Downloaded 21 times


























![XADD key [MAXLEN ~ n] <ID | *>
<field> <string> [field string…]
> XADD mystream * foo bar baz qaz
1532556560197-42
Time complexity: O(log n)
See https://redis.io/commands/xadd
The Redis Stream Producer API](https://image.slidesharecdn.com/201810redistlvmeetup-v5streams-181028190617/85/Redis-v5-Streams-29-320.jpg)



![XLEN key - does exactly that, not very interesting.
X[REV]RANGE key <start | -> < end | +>
[COUNT count] - much more interesting :)
Get a single entry (start = end = ID)
SCAN-like iteration on a stream (IDs inc.), but better
Range (timeframe) queries on a stream
What's in the stream "API"](https://image.slidesharecdn.com/201810redistlvmeetup-v5streams-181028190617/85/Redis-v5-Streams-33-320.jpg)

![Yes. No. Maybe.
It can be used for consuming, but that requires the
client constantly polling the stream for new entries.
So generally, no. There's something better for
consumers.
Is X[REV]RANGE the Consumer API?](https://image.slidesharecdn.com/201810redistlvmeetup-v5streams-181028190617/85/Redis-v5-Streams-35-320.jpg)
![XREAD [COUNT count]
STREAMS key [key ...] ID [ID ...]
Somewhat like X[REV]RANGE, but:
● Supports multiple streams
● Easier to consume from an offset onwards
(compared to fetching ranges)
● But it is still polling, so...
The Redis Stream Consumer API](https://image.slidesharecdn.com/201810redistlvmeetup-v5streams-181028190617/85/Redis-v5-Streams-36-320.jpg)
![XREAD [COUNT count] [BLOCK ms]
STREAMS key [key ...] ID [ID ...]
● Like `BRPOP` (or `BZMINPOP` ;))
● Supports the special `$` ID, i.e. "new messages
since blockage"
● What about message delivery semantics?
The Redis Stream Consumer Blocking API](https://image.slidesharecdn.com/201810redistlvmeetup-v5streams-181028190617/85/Redis-v5-Streams-37-320.jpg)
![Like PubSub, it appears to "fire and forget", or
at-most-once delivery for efficient fan-out.
Contrastingly, messages in a stream are stored.
The consumer manages its last read ID, and can
resume from any point.
(And unlike blocking list (and zset :)) operations,
multiple consumers can consume the same stream)
XREAD [BLOCK] message delivery semantics …](https://image.slidesharecdn.com/201810redistlvmeetup-v5streams-181028190617/85/Redis-v5-Streams-38-320.jpg)



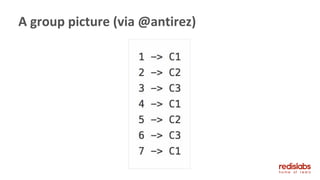

![XREADGROUP GROUP
<groupname> <consumername>
[COUNT count] [BLOCK ms]
STREAMS key [key ...] ID [ID ...]
● consumername is the member's ID
● groupname is the name of the group
● The special `>` ID means "new messages", any
other ID returns the consumer's history
Consumers Group API, #1](https://image.slidesharecdn.com/201810redistlvmeetup-v5streams-181028190617/85/Redis-v5-Streams-44-320.jpg)


![XACK <key> <group> <id> [<id> …]
Acknowledges the receipt of messages.
(that's at-least-once message delivery semantics)
Essentially removes them from the PEL.
Observation: consumername is not required, only
an ID, so anyone can `XACK` pending messages.
Consumers Group API, #3](https://image.slidesharecdn.com/201810redistlvmeetup-v5streams-181028190617/85/Redis-v5-Streams-47-320.jpg)
![XPENDING <key> <group>
[<start> <stop> <count>]
[<consumer>]
XCLAIM <key> <group> <consumer>
<min-idle-time>
<id> [<id> …] [MOAR]
CG introspection & handling consumer failures.
Consumers Group API, #4](https://image.slidesharecdn.com/201810redistlvmeetup-v5streams-181028190617/85/Redis-v5-Streams-48-320.jpg)
![XINFO <key>
XDEL <key> <id> [<id> …]
XTRIM <key> [MAXLEN [~] <n>]
Streams API, some loose ends](https://image.slidesharecdn.com/201810redistlvmeetup-v5streams-181028190617/85/Redis-v5-Streams-49-320.jpg)


The document details the features and functionalities introduced in Redis v5, which emphasizes the new Streams data structure and its capabilities for handling real-time data, particularly in distributed systems. It discusses the anatomy of streams, message delivery semantics, and the API for producers and consumers, including consumer groups for managing message processing. The document also highlights the problems with traditional methods and the necessity of streams in modern application architectures.
















































































