
{
"drivers": [ ... ],
"primetime": 0,
"eta": 30,
...
}
200 OK
Index on users collection
(driver_mode, region)
Lyft backend in 2012
Location stored on user record](https://image.slidesharecdn.com/lyft-redisconf-2017-dhochman-geospatialatscale-170619223814/75/RedisConf17-Lyft-Geospatial-at-Scale-Daniel-Hochman-3-2048.jpg)
![Monolithic architecture issues
Global write lock, not shardable, difficult refactoring, region boundary issues
drivers_in_region = db.users.find(
driver_mode: {$eq: True},
region: {$eq: "SFO"},
ride_id: {$eq: None}
)
eligible_drivers = sort_and_filter_by_distance(
drivers_in_region, radius=.5
)
dispatch(eligible_drivers[0])](https://image.slidesharecdn.com/lyft-redisconf-2017-dhochman-geospatialatscale-170619223814/75/RedisConf17-Lyft-Geospatial-at-Scale-Daniel-Hochman-4-2048.jpg)

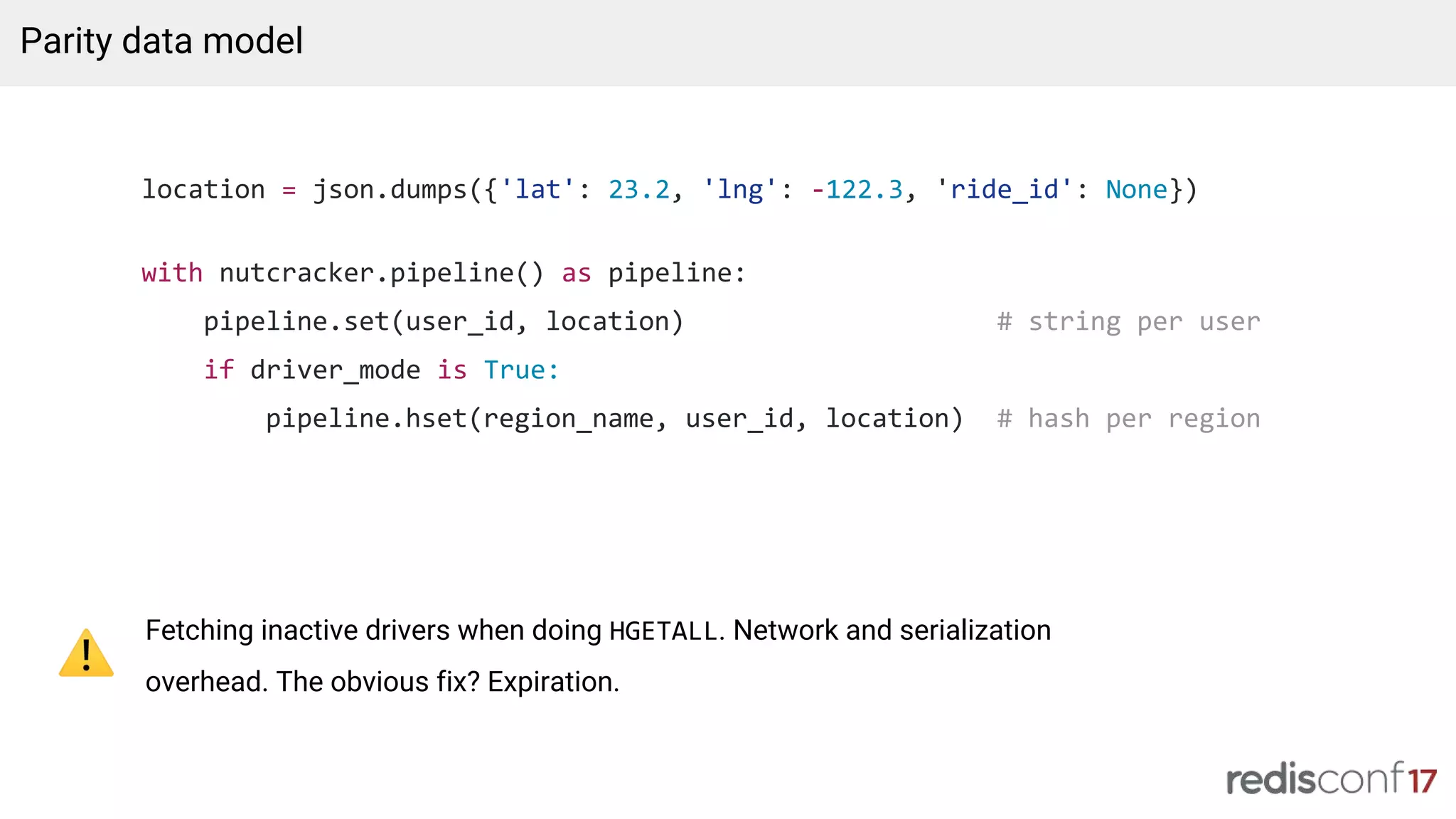

![loc = {'lat': 23.2, 'lng': -122.3, 'ride_id': None}
geohash = compute_geohash(loc['lat'], loc['lng'], level=5)
with nutcracker.pipeline() as pipeline:
# string per user
pipeline.set(user_id, json.dumps(loc))
# sorted set per geohash with last timestamp
if driver_mode is True:
pipeline.zset(geohash, user_id, now_seconds())
pipeline.zremrangebyscore(geohash, -inf, now_seconds() - 30) # expire!
Data model with geohashing
Sorted set tells you where a driver might be. Use string as source of truth.
On query, look in neighboring geohashes based on desired radius.](https://image.slidesharecdn.com/lyft-redisconf-2017-dhochman-geospatialatscale-170619223814/75/RedisConf17-Lyft-Geospatial-at-Scale-Daniel-Hochman-14-2048.jpg)





![Envoy Redis Roadmap
Additional command support
Error handling
Pipeline management features
Performance optimization
Replication
- Failover
- Mitigate hot read shard issues with large objects
- Zone local query routing
- Quorum
- Protocol overloading? e.g. SET key value [replication factor] [timeout]
More!](https://image.slidesharecdn.com/lyft-redisconf-2017-dhochman-geospatialatscale-170619223814/75/RedisConf17-Lyft-Geospatial-at-Scale-Daniel-Hochman-25-2048.jpg)


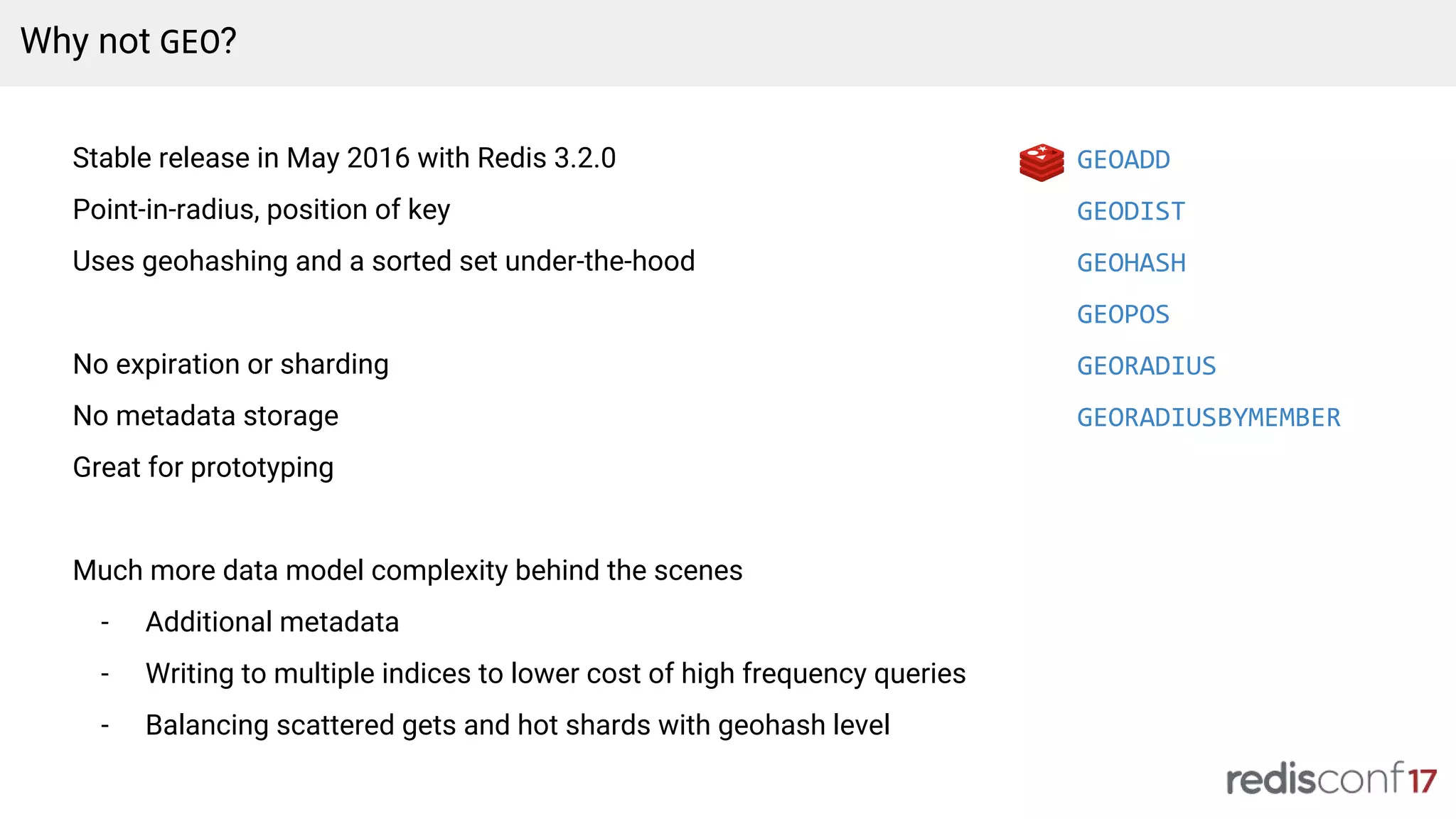
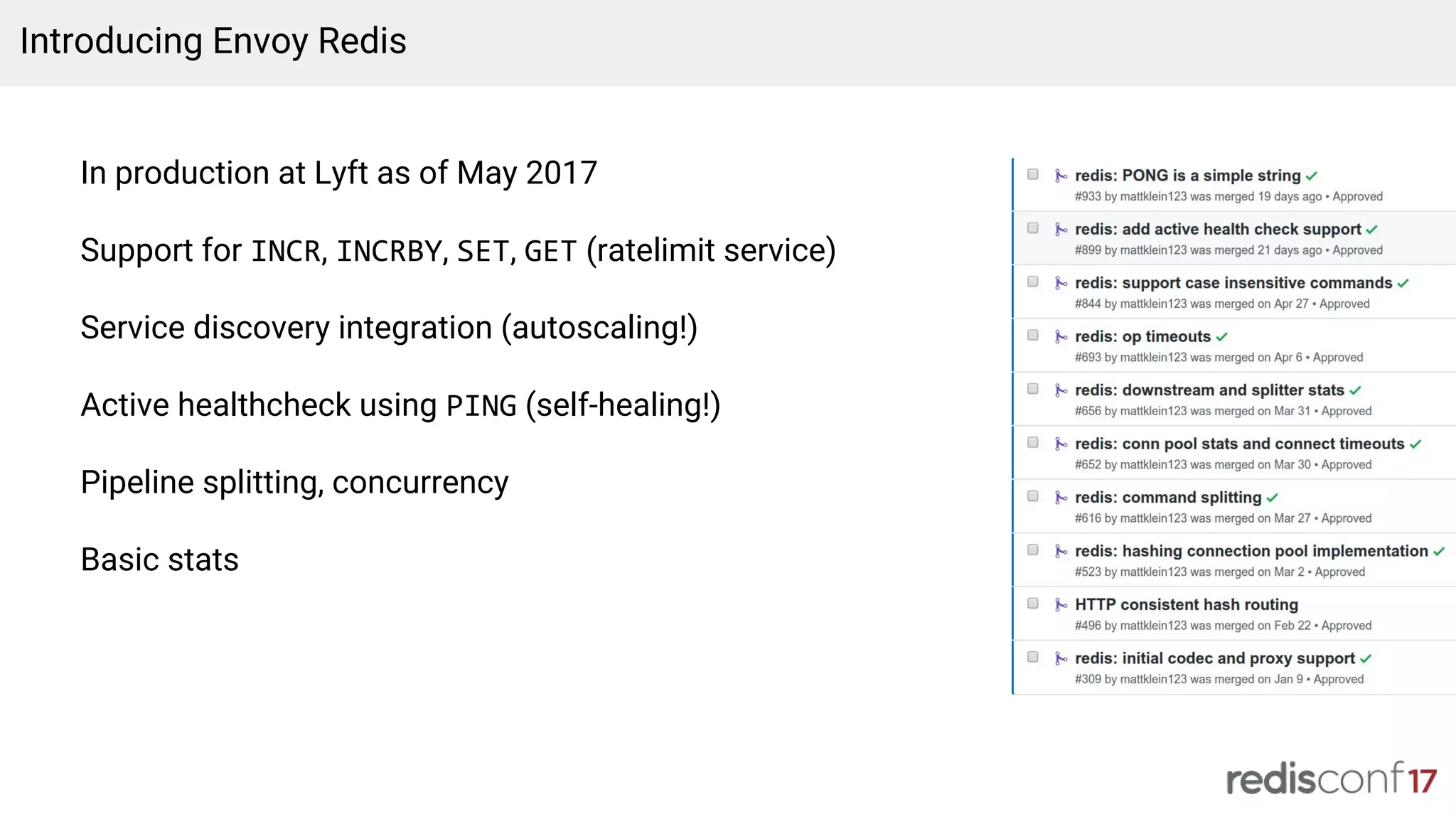
This document discusses Lyft's migration from a monolithic architecture to using Redis to power a geospatial indexing system at scale. It describes Lyft's original architecture, issues they faced, and how they iterated on their data model and use of Redis over time. It also discusses how Lyft uses Redis across their platform, including operations, monitoring, capacity planning, and their work contributing to open source projects like Envoy.
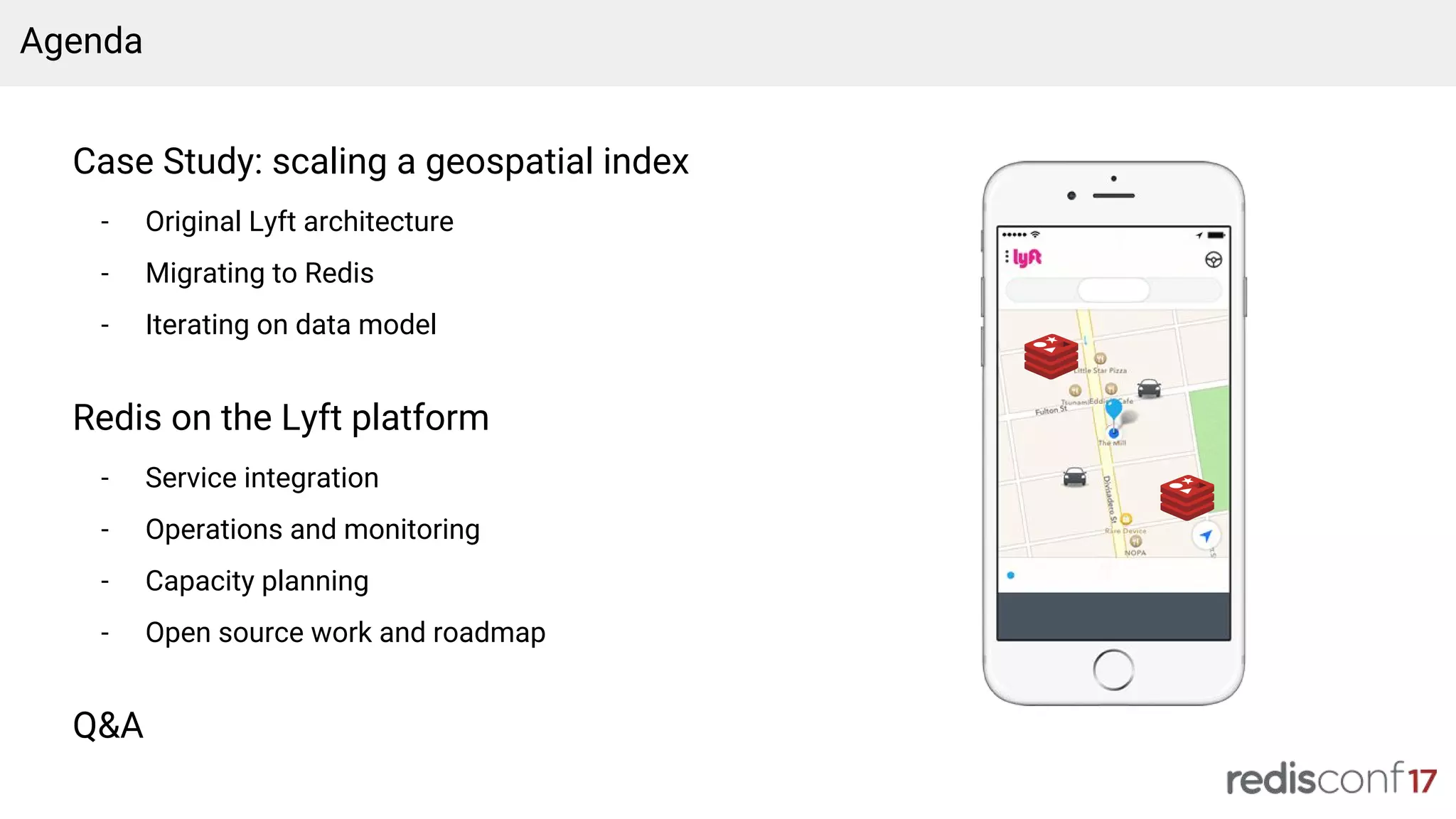
Overview of Lyft's Redis architecture for geospatial indexing and agenda for presentation.
Discussion on Lyft's monolithic architecture issues, including global write lock and refactoring challenges.
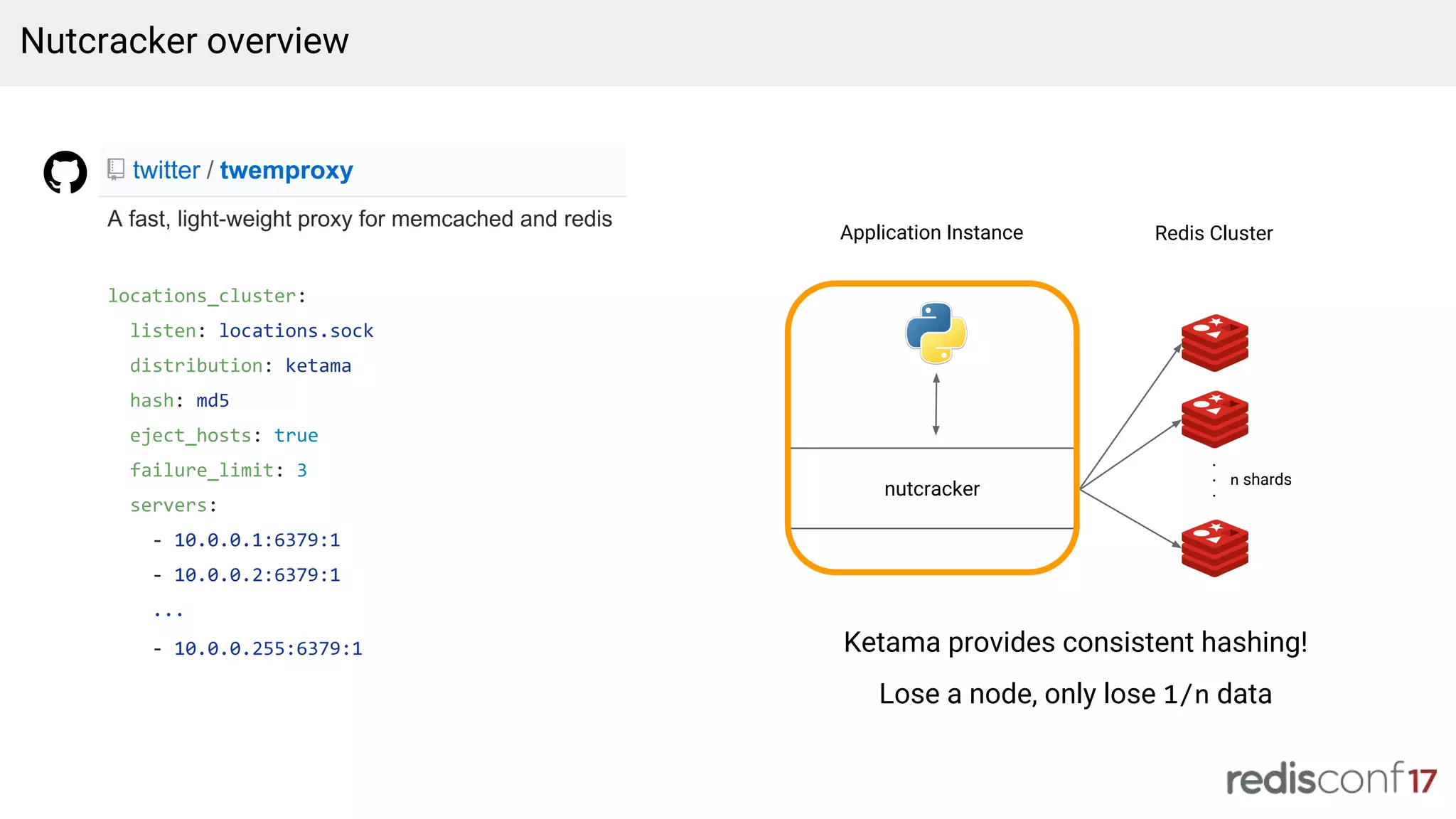
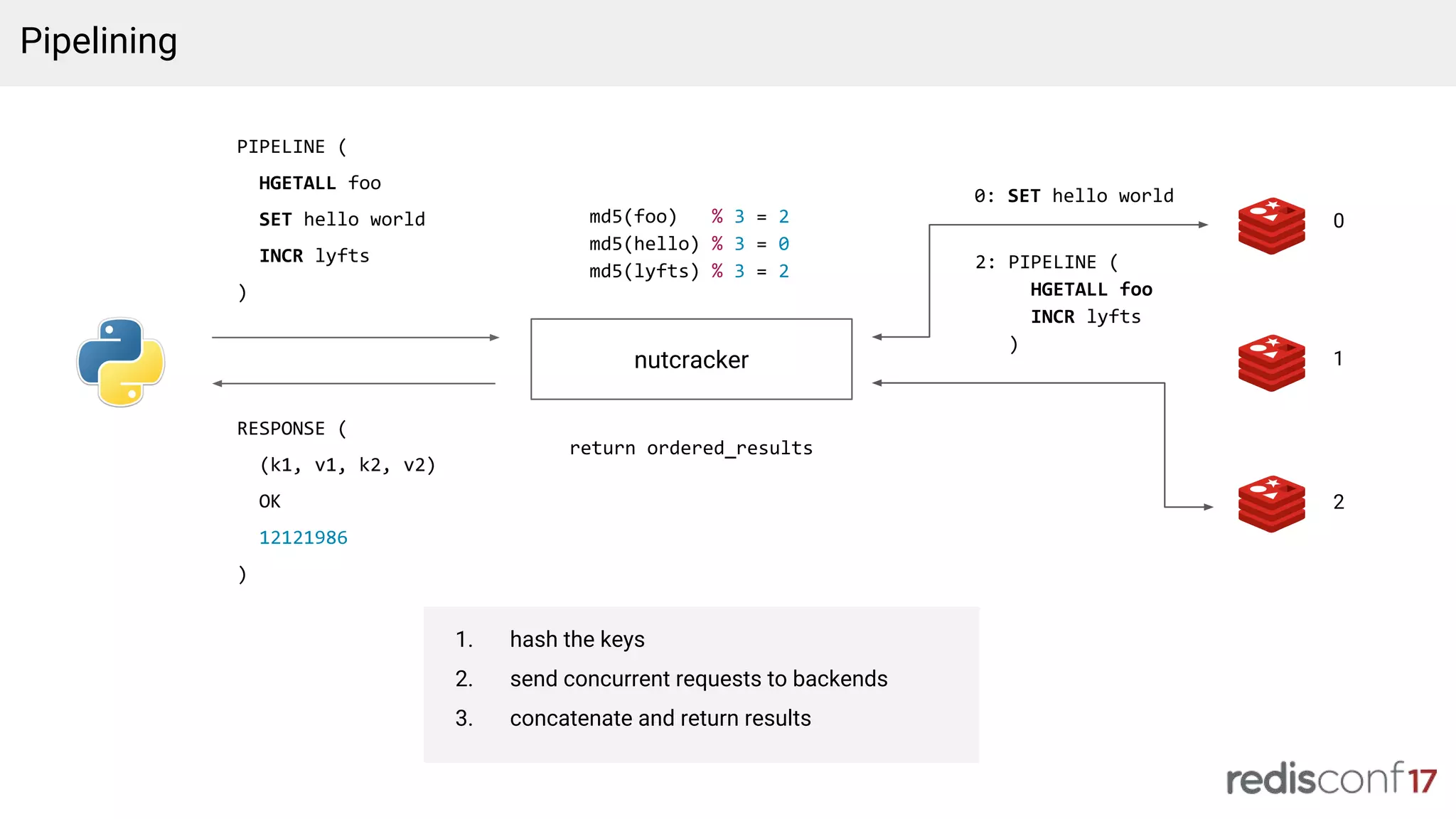
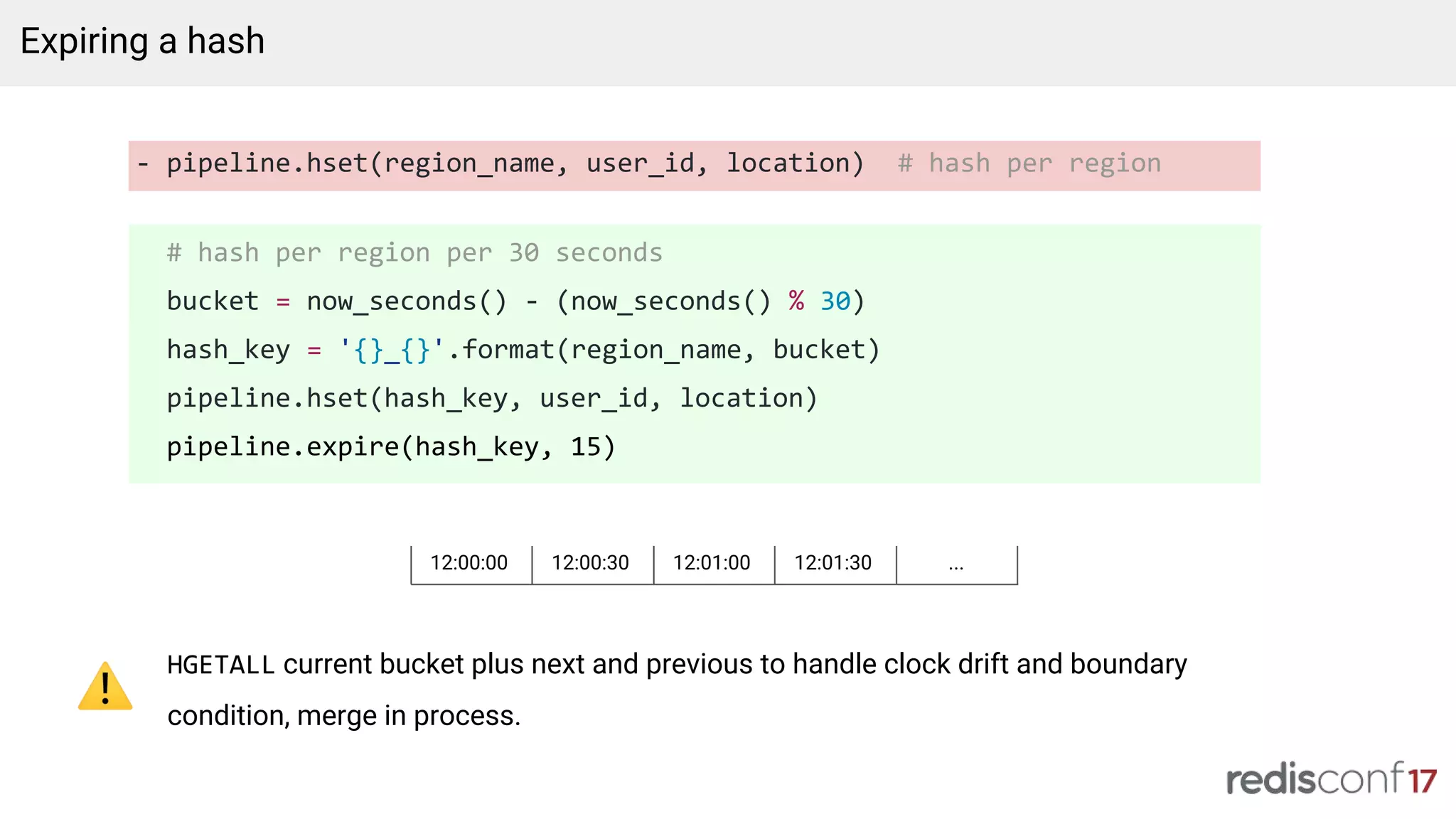
Introduction to Nutcracker, Redis clustering for scalability, and strategies for handling data expiration.
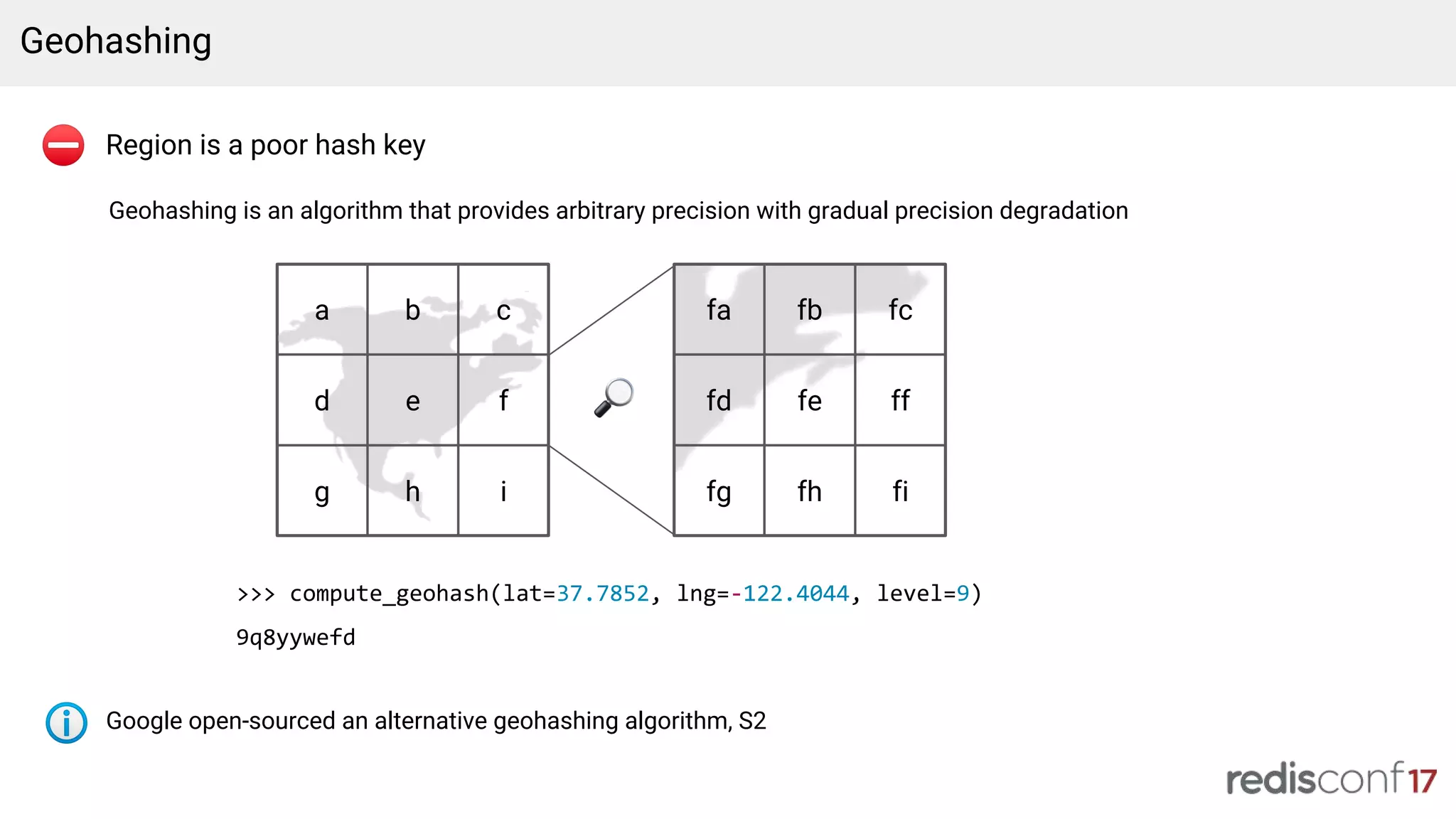
Transition from inefficient hash keys to geohashing for improved spatial queries and data retrieval.
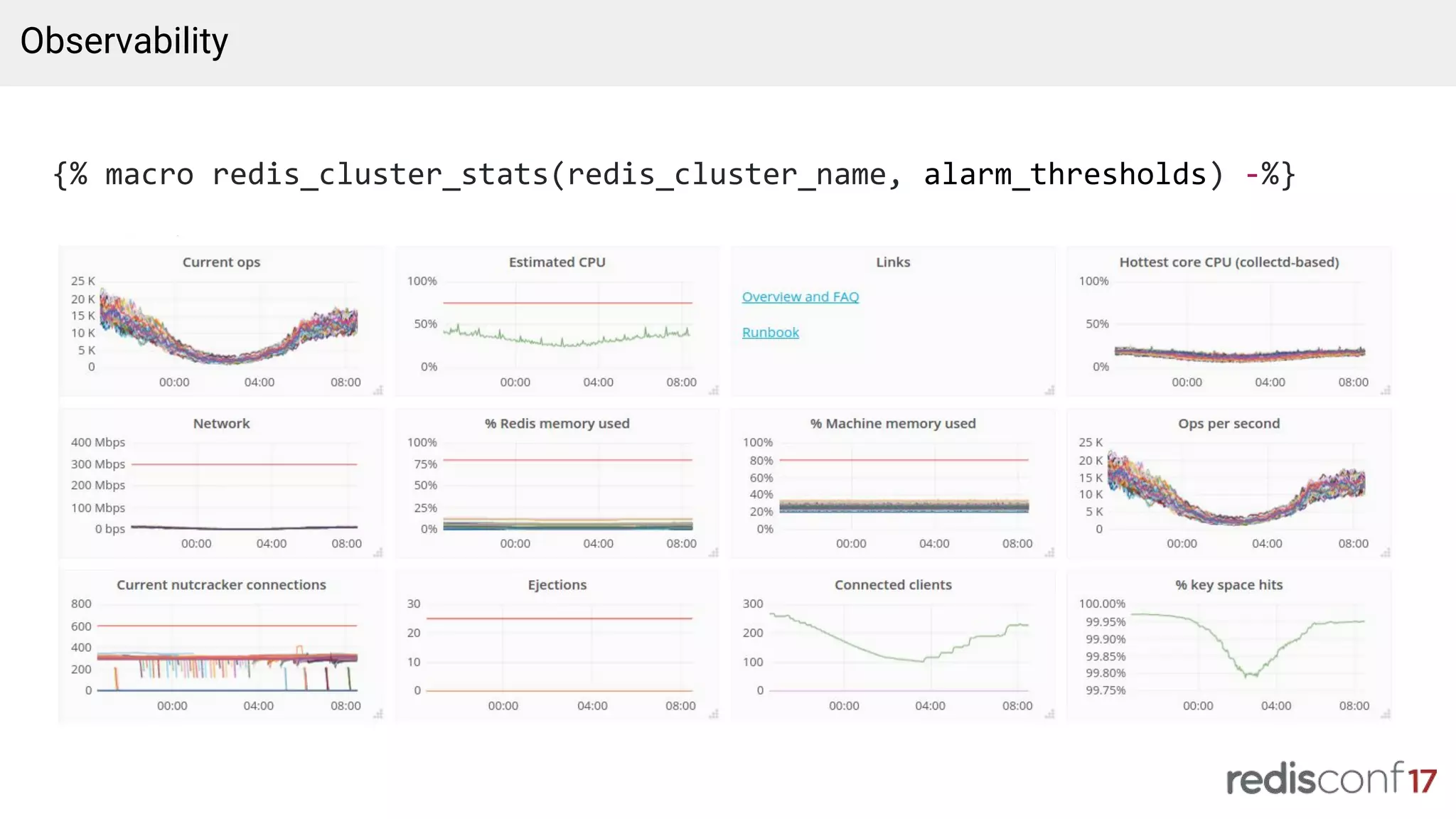
Insights on managing Redis clusters, supported languages, and internal libraries for enhanced performance.
Strategies for global capacity planning, resource tracking, and benefits of object serialization.
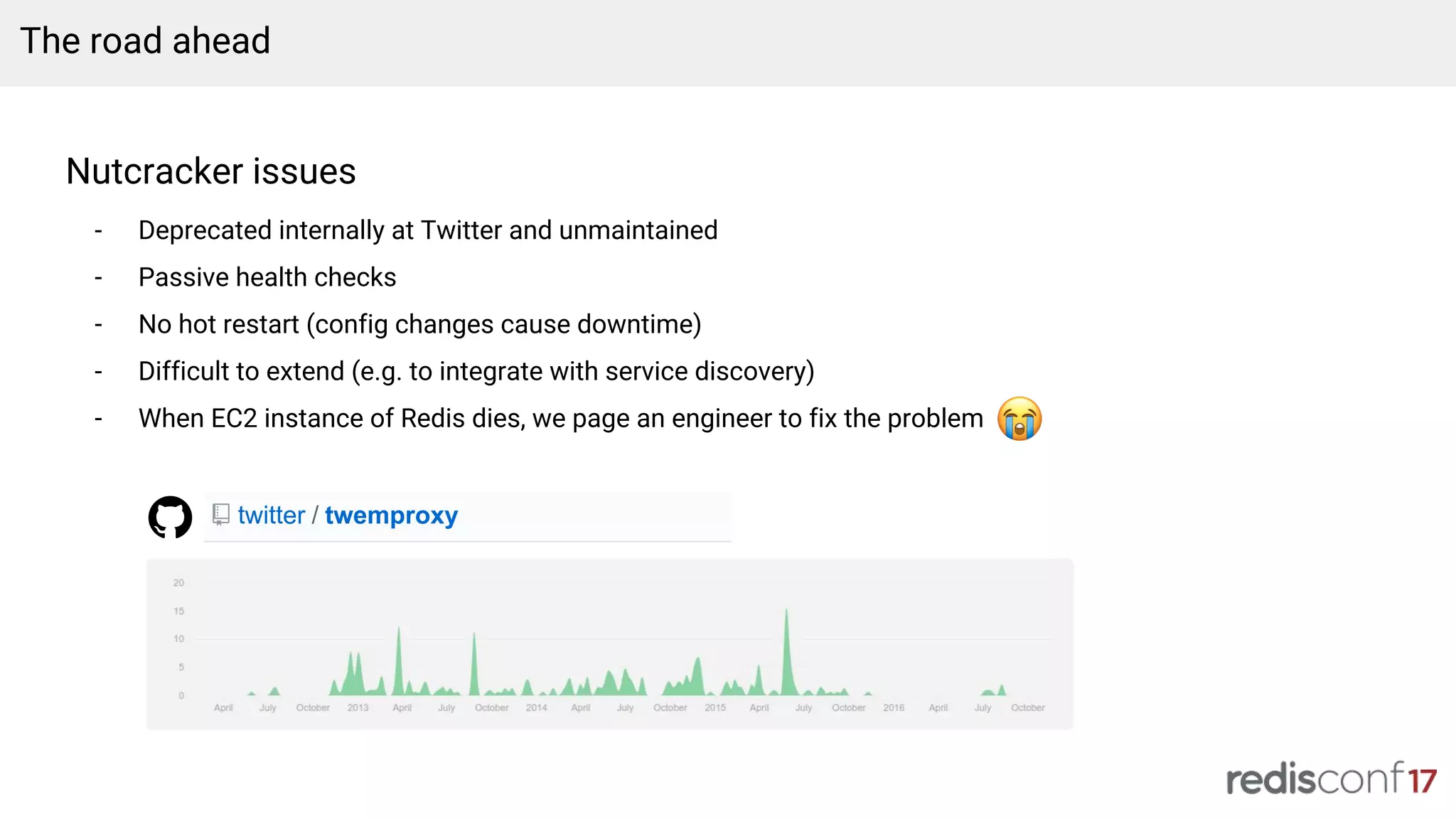
Challenges with existing Nutcracker use, introduction of Envoy for improved load balancing, and upcoming features.
Wrap-up of presentation with contact information and invitation for participation in open source.









![[pgday.Seoul 2022] PostgreSQL구조 - 윤성재](https://cdn.slidesharecdn.com/ss_thumbnails/pgday2022-postgresql-20221112-221114014106-bbfb1955-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Pgday.Seoul 2017] 8. PostgreSQL 10 새기능 소개 - 김상기](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-seoul-2017-pg10-new-features-171106041845-thumbnail.jpg?width=640&height=640&fit=bounds)




























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















